Botのトレーニングは、機械学習やファンダメンタルミーニングのエンジンに限定されるものではありません。ナレッジグラフエンジンもトレーニングする必要があります。
ナレッジグラフエンジンは、ナレッジグラフから適切な質問を特定することで、ユーザーインテントに応答します。
ナレッジグラフ
ナレッジグラフから、以下の手順に従って対応するナレッジグラフを構築およびトレーニングします。
- それぞれのFAQの質問に含まれるユニークな単語をグループ化して用語を特定します。これらすべてのユニークな単語に基づいて階層を構築します。
- それぞれのノードの質問数は、25問を超えないようにします。
- 特性を用語に関連付け、検出された複数の結果からFAQをフィルタリングできるようにします。
- 階層内のそれぞれの用語/ノードの同義語を定義します。用語を呼び出すためのすべての方法が定義されていることを確認します。
- パス内のそれぞれの用語の重要度に応じて、それらの用語を必須または通常の用語としてマークします。
- 可能な限りカバーできるよう、それぞれのFAQの代替質問を定義します。
- 正確な応答ができるようコンテキストを管理します。
- ストップワードは、不要な発話をフィルタリングするために使用することができます。
ナレッジグラフのトレーニングやテストは、効率的なナレッジグラフを構築するのに不可欠です。
トレーニングの前に、タグ、同義語、特性を使用してパフォーマンスを向上させることができます。
用語のタイプ
(バージョン7.2以前は、「使用法の管理」の「用語の使用法」と呼ばれていました)
一致するパスを指定する際の重要性に応じて、デフォルト、必須、オーガナイザーとしてナレッジグラフの用語とタグを指定します。
- デフォルト:デフォルトの用語は、適格なパスの候補選択において特に考慮すべき点はありません。
- 必須:用語を必須としてマークすると、ユーザーの発話に必須の用語またはその同義語が含まれている場合にのみ、その用語に関連付けられているすべてのパスがランキング用に絞り込まれます。
- オーガナイザー:用語は、質問を整理するためにのみ、ナレッジグラフの一部としてマークすることができます(このオプションはタグではなく用語に対してのみ利用可能です)。
タグ
ユーザーの発言フィールドに質問が入力されると、ナレッジグラフは、テキストに基づいてグラフに追加可能なタグを提案します。提案された用語をパスに追加するには、カーソルが用語の追加フィールドにあるときに表示されるドロップダウンリストからタグを選択します。また、用語の追加フィールドにタグを入力してエンターキーを押すことで、カスタムタグを追加することもできます。
