SearchAssist enables you to extract FAQs either from Files or from URL.
To extract FAQs from files you have to annotate the uploaded file i.e., mark the various sections in the file uploaded for SearchAssist to identify and save as FAQs.
Supported File Formats
The FAQ Extract and Import features support extracting FAQs only from the following:
- JSON, CSV, PDF file formats and
- Webpages
Comma-Separated Value (CSV)
- The imported FAQs interpret the text in the first column as a question and that in the second column as an answer
- The file must not have any headers
- Any headers and the text present in the other columns are ignored
Portable Document Format (PDF)
- The Extracted FAQs from PDF files processes the content from a PDF and converts it into question-answer pairs
- Documents with the table of contents: Ideally a document with a table of contents is preferred. In such cases, the table of contents is extracted first and then used to parse the document and identify headings. The information present in the table of contents is used to derive the hierarchy of headings (headings, subheadings, nested sub headings, etc.). These levels are separated by a vertical line as a delimiter (heading | subheading | sub-sub heading) as part of the extraction process
- Documents with no table of contents: In such cases, a pre-trained machine learning model is applied that identifies headings based on either font style or font size. In the case of using font size, the heading hierarchy can also be derived
- The text is then formatted with a uniform header and paragraph blocks
Web Pages
The Extract FAQs supports the following three different FAQ web pages:
- Plain FAQ pages with linear question-answer pairs
- Pages with question
- hyperlinks that point to answers on the same page
- Pages with question hyperlinks that point to answers on a different page
Extraction of certain FAQs on the webpage fails under the following conditions:
- The question text is split between multiple HTML tags on the FAQ page
