
Introduction
The Configuration Workbench handles all the key aspects of the index configuration needed in transforming the available content into objects for effective indexing.
An Indexing Pipeline is a series of indexing stages that prepares the content into a document compatible and ready for indexing. Each stage performs a specific set of transformations on the data before passing it onto the next stage in the pipeline.Each stage has a stage-specific configuration. Rearrange or sequence the stages in the order of your preferred flow by a simple drag and drop action.
For example, extract the entity values before processing trait properties or vice versa. SearchAssist allows you to develop a custom pipeline per each configuration in the Index Workbench to suit your business requirements.
An indexing stage has properties like stage type, stage name, and applicable conditions. Define the conditions to choose the documents that must be transformed. For example, you can write a condition to consider only the FAQs.
For best results click Train your App each time you make changes to any indexing configuration. This ensures the indexing based on the latest or updated configurations.
In case you want to test the Search Assistant for select stages only and not all, choose to render the other stages inactive with the toggle switch on the upper-right corner. This will retain those stages but at the same time, they won’t be considered in the indexing configuration. You can activate those inactivated stages at a later time as required.
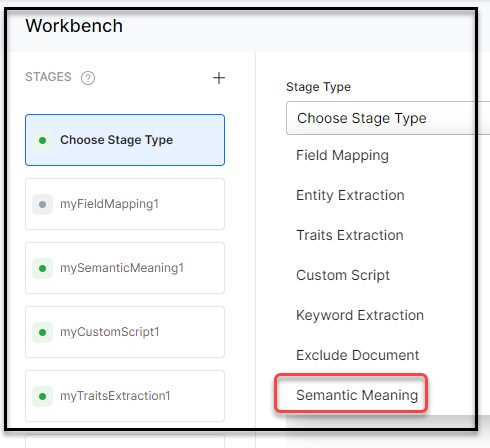
Indexing pipeline stages are listed here:
- The Field Mapping stage is used to map fields in an indexing pipeline document to a target field, set values, copy values, remove fields, and much more. Refer Mapping Fields in the Workbench
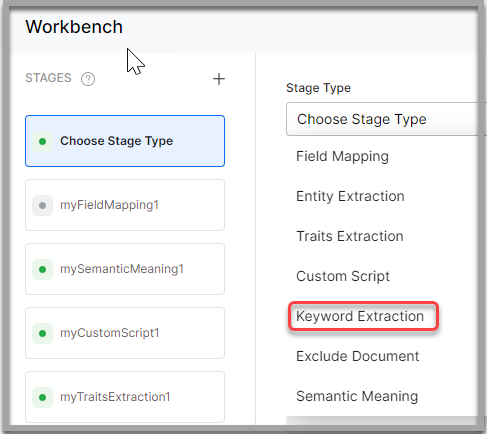
- Keyword Extraction is a technique to automatically detect important words from the text stored in a field. Refer Extracting Keywords
- Traits Extraction extracts specific attributes, or characteristics that the search users might express in their conversations. Refer Extracting Traits
- Entity Extraction uses NLP techniques to identify named entities from the source field. Refer Extracting Entities
- Semantic Meaning analysis is the technique to understand the meaning and interpretation of words, signs, and sentence structure. Refer Applying Semantic Meanings
Note: The feature of “Applying Semantic Meanings” currently supports only the Web page related sources.
- Custom Script stage allows you to enter customized scripts to perform any field mapping tasks like deleting or renaming fields. Refer Running Custom Scripts
Exclude Document stage drops all the documents that match the specified condition. Refer Excluding Documents from Scope
Mapping Fields in the Workbench
The Field Mapping stage in Indexing Pipeline is used to map fields in an index pipeline document to a target field.
SearchAssist allows you to:
- Set a field value, Rename a field, Copy one field to another, or Remove a field
- Define a condition for the field mapping stage. The field mapping actions occur on the documents that satisfy the given condition
- Re-order or delete a Field Mapping
- Simulate to test the changes before saving them
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.
![]()
To configure field mapping, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
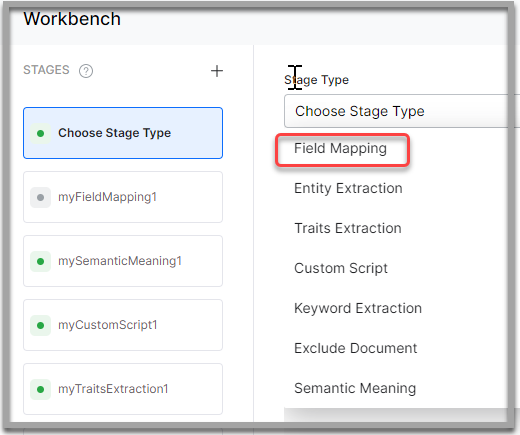
- On the Workbench page, on the Stages column, click the + icon.
- Select Field Mapping from the Stage Type dropdown.
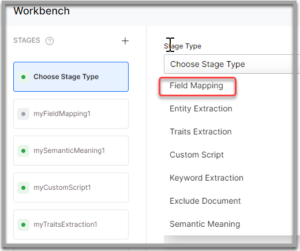
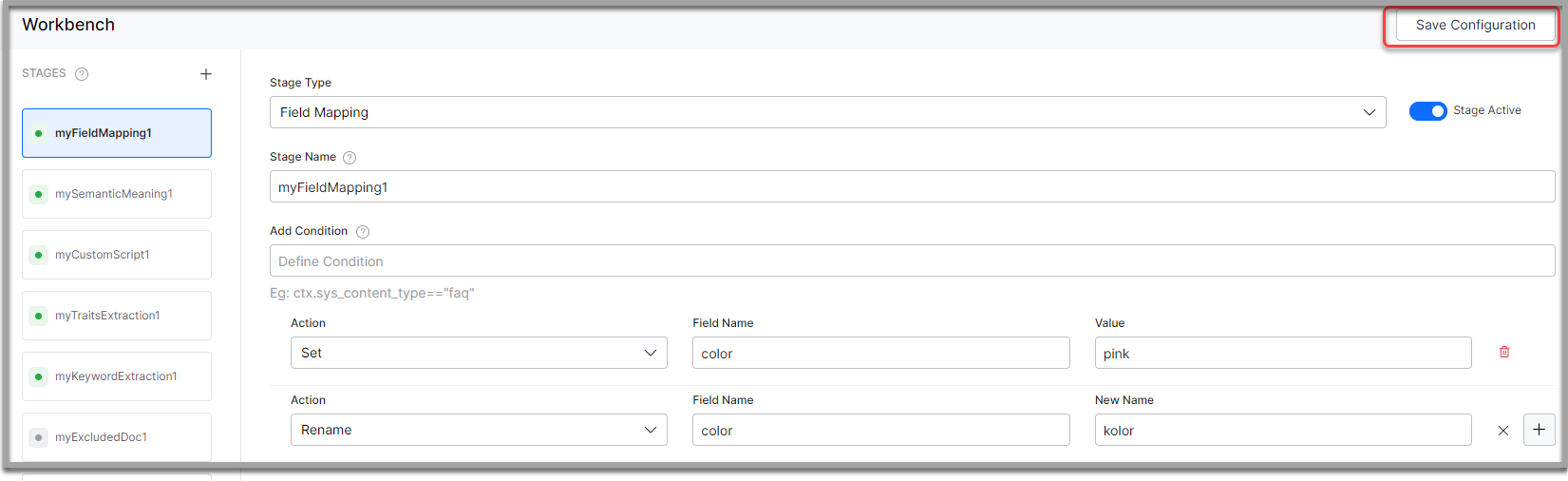
- Enter a name in the Stage Name field.
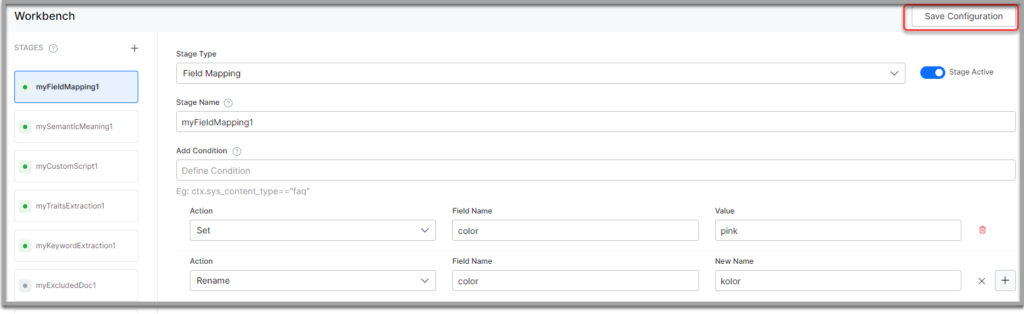
- Enter a condition in the Condition field. Add multiple conditions using AND/OR connectors. SearchAssist considers the documents that satisfy the conditions as part of the stage.
- Select an action from the Action dropdown. See the following details.
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention in the conditions.
- Once done, click Save Configuration on the top-right. For example, select Set from the Actions dropdown list; enter Title in the Field Name field and enter Heading in the Value field. Click Simulate to verify if the field value is changed. Perform associated Actions to:
- Set a Value for the Field Name
- Rename to a New Name for the Field Name
- Copy the Source Field to the Target Field
- Remove the Field Name
- Use the handlebar to reorder the action sequence as required.


Conditions for Mapping Fields
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value.
For example, ctx.contentType==”web” to restrict the mapping to content from a web source
Extracting Keywords
Keyword Extraction is a technique to automatically detect important and relevant words from the text stored in a field.
The Keyword Extraction stage in Indexing Pipeline to identify a set of keywords from a source field and save the identified keywords in a target field. Use the target field to identify the intention of the search user better.
SearchAssist applies various NLP algorithms to extract keywords.
SearchAssist allows you to:
- Define a condition for the keyword extraction stage. SearchAssist extract keywords only from the documents that satisfy the given condition
- Re-order or delete keyword extractions
- Simulate the changes before saving them
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.
![]()
To configure for keyword extraction, take the following steps:
- Click the Indices tab on the top
- On the left pane, under the Index Configuration section, click Workbench
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon
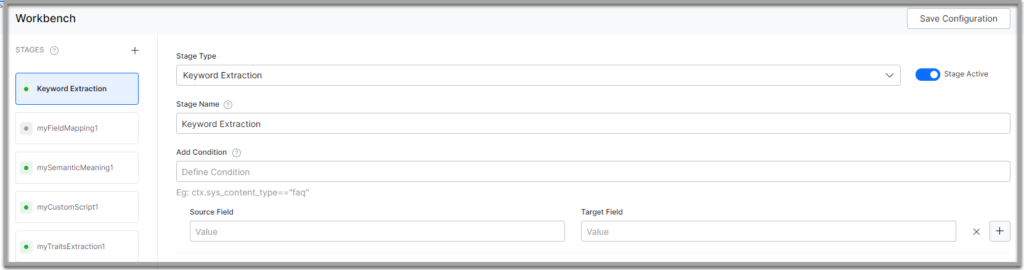
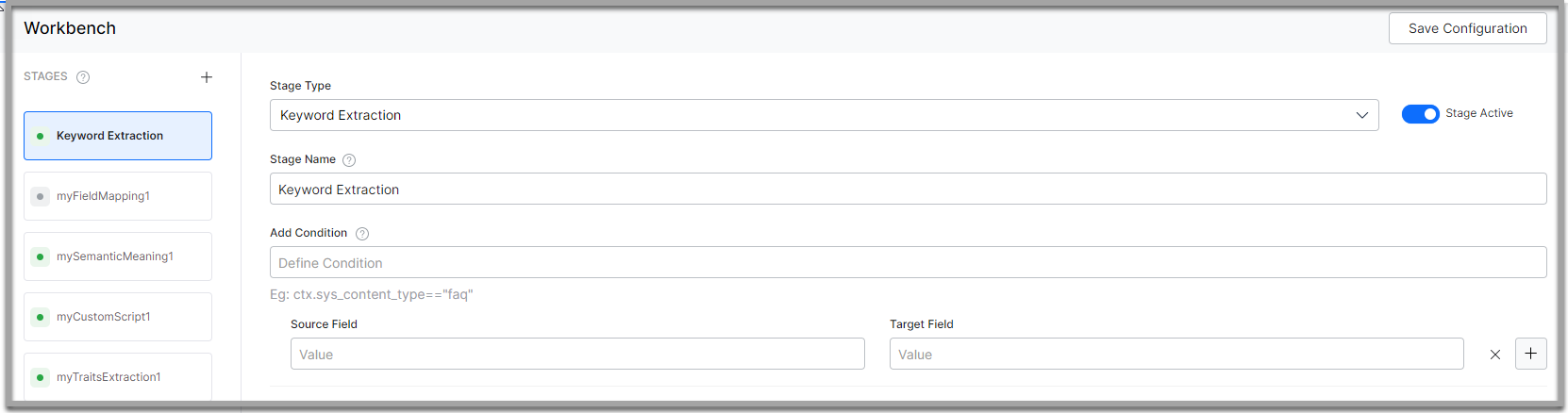
- Select Keyword Extraction from the Stage Type dropdown

- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. You can add multiple conditions using the AND/OR connectors. SearchAssist considers only the documents that satisfy the conditions part of the stage. Refer the following “Conditions for Keyword Extraction”.
- Select the field you want to extract keyword from as Source Field
- Name the Target Field where you want to store the extracted keywords. The Search Assistant creates this field.
The following models are supported:- Topic Rank – it’s a method to extract keyphrases from the most important topics of a document
- Position Rank – it’s a method to capture both highly frequent words or phrases and their position in a document
- Multi-partite Rank – it’s a keyphrase extraction method that encodes topical information within a multi-partite graph structure
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention in the conditions.
- Once ready, click Save Configuration on the upper-right.
Conditions for Keyword ExtractionCondition is of the following format: ctx.field_name==value or ctx.field_name!=value.
Obtain the field_name from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction from the content from a web source.
Extracting Traits
The Traits Extraction stage in Indexing Pipeline extracts specific or characteristic attributes, or details that the search users express in their conversations. SearchAssist allows you to identify trait characteristics from a source field and save the identified traits in a target field. The target field is used to detect user intentions better.
SearchAssist allows you to:
- Add multiple trait groups to be identified from the source field
- Define a condition for the trait extraction stage. SearchAssist extract traits only from the documents that satisfy the given conditions
- Re-order or delete trait extractions
- Simulate the changes before saving them
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.
![]()
Configuration: to configure for traits extraction, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon.
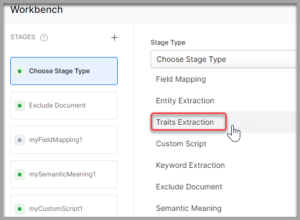
- Select Traits Extraction from the Stage Type dropdown.
- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. Add multiple conditions using the AND/OR connectors. SearchAssists considers only the documents that satisfy the conditions as part of the stage. See Conditions in Extraction.
- Select the field you want to extract traits from as Source Field.
- Name the Target Field where you want to store the extracted traits. The Search Assistant creates the target field.
- Enter trait groups in the Add Trait Groups field.
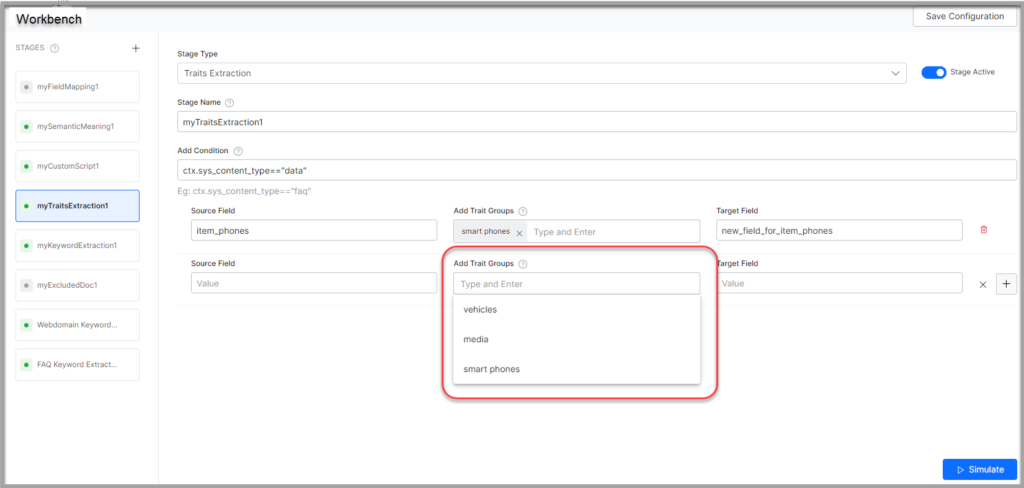
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention of it in the conditions.
- Once ready, click Save Configuration on the upper-right.

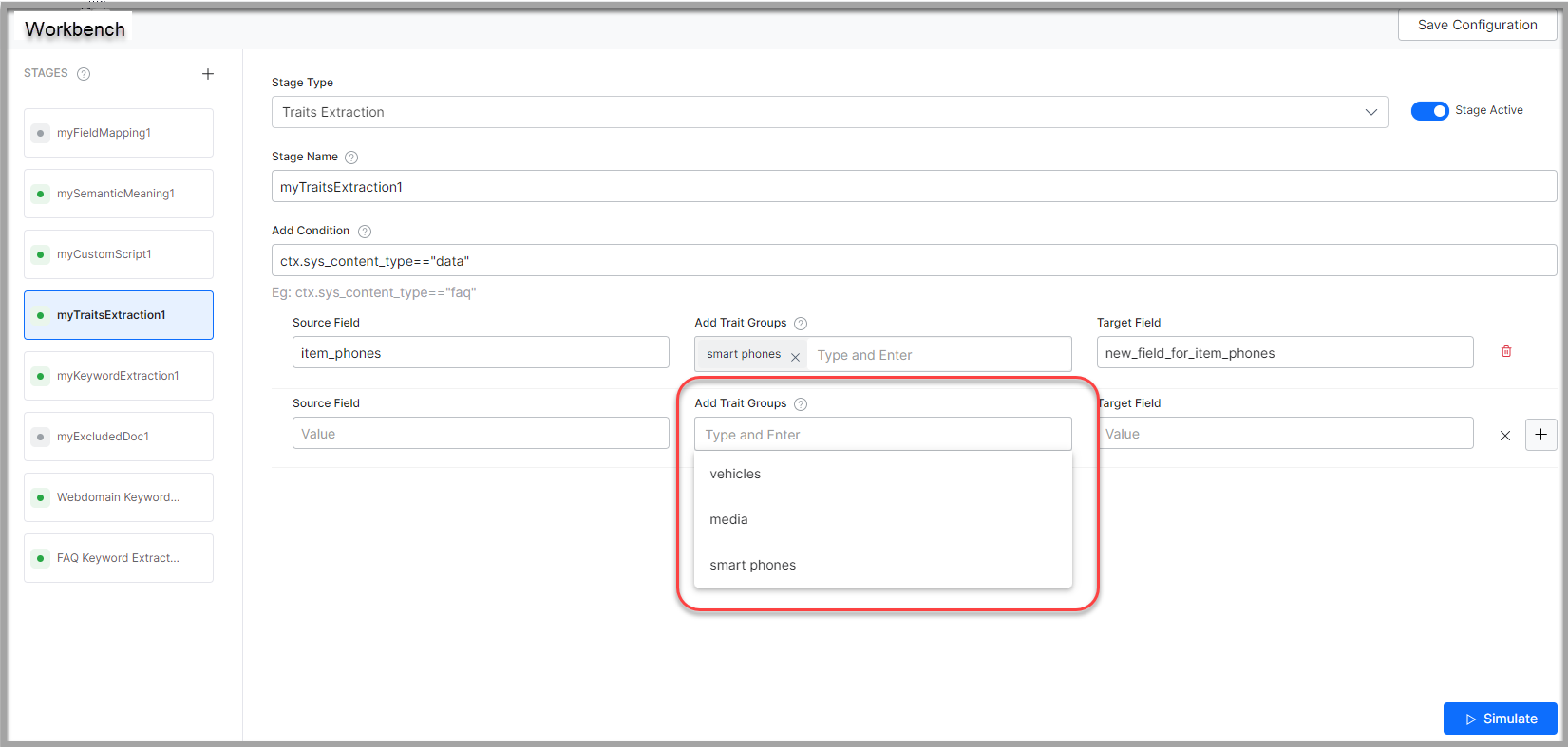
Conditions in Extracting Traits
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value. Obtain the field_name from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction to the content from a web source.
Extracting Entities
Entity Extraction refers to the required information expected from the user as input to accomplish the task. Search Assistant uses NLP techniques to find named entities from the source field.
The Entity Extraction stage in Indexing Pipeline is used to identify a set of entities from a source field and save the identified entities in a target field. SearchAssist uses the target field to identify the intention of the search user more accurately.
SearchAssist allows you to:
- Add multiple entities to be extracted from the source field
- Define a condition for the entity extraction stage and the entities are extracted only from the documents that satisfy the given condition
- Re-order or delete entity extraction rules
- Simulate the changes before saving them
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.
![]()
Configuration: to configure for entity extraction, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon.
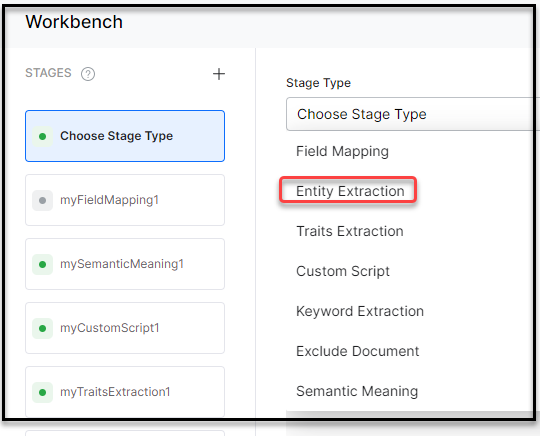
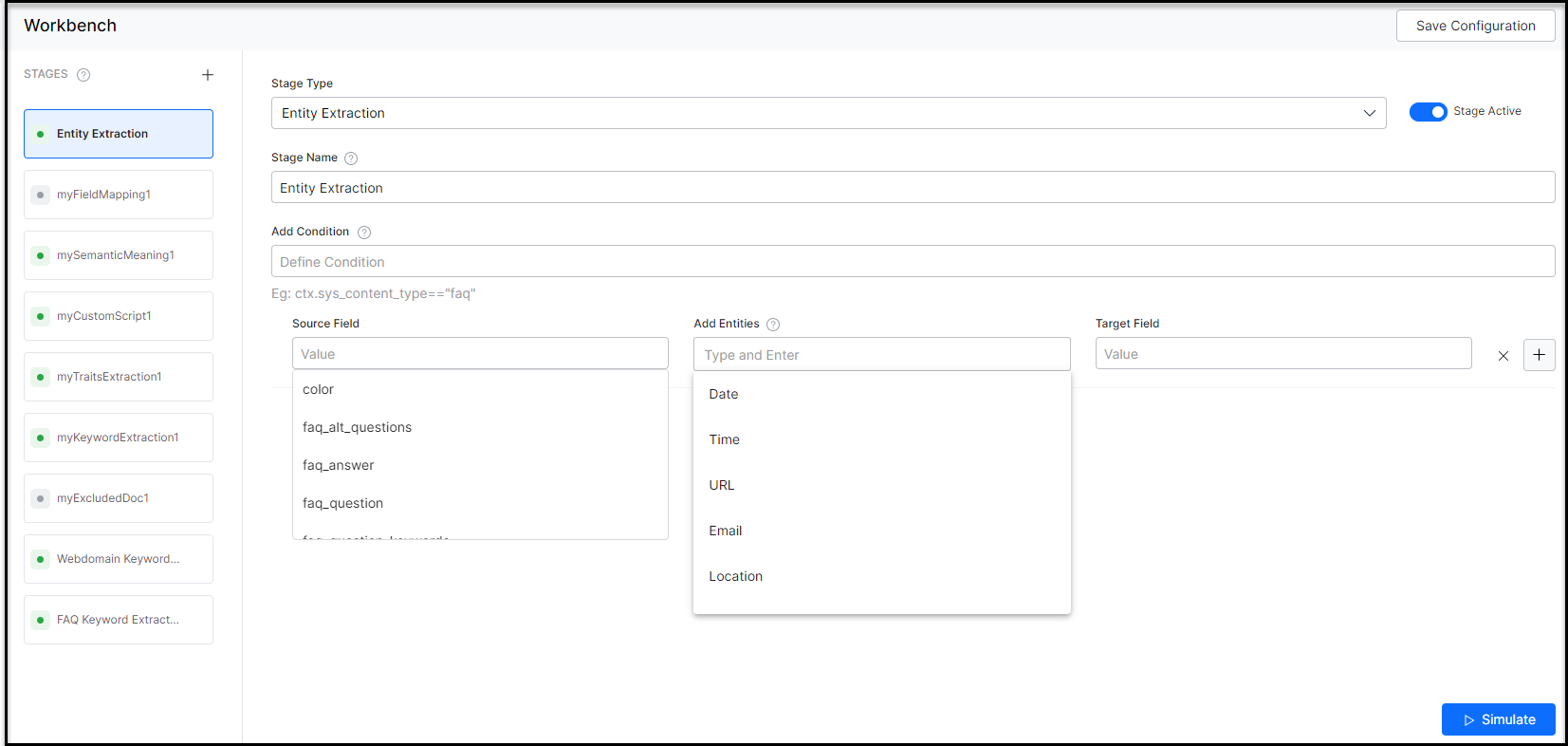
- Select Entity Extraction from the Stage Type dropdown.

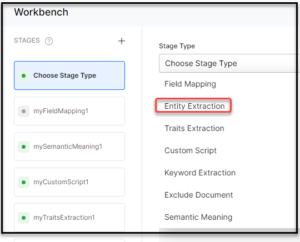
- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. You can add multiple conditions using the AND/OR connectors/extensions. SearchAssists considers only the documents that satisfy the conditions as part of the stage. See the following details.
- Select the field you want to extract the entity from as Source Field.
- Name the Target Field where you want to store the extracted entity. The Search Assistant creates the target field.
- Select an entity from the Add Entities field. These are the entity types that need to be identified from the source field. The supported entities are Date, Time, Date-Time, Date Period, URL, Email, Location, City, Country, Color, Company Name, Currency, Person Name, Number, Percentage, Phone Number, Zip Code, Quantity, Address, and Airport.
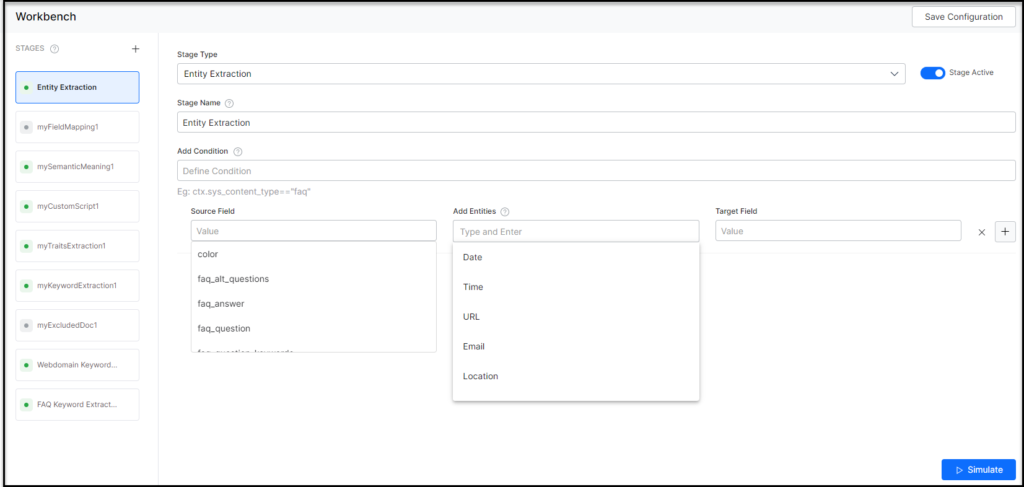
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention of it in the conditions.
- Once ready, click Save Configuration on the upper-right.
Conditions to Extract Entities
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value. Obtain the field_name from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction to the content from a web source.
Applying Semantic Meanings
Semantic analysis is the technique to understand the meaning and interpretation of words, signs, and sentence structure.
SearchAssist’s Indexing Pipeline supports a Semantic Meaning stage. This stage uses Deep Neural Network algorithms to create inserts of free text and saves them in a dense vector field. SearchAssist uses these embeddings to rank the documents by semantic relevance. The dense vectors are then indexed in the search and similarity is obtained between the user’s query vector and the indexed content vector.
Currently you can apply semantic meanings only on content from websites. When SearchAssist semantically interprets the source from a natural language perspective, the relevant results get priority over others.
SearchAssist allows you to:
- Add multiple semantics to be analyzed from the source field
- Define a condition for the semantic meaning stage. The semantics from only the documents that satisfy the given condition would be analyzed
- Re-order or delete semantic meaning rules
- Simulate the changes before saving them
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.![]()
Configuration: to configure for applying semantic meaning, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
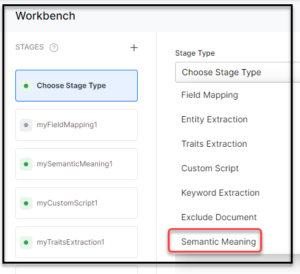
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon.
- Select Semantic Meaning from the Stage Type dropdown list.
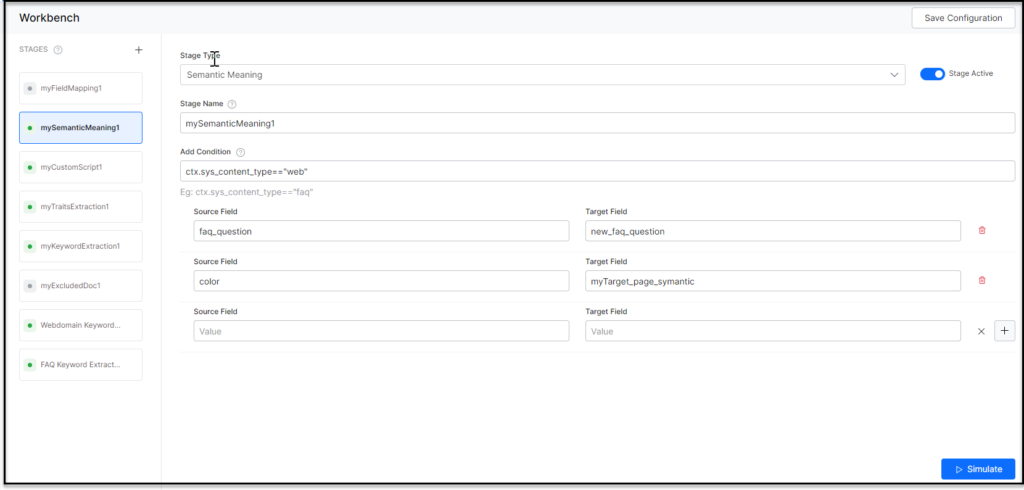
- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. You can add multiple conditions using the AND/OR connectors. SearchAssists considers only the documents that satisfy the conditions as part of the stage. Refer the following “Conditions for Applying Semantic Meanings”.
- Select the field you want to extract Semantic Meaning from as Source Field.
- Define where you want to store the extracted Semantic Meaning as Target Field. The Search Assistant creates this Target Field.
- Choose a model from the Choose Model dropdown list.
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source if there is no mention in the condition and the number of documents.
- Once ready, click Save Configuration on the upper-right.

Supported Models in Semantic Analysis: the following models are supported
- Universal Sentence Encoder – It encodes text into high-dimensional vectors that are used for semantic similarity
- Sentence Transformers – it’s a framework for sentence and text embeddings
- InferSent – it’s a sentence embedding method that provides semantic sentence representations
Conditions for Semantic Analysis
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value. The field_name can be obtained from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction to the content from a web source.
Running Custom Scripts
The Custom Script stage in Indexing Pipeline allows code custom processing. You can write a painless script to perform actions such as adding a new field, deleting a field, setting/resetting values to a field, copying fields, etc.
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.
Configuration: to configure a custom script, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
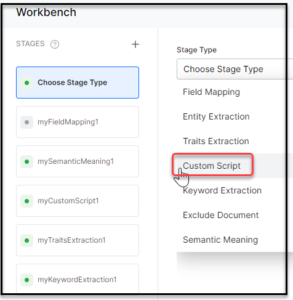
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon.
- Select Custom Script from the Stage Type dropdown list.
- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. Add multiple conditions using the AND/OR connectors. SearchAssist execudes documents that satisfy the condition(s). Refer the following “Conditions for Running Scripts”.
- Under the </>Painless section, enter the custom script. See the following details.
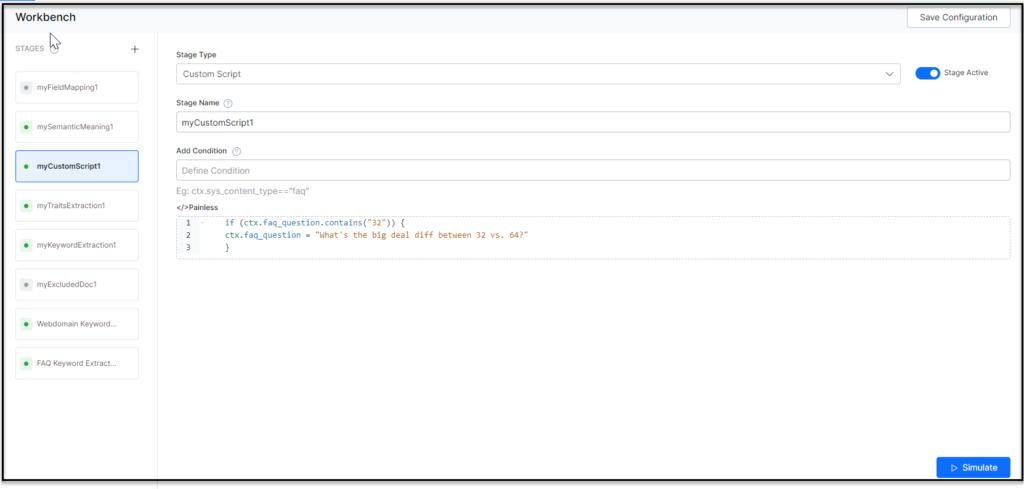
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention of it in the conditions.
- Once ready, click Save Configuration on the upper-right.

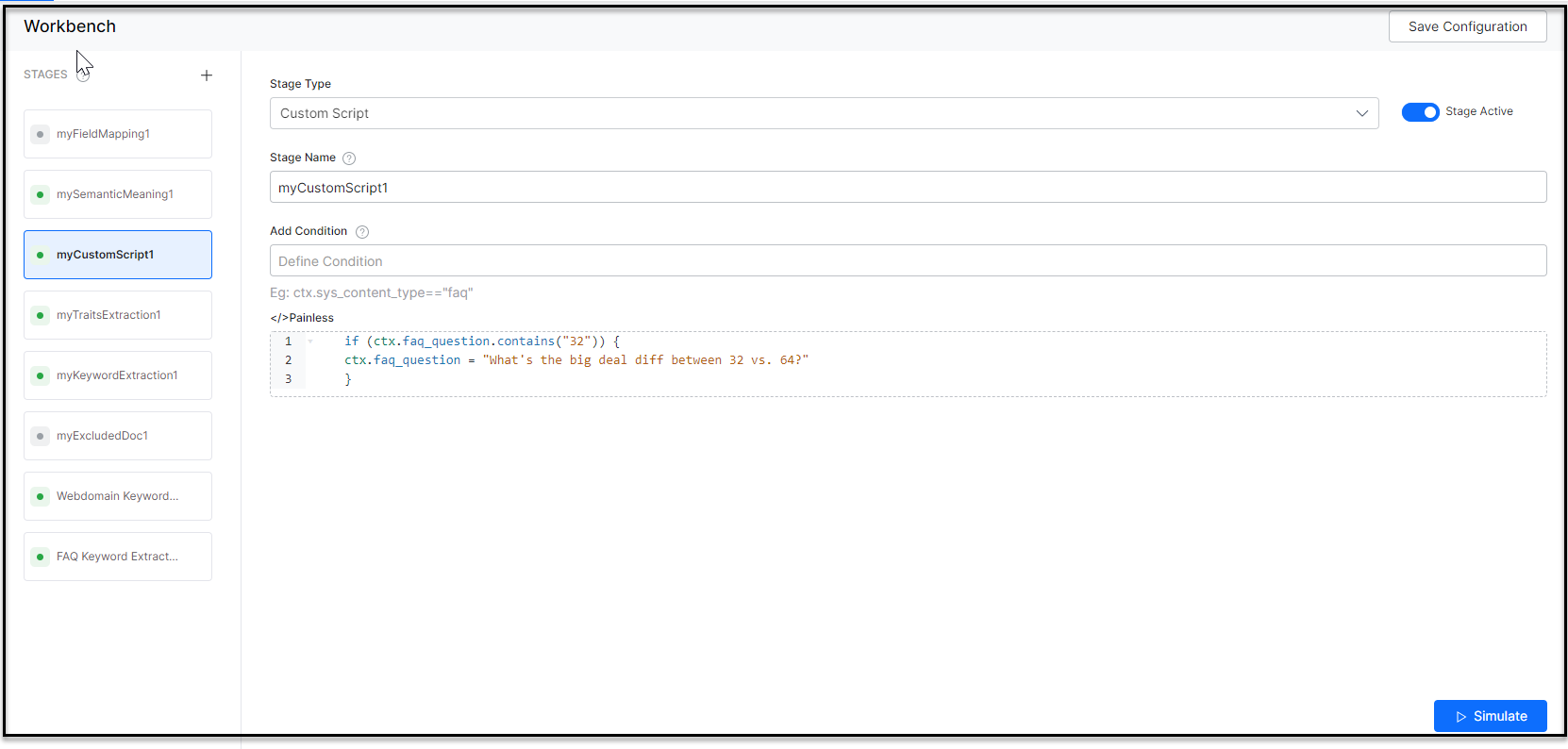
Script Example: to copy a value from “defaultAnswers[*].payload” to “answer[]”, use the following script:
ctx.answer =[]; for (def item : ctx.defaultAnswers) { ctx.answer.add(item.payload) }
Conditions for Running Scripts
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value. The field_name can be obtained from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction to the content from a web source.
Excluding Documents from Scope
The Exclude Document stage in Indexing Pipeline allows you to drop all the documents that match the specified conditions. SearchAssist ignores documents in the subsequent stages of the indexing pipeline and leaves them without indexing.
Ensure to click Train your App each time you make changes to any index configuration. This builds the index based on the updated configurations.![]()
To configure a exclude document stage, take the following steps:
- Click the Indices tab on the top.
- On the left pane, under the Index Configuration section, click Workbench.
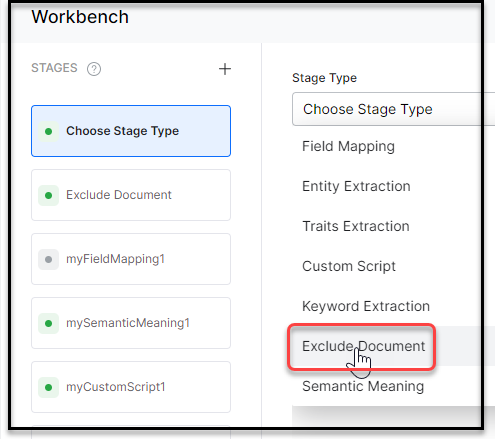
- On the Workbench (Index Configuration) page, on the Stages column, click the + icon.
- Select Exclude Document from the Stage Type dropdown list.
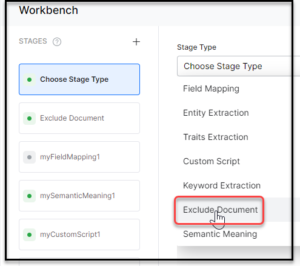
- Enter a name in the Stage Name field.
- Enter a condition in the Condition field. Add multiple conditions using the AND/OR connectors. SearchAssist excludes the documents that contain the field mentioned in the conditions as part of the stage. See the following “Conditions for Excluding Docs”.
NOTE: It’s mandatory to add conditions for defining the Exclude Document stage.
- Click Simulate to verify the configurations. The simulator displays the Source and the number of documents to which the mapping was applied, and the result. You can change the Source and the number of documents if there is no mention of it in the conditions.
- Once ready, click Save Configuration on the upper-right.

Conditions for Excluding Docs:
Condition is of the following format: ctx.fieldtype==value or ctx.fieldtype!=value. i.e., the condition can be a certain field type equals a certain value or not equal to a certain value.
value here being file types: FAQs, web
The field_name can be obtained from the Fields table under Index Configuration.
For example, ctx.contentType==”web” to restrict the extraction to the content from a web source.