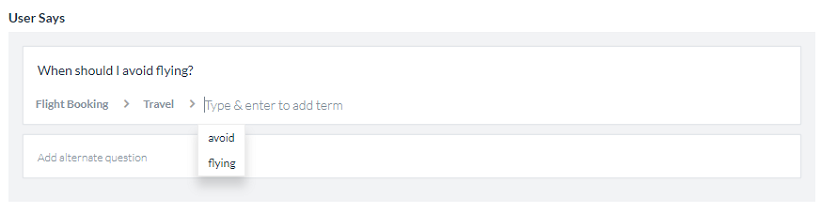
タグを追加すると、質問が表示される場所すべてで、質問の下にタグのように表示されるようになります。タグは用語とまったく同じように機能しますが、ナレッジグラフには表示されません。用語と同様に、タグにも同義語や特性を追加することができます。
同義語
ナレッジグラフにそれぞれの用語に対する複数の同義語を追加することができ、これによりさまざまなユーザーの発話に対してパスを検出できるようになります。用語の同義語は設定ウィンドウから追加することができます。
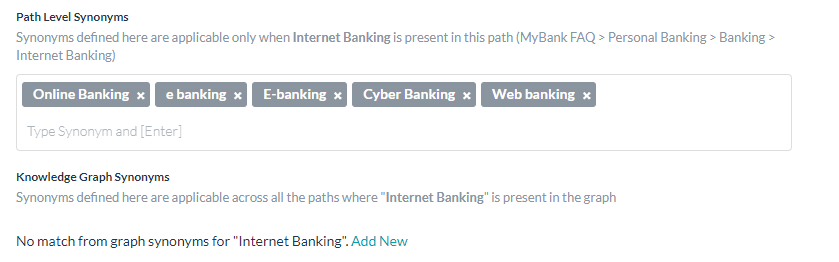
ナレッジグラフに用語の同義語を追加すると、ローカル(パスレベル)またはグローバル(ナレッジグラフ)の同義語として追加することができます。
ローカルの同義語は、特定のパスでのみその用語に適用され、グローバルの同義語は、階層内の他のパスに現れた場合でもその用語に適用されます。
用語の同義語を追加する:
- Botのナレッジグラフの左上で、同義語を追加したいノード/用語にカーソルを合わせます。
- ギアアイコンをクリックして設定ウィンドウを開きます。
- 同義語を追加するには、以下を実行します。
- ローカルの同義語を追加するには、パスレベルの同義語のボックスに入力します。
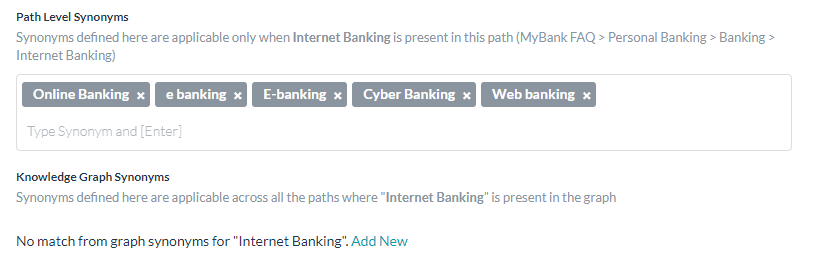
- グローバルの同義語を追加するには、ナレッジグラフの同義語の編集または新規追加をクリックして入力します。これらのグラフの同義語は、ナレッジグラフページの右上にあるその他のオプションアイコンの下にある同義語の管理オプションからもアクセスすることができます。
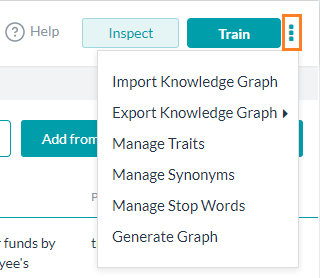
注:同義語ボックスにそれぞれの同義語を入力した後に[Enter]キーを押します。それぞれの同義語の入力後に[Enter]キーを押さずに複数の同義語を入力した場合、スペースで区切られていたとしても、同義語はすべて1つのエンティティとみなされます。 - リリース7.2以降では、KGの用語の識別に Botの同義語 を使用できるようになりました。このオプションは、しきい値および設定、またはナレッジグラフページの右上にあるその他のオプションアイコンの下にある
同義語の管理オプションから有効にすることができます。
有効にすると、KGの用語(またはタグ)と一致するBotレベルの同義語は、同義語セクションのBot同義語の見出しの下に自動的に表示され、KGエンジンによって使用されます。Botの同義語は、KGグラフレベルの同義語と同様に、パスの設定と質問の照合に使用されます。ノードがBotの同義語とBotの概念の両方に一致した場合、Botの概念が優先されます。
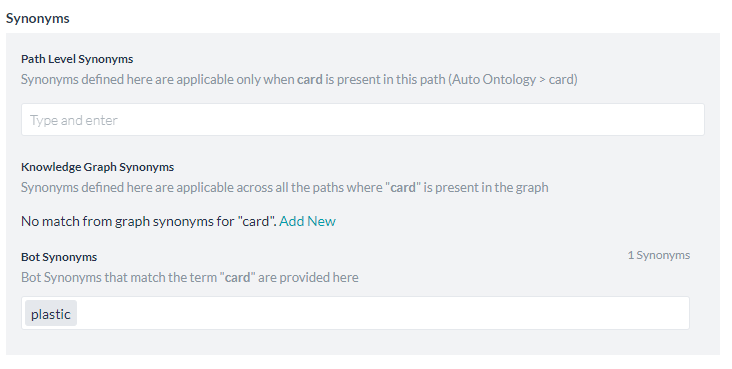
- ローカルの同義語を追加するには、パスレベルの同義語のボックスに入力します。
- 子ノードに同義語を追加するには、設定ウィンドウの下部にリスト表示されている子ノードの用語の横にある同義語ボックスに入力します。
タグの同義語を追加する:
- ナレッジグラフの左上で質問を追加した用語/ノードをクリックします。
- 質問パネルの質問一覧から、質問にカーソルを合わせます。
- 編集アイコンをクリックし、Q&A編集ウィンドウでタグをダブルクリックします。(デフォルトのタグではなくカスタムタグのみでも編集可能)
- 開いたタグ設定ウィンドウで、それぞれの同義語を入力し、Enterを押して追加します。
特性
注:特性はバージョン6.4以前のクラスに置き換わります。
一般的なユーザーの発話から特性を作成し、ナレッジグラフの関連する用語(ノードやタグ)に追加することができます。特性の詳細については、こちらをクリックしてください。
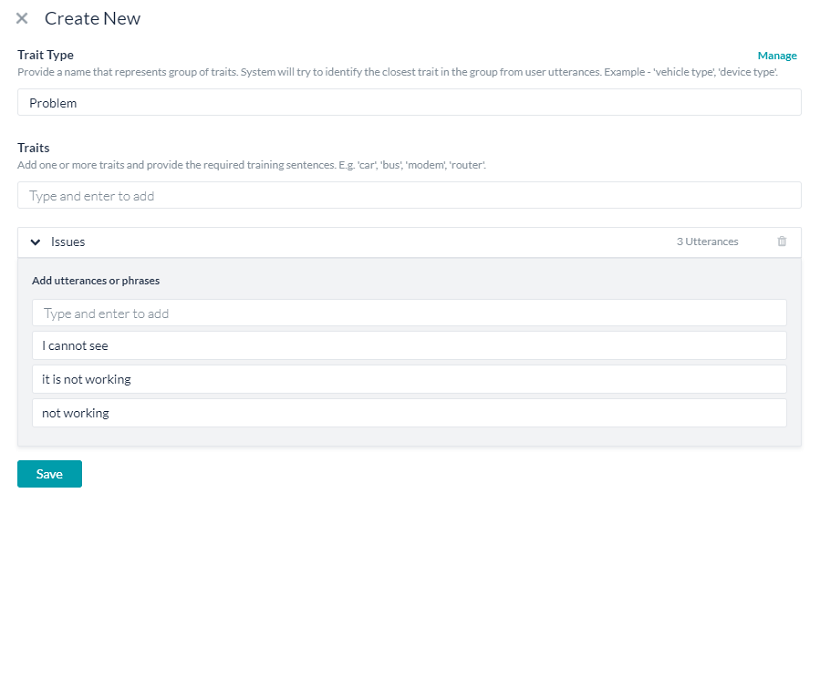
特性を作成する:
自然言語セクションから特性を作成した場合、当該特性はBotビルダー全体で共通であり、ここで使用することができます。
- ナレッジグラフウィンドウの右上にあるその他のオプションアイコンをクリックして、特性の管理を選択します。
- 特性の管理のポップアップウィンドウで新しい特性をクリックします。
- 特性タイプおよび特性名フィールドに、特性に関連する名前を入力します。
- 特性に含めるすべての発話を発話 ボックスに入力します。Issues特性の例には、it is not working、not working、is not working、I cannot seeなどがあります。
- 保存をクリックします。
特性を作成したら、ナレッジグラフの複数のノードやタグに割り当てることができます。
ノード/用語に特性を追加する:
- ナレッジグラフの左上で、特性を追加する用語にカーソルを合わせます。
- ギアアイコンをクリックして設定画面を開きます。
- 特性ドロップダウンリストで特性の名前を選択し、保存をクリックします。
- ナレッジグラフの左上で、質問を追加した用語をクリックします。
- 質問パネルの質問一覧から質問にカーソルを合わせます。
- 編集アイコンをクリックし、Q&A編集ウィンドウで用語をダブルクリックします。(デフォルトの用語ではなくカスタム用語のみでも編集可能)
- タグ設定ウィンドウの特性ロップダウンリストで、特性の名前を選択して保存をクリックします。
コンテキスト
以下の設定を行うことで、用語やタグのコンテキスト管理を行うことができます。
- インテントの前提条件 – このノードまたはタグの修飾子として存在すべきコンテキストです。
- コンテキスト出力 – このタスクの実行を示すために生成されるコンテキストです。
バージョン8.0のプラットフォームリリース後、オーガナイザーノードでもコンテキストを有効にできるようになりました。コンテキスト管理オプションを有効にすると、上記のコンテキスト前提条件とコンテキスト出力を設定することができます。コンテキスト管理のオプションを有効にすると、デフォルトでは用語/ノード名が表示されないことにご注意ください。
コンテキスト管理の詳細については、こちらを参照してください。
ストップワード
ユーザー発話に存在するストップワードは、たとえストップワードがノード(またはノードの同義語)を定義するために使用されていたとしても、スコアリングのために削除されます。
ナレッジグラフには、言語固有の事前定義されたストップワードがあります。このリストは、お客様の要件に合わせてカスタマイズすることができます。
ストップワードリストを編集する:
- ナレッジグラフページでその他のオプションアイコンをクリックし、ストップワードの管理を選択します。
- ストップワードの管理ウィンドウから、ストップワードを削除または追加します。
トレーニング及びテスト
ナレッジグラフの作成/編集が完了したら、ナレッジグラフウィンドウの右上にあるトレーニングボタンをクリックします。これを行うことで、パス、同義語、および質問と回答の組み合わせがすべてグラフDBエンジンに送信されます。
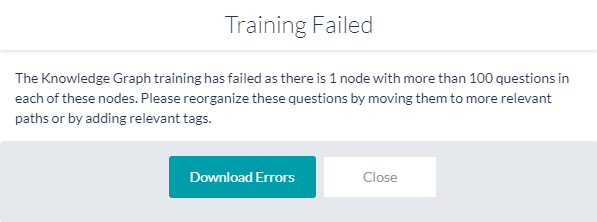
1つのノードに100問以上の質問がある場合、トレーニングは失敗します。この制限はバージョン7.3以降導入されたもので、ナレッジグラフの応答速度を向上させて効率化を図るために導入されたものです。このようなエラーが発生した場合には、100問以上の問題があるパスを一覧にしたエラーCSVファイルをダウンロードすることができます。このファイルを使用してナレッジグラフを修正することができます。
ナレッジグラフのテスト
ナレッジグラフの作成とトレーニングが完了したら、Botと対話し、ナレッジグラフに関連する質問を投げかけることをお勧めします。不足している用語、質問、代替質問、同義語、特性を識別できるよう、さまざまな発話を使用してBotの応答をテストします。
FAQの検出手順
以下のFAQ検出手順では、ナレッジグラフ(KG)エンジンがナレッジグラフから質問を絞り込むプロセスの概要について説明します。
- ノードの抽出:KGエンジンは、ユーザーの発話を処理して、ナレッジグラフに存在する用語(ノード)を抽出します。さらに、用語に関連付けられた同義語、特性、タグも考慮します。
- クエリグラフ:KGエンジンは、抽出されたノードを構成するすべてのパスを取得します。
- 絞り込みパス:ユーザーの発話と50%以上一致する用語からなるパスはすべて、その後の処理のために絞り込まれます。例えば、ユーザーの発話でこれらの用語の少なくとも2つが発生した場合、エンジンは、パーソナルバンキング→共同アカウント→追加→アカウントホルダーなどの4つのノードを持つパスを絞り込みます。
注:パスカバレッジの計算ではルートノードは考慮されません。 - 特性を使用したフィルタリング:ナレッジグラフに特性を定義すると、上記のステップで絞り込まれたパスは、ユーザーの発話内の分類アルゴリズムの信頼度スコアに基づいて、さらにフィルタリングされます。
- ランカーへの送信:KGエンジンは、次にショートリストに含まれるパスをランカープログラムに送信します。
- コサイン類似度に基づくスコア:ランカーは、ユーザー定義の同義語、単語のレンマ形、n-gram、ストップワードを使用して、ユーザーの発話と絞り込まれた質問との間のコサイン類似度を計算します。パスはコサイン類似度スコアの高い順にランク付けされます。
- 修飾一致:ランカーは、次のようにパスを修飾します。
- score >= upper_thresholdのパスは、回答として修飾されます(確実に一致)。
- lower_threshold < score < upper_thresholdのパスは、サジェスト(一致の可能性が高い)としてマークされます。
- score < lower_thresholdのパスは無視されます。
しきい値および設定
トレーニングやパフォーマンスを向上させるために、FM、KG、MLの3つのNLPエンジンすべてに対して、しきい値および設定を指定することができます。これらの設定は、自然言語 > トレーニング > しきい値および設定からアクセスすることが可能です。
注:お客様のBotが多言語の場合、言語ごとに異なるしきい値を設定することができます。設定が行われていない場合は、すべての言語でデフォルト設定が使用されます。この機能はバージョン7.0以降で利用可能です。
ナレッジグラフエンジンの設定については、以下のセクションで詳しく説明します。
しきい値および設定への移動
- ナレッジグラフの設定を行うBotを開きます。
- サイドナビゲーションパネルにカーソルを合わせ、自然言語 > トレーニングをクリックします。
- しきい値および設定タブをクリックします。
- 以下に、このページのナレッジグラフセクションについて詳述しています。
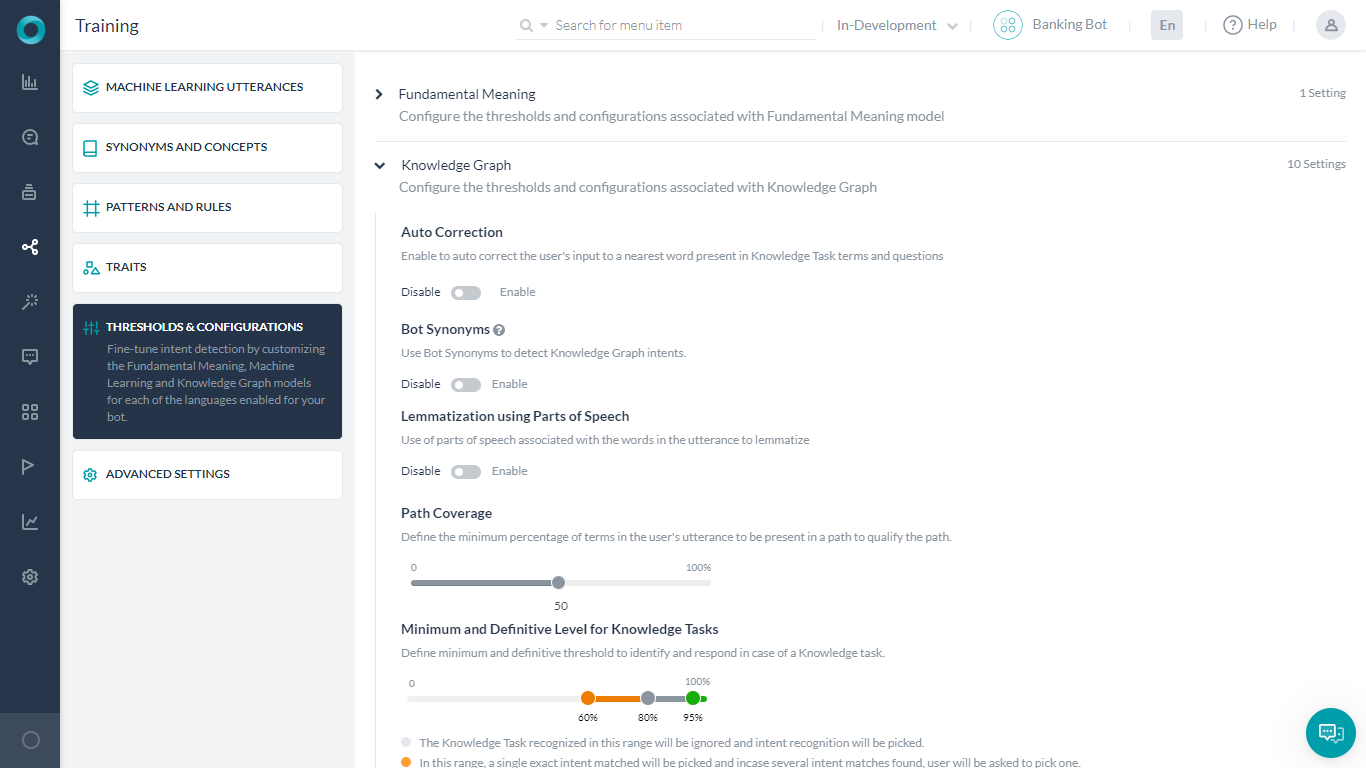
自動補正は、ユーザーが入力した単語を、Botのナレッジグラフドメイン辞書から最も近く一致する単語に修正します。ナレッジグラフドメイン辞書は、ナレッジグラフの質問、代替質問、ノード、および同義語から抽出された単語で構成されています。
Botの同義語(バージョン7.2で導入)により、BotプラットフォームはナレッジグラフでもBotの同義語を使用できるようになります。KGエンジンがインテントを検出するためにBotの同義語を含めるには、トレーニングが必要です。この設定を有効にしてトレーニングを開始するには、プロンプトの表示後「続行」をクリックしてください。
音声の一部を使用したレンマ化(バージョン7.3で導入)により、発話内の単語に関連する言葉の一部を使用して、レンマ化を行うことができます。(詳細は以下を参照)
パスカバレッジを使用して、パス内に存在するユーザーの発話に含まれる用語の最小割合を定義し、その後のスコアリングのためにパスを修飾することができます。デフォルトの設定は50%です。つまり、ユーザーの発話の用語の少なくとも半分がノード名および用語に一致している必要があります。
ナレッジグラフインテントの最小レベルおよび確定レベルでは、ナレッジグラフインテントの信頼度を設定することができます。グラフの信頼度の割合は、以下の3つの範囲のいずれかで表示および調整することができます。
- 確定範囲 – この範囲(緑の領域)の一致が選択され、その他の可能性のある一致はすべて破棄されます。デフォルトでは93〜100%に設定されています。
- 可能性の高い範囲 – この範囲(ダークグレーの領域)の一致は、再スコアリングおよびランク付けの対象と見なされます。デフォルトでは80~93%に設定されています。
- 信頼度の低い範囲 – 他のインテントが一致しなかった場合、信頼度の低い一致(オレンジの領域)がエンドユーザーに提示され、インテント確認用に使用されます。デフォルトでは60~80%に設定されています。
- インテントとの一致なし – ライトグレーの領域は、ナレッジグラフインテントのNLPインタプリタの信頼度が低すぎるため、ナレッジグラフインテントと一致しないことを表しています。デフォルトでは60%に設定されています。
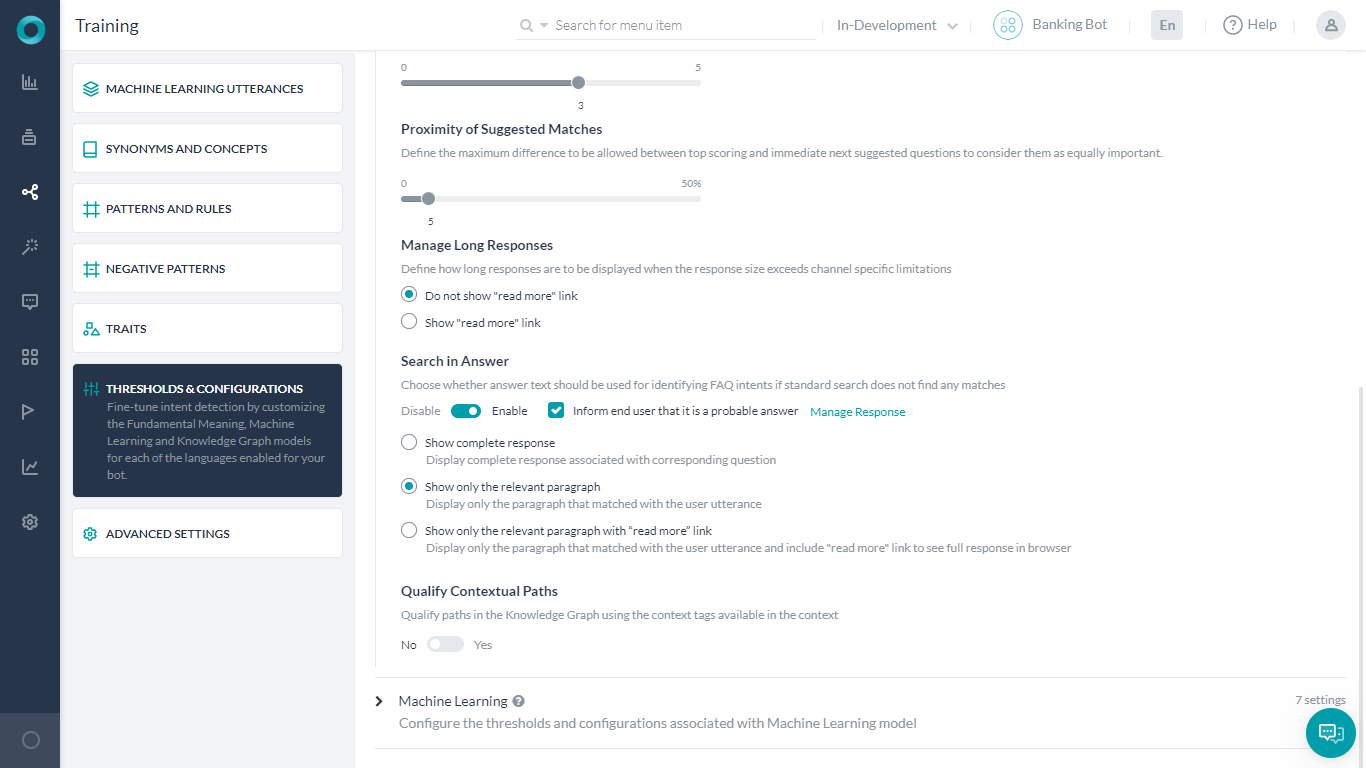
KGの提案数:明確なKGインテントの一致がない場合に表示される、KG/FAQの最大提案数(5つまで)を定義します。デフォルトでは3に設定されています。
提案された一致の近似度:最高スコアの質問と次に提案される質問の間で許容される最大差(最大50%)を定義して、それらを同じように重要な質問と見なします。デフォルトでは5%に設定されています。これは可能性の高い範囲の一致に適用されます。
応答サイズがチャネル固有の制限を超えている場合、長い応答を管理します。応答を省略するか、続きを読むリンクで応答全文を表示するかを選択することができます。「続きを読む」リンクはメッセージの最後に含まれます。このリンクを選択した場合、応答全文がブラウザで開かれます。ウェブブラウザで長い応答を開くためのURLは、プラットフォームによってデフォルトで設定されていますが、カスタムURLを指定することも可能です。
対象となるFAQを回答で検索(詳細は以下を参照)
コンテキストで利用可能なコンテキストタグを使用して、ナレッジグラフ内のコンテキストパスを修飾します。このオプションを有効にすると、コンテキストからの用語またはタグを使用して、パスを絞り込むことができます。これらのタグは、以前一致したパスやインテント、あるいはカスタム定義済みのタグに由来するものです。
プラットフォームのバージョン8.0では、詳細設定が導入されています。詳細はこちらを参照してください。
回答で検索
この機能により、質問との照合のみではなく、回答セクションに対してユーザー入力を検索することでFAQを特定できるようになります。つまり、質問からFAQが特定されなかった場合にのみ、回答セクションでの検索が行われます。
注:この機能はすべての言語でサポートされているわけではありません。詳細はこちらを参照してください。
「回答で検索」フラグが有効になっている場合は、ナレッジグラフエンジンはインテントを識別するための回答テキストを考慮します。
このオプションを有効にすると、回答が有力な回答であることをエンドユーザーに知らせるかどうかを指定することができます。選択した場合、その旨の標準メッセージが表示され、応答の管理リンクを使用してカスタマイズすることができます。詳細はこちら。
応答をレンダリングする方法は3つあります。
- 回答全文を表示する:応答全文がユーザーへの回答として送信されます。
- 関連する段落のみを表示する:質問が特定された関連する段落のみが応答として送信されます。
- 「続きを読む」リンクを含む関連する段落のみを表示する:質問が特定された関連する段落のみが応答として送信されます。
メッセージの最後に「続きを読む」リンクが追加されます。このリンクを選択すると、ブラウザで回答全文が開かれます。ウェブブラウザで長い応答を開くためのURLは、プラットフォームによってデフォルトで設定されていますが、カスタムURLを適用することも可能です(詳細は以下を参照)。
カスタムURLの設定:
デフォルトでは、Webブラウザで長文の回答を開くURLがプラットフォームによって設定されています。FAQの回答をレンダリングするためのカスタムURLを提供するオプションも選択することができます。
プラットフォームは、関連するメッセージテンプレート(テンプレートID)の詳細およびその他の必要な情報を含むURLを呼び出します。
以下のAPIは、FAQの全情報を提供します。
URL:
https://{{host-name}}/api/1.1/public/users/{{userId}}/faqs/resolvedResponse/{{respId}}
メソッド: get
ヘッダー: {auth : JWT}
サンプルの応答:
{
"response": "You can contact our Branch officials wherein you have submitted your documents.If the documents are in order, the account will be opened within 2 working days.",
"primaryQuestion": "How to check the status of my account opening?"
}
レンマ化
言語学におけるレンマ化とは、単語の屈折形をグループ化して、単語のレンマ形または辞書形式で識別される単一の項目として分析できるようにするプロセスです。レンマ化の過程において、ユーザーの発話からの音声の一部の情報を使用することで、より正確なFAQの識別を向上させることができます。
以下は、音声の一部を使用している場合と使用していない場合のKGエンジンで認識されたフレーズの例です。
| ユーザーの発話 | POSを不使用 | POSを使用 |
|---|---|---|
| What is my outstanding leave balance | outstand | outstanding |
| I am filing for a visa so that I can travel | file | filing |
| What happens to my excess annual leave and sick leave hours when I retire? | exces, happen | excess, happens |