- The tag applied to the answer is neither the child nor the sibling of the extracted question as per the HTML DOM structure
- The question does not have a hyperlink to the answer (applies to FAQs with hyperlinks)
- When the questions hyperlink to the answer, but the question statement is not repeated above the answer (applies to FAQs with hyperlinks)
The extraction of the entire FAQ page fails if the page consists of more than one FAQ page type mentioned previously.
You can review the extracted FAQs in the Review workflow to edit, enhance FAQs and their answers.
Extracting FAQs from Files
Use the Extract FAQs option to extract all the FAQs that are listed in a PDF file or in web pages.
To add FAQs through the Extract FAQs option, take the following steps:
- On the Sources page, click FAQs on the left pane.
- On the FAQs page, click the +Add FAQ and select Extract FAQs.

- In the Extract FAQs dialog box, enter a name in the Source Title field and a description in the Description field.
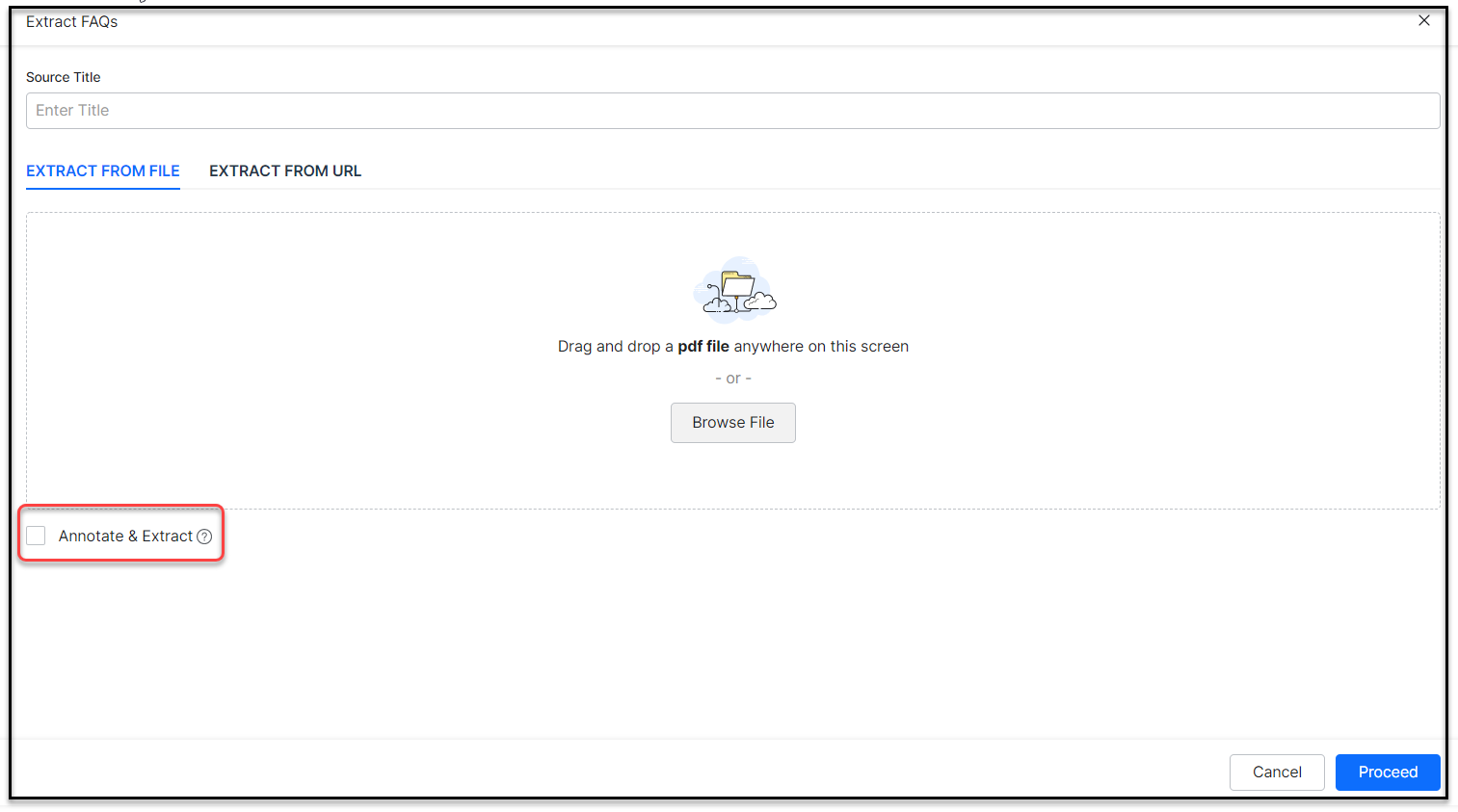
- Extract FAQs from a file: For file extraction – from the Extract from File section, drag and drop a file or click Browse to locate the PDF file.
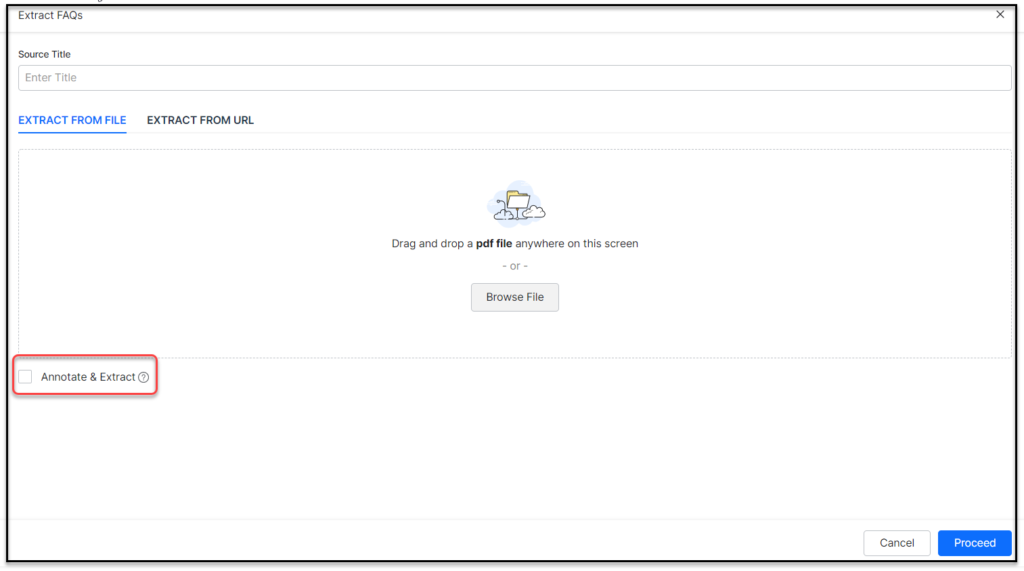
- For the Extract from File option, Annotate and Extract the uploaded file to identify and include only the FAQs in that file. Refer Annotating & Extracting FAQs from documents

In the Extract FAQs dialog box, find the extraction status. If required, cancel the extraction or click OK after the extraction is complete.
Annotating to Extract FAQs
You may have all the FAQs related to your business in a PDF file but not in the format mandated by SearchAssist. Annotate such documents identifying the key sections of the content from a few pages of the document. SearchAssist uses this identified pattern from annotation to extract the FAQs from the document.
Note: This feature is applicable only when extracting FAQs from PDF documents.
- Select a PDF file for extraction.
- Select the Annotate & Extract option. Click Proceed.
