
Introduction
Organizations usually have web pages with content that lists their offerings such as product information or process knowledge which a user can query. As a business user you can leverage this content by mapping Search Assistant to it, and process it to be available for user queries.
SearchAssist enables you to ingest content into your Search Assistant through web crawling. For example, consider a banking website. It has ready information to answer most of the search user queries. In this scenario, the Search Assistant is configured to crawl the bank’s website and index all the web pages so that the indexed pages are retrieved to answer the search users’ queries.
SearchAssist allows you to schedule automated web crawling sessions of target URLs at required frequency or a desired time window.
Adding Content by Web Crawling
To crawl web domains, take the following steps:
- Log in to the application with valid credentials
- Click the Indices tab on the top
- On the left pane, under the Sources section, click Content
- In the +Add Content dropdown, click Crawl Web Domain
- On the Crawl Web Domain dialog box, enter the domain URL in the Source URL field
- Enter a name in the Source Title field and a description in the Description field

- To schedule frequent web crawls, under the Schedule section, turn the toggle on
- Set the Start Date and Time, and Frequency at which the crawl needs to be scheduled
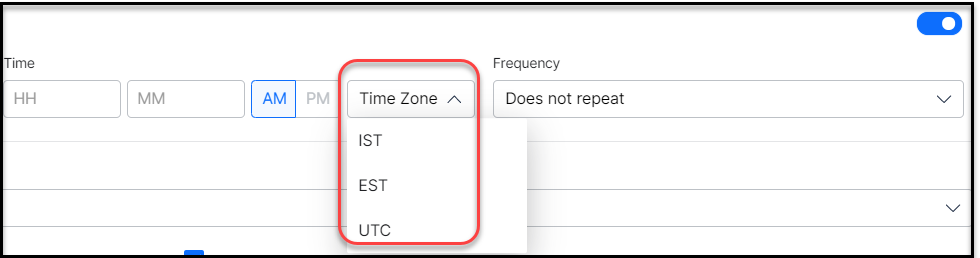
- Select the Time zone from the drop down. SearchAssist currently supports only 3 time zones IST, EST, and UTC
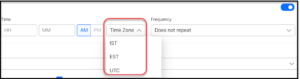
- Select the Time zone from the drop down. SearchAssist currently supports only 3 time zones IST, EST, and UTC
-
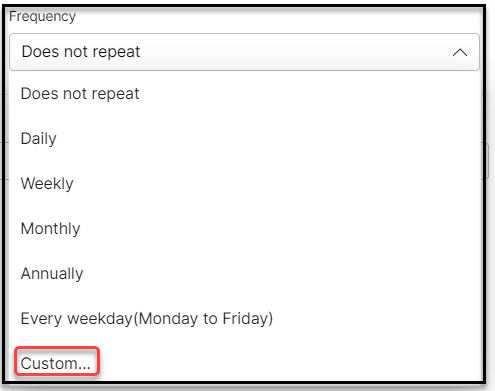
- From the Frequency dropdown either select a one time that Does not repeat, or select Daily, Weekly, Monthly, Annually or a Custom Recurrence for the Crawling to be triggered and the specific time selected in the previous steps
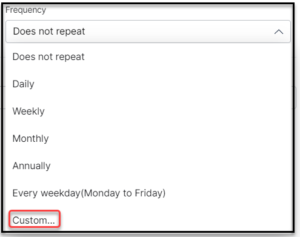
- From the Frequency dropdown either select a one time that Does not repeat, or select Daily, Weekly, Monthly, Annually or a Custom Recurrence for the Crawling to be triggered and the specific time selected in the previous steps
-
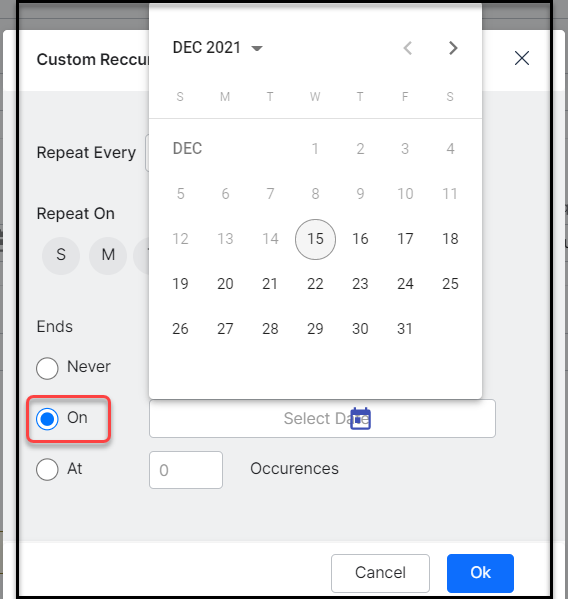
- To finetune the custom frequency more precisely use the Custom Recurrence that allows you to set frequency to Repeat Every certain number of times, say every Day, Week, or Month or Year, to Repeat On certain days of the week without giving it a miss

- Choose to apply the custom recurrence either for an
- indefinite period to never end or for a time span to:
- end On a certain date to be selected from the date selector, or
- end At (after) a certain number of Occurrences you enter in the numbers field next to it
- indefinite period to never end or for a time span to:
- Choose to apply the custom recurrence either for an
- To finetune the custom frequency more precisely use the Custom Recurrence that allows you to set frequency to Repeat Every certain number of times, say every Day, Week, or Month or Year, to Repeat On certain days of the week without giving it a miss
- In the Crawl Options list, select an option from the dropdown list:
- Crawl Everything – To enable crawling all the URLs that belong to the web domain
- Crawl Everything Except Specific URLs – To list down the URLs within the web domain that you want to ignore from crawling
- Crawl Only Specific URLs – To list down only the URLs that you want to crawl from the web domain
- Apply Crawl Settings as per your requirements:
- Select Javascript-rendered to allow crawling of websites with content rendered through JS code
 Note: In cases where the target website has javascript enabled pages, those pages to be considered for crawling. If unchecked they will be ignored.
Note: In cases where the target website has javascript enabled pages, those pages to be considered for crawling. If unchecked they will be ignored.
- Select Javascript-rendered to allow crawling of websites with content rendered through JS code
-
- Crawl Beyond Sitemap – Within the given domain selecting this feature allows crawling the web pages above and beyond the URLs that are provided in the sitemap file of the target website. To restrict the crawling limited to site map unselect Crawl Beyond Sitemap
- Use Cookies – allow crawling the web pages that require cookie acceptance. Unselect to ignore web pages that require Cookie Acceptance
- Respect robots.txt – to honor any directives from the robots.txt file for the web domain
- Depth of Crawling: The homepage at the top of the site page hierarchy, and inner pages linked from it in the lower levels, then the crawl depth specifies how deep into those nested levels the crawler will reach
- Scope of Crawling: 1 to maximum number of URLs allowed to be Crawled
- Crawl Depth – The maximum depth allowed to crawl any site can be specified, the value 0 indicates no limit
- Max URL Limit – The maximum number of URLs to be crawled can be specified, the value 0 indicates no limit
- Click Proceed
Errors in Adding Content by Web-Crawling
- Web Crawling feature can fail in two stages:
- Fails to start due to URL validation failure either due to connectivity issues or a misspelt URL, click Retry or Edit Configuration to Edit URL

- Fails after starting successful URL Validation for the given website and during web crawling.

Note: If you are attempting to crawl the same site without enabling automatic Frequent Scheduling toggle, a Duplication warning message pops up, reading “Web crawling cannot be duplicated” instead try using the Crawl by schedule.
- Fails to start due to URL validation failure either due to connectivity issues or a misspelt URL, click Retry or Edit Configuration to Edit URL