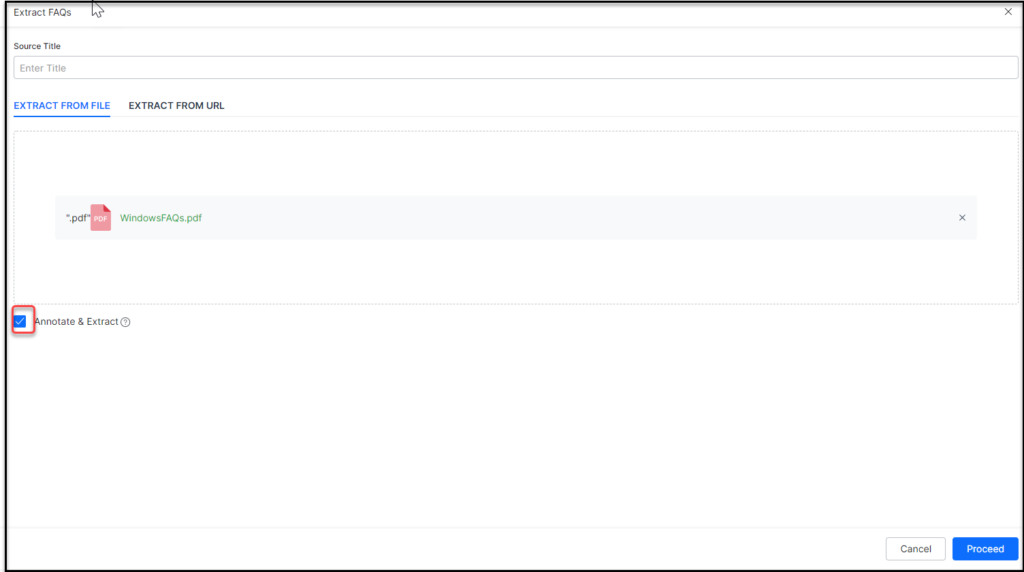
- The PDF document is loaded into the Annotation Tool allowing you to annotate the various sections in the document.
- To annotate, select the text and tag it as follows:
- Heading: Apply Heading tag to train the Search Assistant so that it can identify the question. The content between any two consecutive headings is extracted as the answer for the preceding heading.
- Header: Avoid random marking of texts as headers. Marking text such as a footer or paragraphs as the header produces invalid results.
- Footer: Apply Footer tag to train the Search Assistant so that it can identify and ignore the footers. Avoid random marking of texts as footers. Marking text such as a header or paragraphs as the footer produces invalid results.
- Exclude: Apply Exclude tag to prevent the extraction of that section.
- Ignore Page: Apply Ignore page tag to pages to be excluded from extraction.
- Remove Annotation: Apply this feature to undo any incorrect annotations and to start annotating afresh.
- The Search Assistant uses the headings, headers, and footers in the extraction process and can learn from it. You need not annotate the entire document. Annotate a couple of pages with headings, headers, and footers, extract and review the questions.
- The feature generates Additional document information:
- Document Info includes Name, Size, and the Number of Pages of the document.
- Annotation Summary includes Number of annotations marked for each category for the particular page and the entire document.
- After you annotate, click Extract to apply the annotation to the entire document and extract FAQs from it in bulk.
- The extracted FAQs are listed under Drafts and mark the beginning of the FAQ review workflow. Refer FAQ Review Workflow.

Extracting FAQs from URL
Use The Extract FAQs option to extract all the FAQs that are available in a web page.
To add FAQs through the Extract FAQs option, take the following steps:
- On the Sources tab, click FAQs on the left pane.
- On the FAQs page, click the Add FAQ and select Extract FAQs.
- In the Extract FAQs dialog box, enter a name in the Source Title field and a description in the Description field.
- To extract FAQs from a web page click Extract from URL tab. Enter the URL of the FAQ page or domain URL in the Enter URL field.
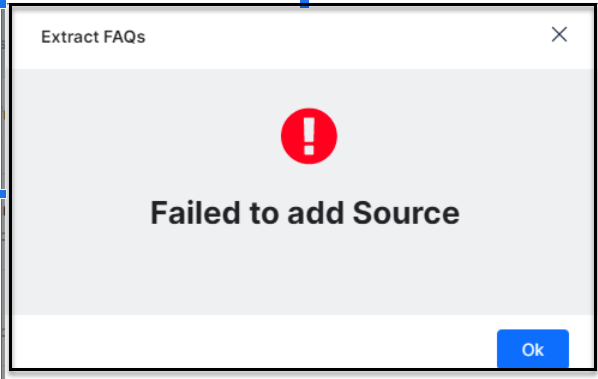
Note: When you are trying to extract FAQs from a misspelled or wrong URL that is a non-existent, the following error message pops up: