Botを構築してトレーニングした後、最も重要な問題となるのはBotの学習モデルがどれだけ優れているかということです。したがって、Botのパフォーマンスを評価することは、Botがユーザーの発話をどの程度よく理解しているかを示すために重要です。
バッチテスト機能は、Botが特定の発話セットから期待されるインテントとエンティティを正しく認識する能力を見極めるのに役立ちます。これには、一連のテストを実行して詳細な統計分析を行い、Botの機械学習モデルのパフォーマンスを測定することが含まれます。
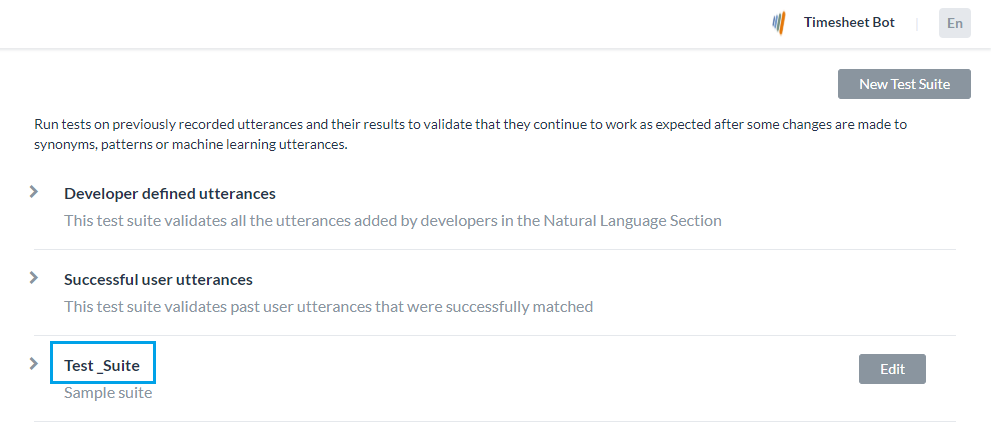
バッチテストを実行するには、ビルダーで使用可能な事前定義されたテストスイートを使用するか、独自のカスタムテストスイートを作成します。要件に基づいてテストスイートを実行して、目的の結果を表示することができます。こちらは、左側のナビゲーションメニューよりテスト -> バッチテストオプションからアクセスできます。
テストスイートの管理
Kore.aiは、バッチテストを実行するためにすぐに使用できるテストスイートをいくつか用意しています。開発者が定義した発話および成功したユーザーの発話は、バッチテストを実行できる組み込みのテストスイートです。また、発話のカスタムセットをテストするための新しいテストスイートを作成することもできます。
開発者が定義した発話
このテストスイートは、機械学習の発話画面から、開発者が以前に追加およびトレーニングした発話を検証します。このテストスイートを使用するということは、開発者がBotのすべてのタスクに対して追加した発話セット全体をまとめてテストすることを意味します。
成功したユーザーの発話
このテストスイートには、インテントに正常に一致し、対応するタスクが完全に実行されたすべてのエンドユーザーの発話が含まれています。これらの発話は、分析モジュールの「検出されたインテントI」セクションからも見つけることができます。
新しいテストスイートの追加
新しいテストスイートを使用することで、バッチファイル(データセットとも呼ばれる)に、テスト発話の配列を一度にまとめてインポートできます。データセットファイルはCSVまたはJSON形式で記述する必要があり、最大10,000の発話を含めることができます。新しいテストスイートオプションを使用して、テストスイート作成の一部としてサンプルのCSVまたはJSONファイル形式をダウンロードできます。
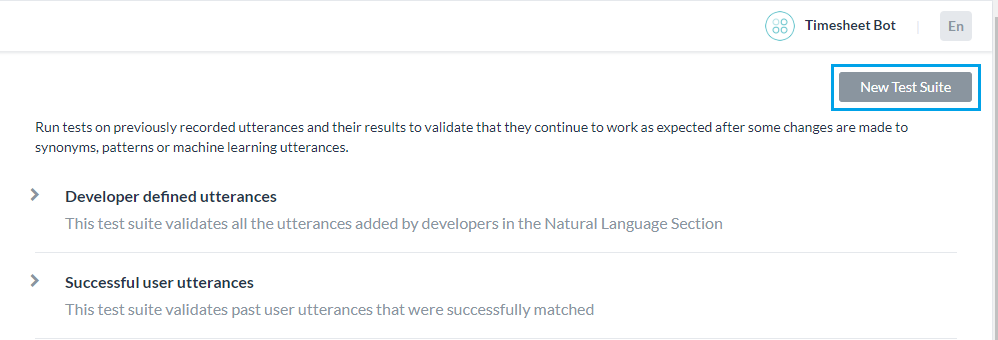
テストスイートのJSON形式
カスタムスイートを作成するためのJSON形式を使用すると、テストケースの配列を定義することができます。各テストケースは、テスト対象の発話、テスト対象の発話に対するインテントから構成され、オプションで発話から決定する予定のエンティティのリストを定義します。期待されるインテントが子のインテントである場合は、検討される親のインテントを含めることもできます。

- マルチアイテムが有効になっているエンティティの場合、値は次のように指定する必要があります。
entity1||entity2 - 複合エンティティでは、次の形式で値を指定する必要があります。
component1name:entityValue|component2name:entityValue2

- エンティティが抽出されるオーダーは次のように指定できます。
"entityOrder":["TransferAmount", "PayeeName"]オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。

| プロパティ名 | タイプ | 説明 |
|---|---|---|
| テストケース | 配列 |
以下から構成されます。
|
| 入力 | 文字列 | エンドユーザーの発話 |
| インテント | 文字列 |
エンドユーザーの発話の目的を決定します(FAQテストケースの場合はタスク名や主要な質問にすることもできます) 7.3以降のリリースでは、このプロパティを使用して、trait(特性)の接頭辞を使うことにより、この発話に対して特定される特性を定義できます。例)特性:特性名1 || 特性名2 || 特性名3 8.0以降のリリースでは、このプロパティには予想されるスモールトークパターンを含めることができます。 |
| parentIntent | 文字列[オプション] | インテントがサブインテントである場合に検討される親インテントを定義します。 スモールトークの場合、スモールトークが状況に応じたフォローアップを目的としているときにこのフィールドに入力する必要があります。マルチレベルの文脈上のインテントの場合、親インテントは || を使った区切り文字で区切る必要があります。 |
| エンティティ | 配列[オプション] |
入力文から決定されるエンティティの配列で構成されます。
|
| entityValue | 文字列 | 発話から決定されると予想されるエンティティの値です。期待されるエンティティ値を文字列として定義するか、正規表現を使用できます。バッチテストの目的のために、プラットフォームはすべてのエンティティ値を文字列形式にフラット化します。詳細については、エンティティ形式の変換を参照してください。 |
| entityName | 文字列 | 発話から決定されると予想されるエンティティの名前です。 |
|
entityOrder (バージョン7.1以降) |
配列[オプション] |
エンティティが抽出されるオーダーを指定するエンティティ名の配列です。 オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。 |
テストスイートのCSV形式
カスタムスイートを作成するためのCSV形式では、テストケースをCSVファイルのレコードとして定義することができます。各テストケースは、テスト対象の発話、テスト対象の発話に対するインテントから構成され、オプションで発話から決定するエンティティを定義します。テストケースで文から複数のエンティティを検出する必要がある場合は、検出される追加のエンティティごとに追加の行を含める必要があります。期待されるインテントが子のインテントである場合は、検討される親のインテントを含めることもできます。
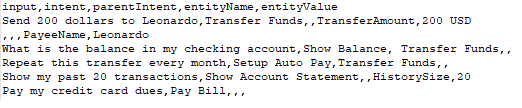
- マルチアイテムが有効になっているエンティティの場合、値は次のように指定する必要があります。
entity1||entity2 - 複合エンティティでは、次の形式で値を指定する必要があります。
component1name:entityValue|component2name:entityValue2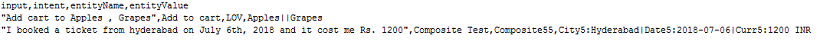
- エンティティ値の抽出オーダーは、次の形式で記述できます。
entity3>entity4>entity1オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。
| 列名 | タイプ | 説明 |
|---|---|---|
| 入力 | 文字列 | エンドユーザーからの発話 |
| インテント | 文字列 |
エンドユーザーの発話の目的を決定します(FAQテストケースの場合はタスク名や主要な質問にすることもできます) 7.3以降のリリースでは、このプロパティを使用して、trait(特性)の接頭辞を使うことにより、この発話に対して特定される特性を定義できます。例)特性:特性名1 || 特性名2 || 特性名3 8.0以降のリリースでは、このプロパティには予想されるスモールトークパターンを含めることができます。 |
| parentIntent | 文字列[オプション] | インテントがサブインテント である場合に検討される親インテントを定義します。スモールトークの場合、このフィールドはスモールトークが文脈上のフォローアップインテントであり、フォローアップインテントの基準が満たされていると仮定してインテントが一致する場合にフィールドに入力する必要があります。マルチレベルの文脈上のインテントの場合、親インテントは区切り文字 || で区切る必要があります。 |
| entityValue | 文字列[オプション] | 発話から決定されると予想されるエンティティの値です。期待されるエンティティ値を文字列として定義するか、正規表現を使用できます。バッチテストの目的のために、プラットフォームはすべてのエンティティ値を文字列形式にフラット化します。詳細については、エンティティ形式の変換を参照してください。 |
| entityName | 文字列[オプション] | 発話から決定されると予想されるエンティティの名前です。 |
|
entityOrder (バージョン7.1以降) |
配列[オプション] |
エンティティを抽出する順番を > で区切ったエンティティ名の配列です。 オーダーが選ばれていないか部分的に選ばれている場合、プラットフォームは暗黙のオーダーを定義して、最初にNERエンティティとパターンエンティティを処理し、次に残りのエンティティを処理します。 |
エンティティ形式の変換
| エンティティタイプ | サンプルエンティティValueType | フラット形式の値 | キーのオーダー |
|---|---|---|---|
| アドレス | P.O.Box 3700 Eureka, CA 95502 | P.O.Box 3700 Eureka, CA 95502 | |
| 空港 | { "IATA": "IAD", "AirportName": "Washington Dulles International Airport", "City": "Washington D.C.", "CityLocal": "Washington", "ICAO": "KIAD", "Latitude": "38.94", "Longitude": "-77.46" } | ワシントン・ダレス国際空港 IAD KIAD 38.94 -77.46 ワシントンD.C. ワシントン | 空港名 IATA ICAO 緯度 経度 市 市地域 |
| 市内 | ワシントン | ワシントン | |
| 国 | { "alpha3": "IND", "alpha2": "IN", "localName": "India", "shortName": "India", "numericalCode": 356} | IN IND 356 インド インド | alpha2 alpha3 数値コード 地域名称 略称 |
| 会社名・組織名 | Kore.ai | Kore.ai | |
| カラー | 青 | 青 | |
| 通貨 | [{ "code": "USD", "amount": 10 }] | 10 USD | 金額コード |
| 日付 | 2018年10月25日 | 2018年10月25日 | |
| 日付期間 | { "fromDate": "2018-11-01", "toDate": "2018-11-30" } | 2018-11-01 2018-11-30 | fromDate toDate |
| 日時 | 2018-10-24T13:03:03+05:30 | 2018-10-24T13:03:03+05:30 | |
| 説明 | サンプル説明 | サンプル説明 | |
| メール | user1@emaildomain.com | user1@emaildomain.com | |
| 項目リスト(列挙) | Apple | Apple | |
| アイテム一覧(検索) | Apple | Apple | |
| 場所 | { "formatted_address": "8529 Southpark Cir #100, Orlando, FL 32819, USA", "lat": 28.439148,"lng": -81.423733 } | 8529 Southpark Cir #100, Orlando, FL 32819, USA 28.439148 -81.423733 | formatted_address lat lng |
| 数 | 100 | 100 | |
| 氏名 | ピーターパン | ピーターパン | |
| 割合 | 0.25 | 0.25 | |
| 電話番号 | +914042528888 | +914042528888 | |
| 量 | { "unit": "meter", "amount": 16093.4, "type": "length", "source": "10 miles" } | 16093.4 メーター 距離 10マイル | 合計 ユニット タイプ ソース |
| 文字列 | サンプル文字列 | サンプル文字列 | |
| 時間 | T13:15:55+05:30 | T13:15:55+05:30 | |
| タイムゾーン | -04:00 | -04:00 | |
| URL | https://kore.ai | https://kore.ai | |
| 郵便番号 | 32819 | 32819 |
データセットファイルのインポート
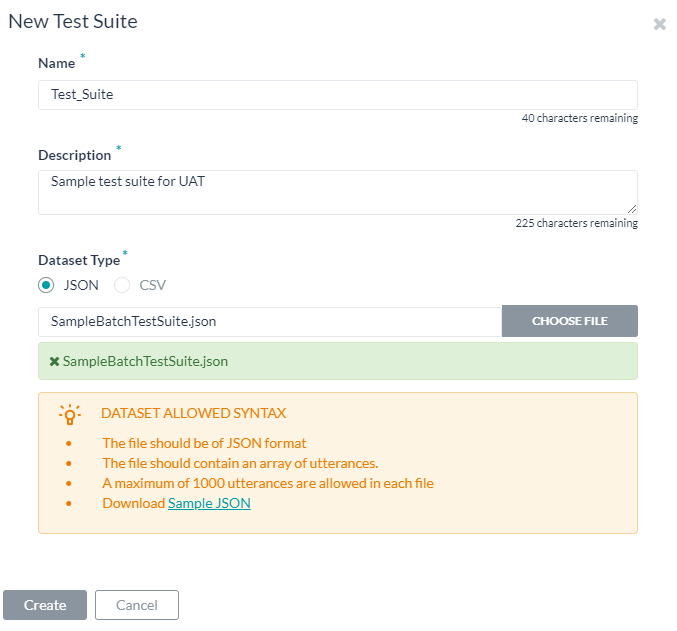
- バッチテストページの新しいテストスイートをクリックします。データセットをインポートするためのダイアログボックスが表示されます。
- 名前、説明を入力し、データセットファイルのそれぞれのボックスにデータセットタイプの選択を入力します。
- データセットファイルをインポートするには、ファイルを選択をクリックします。選択したデータセットタイプに従って、発話を含むJSONまたはCSVファイルを探して選択します。
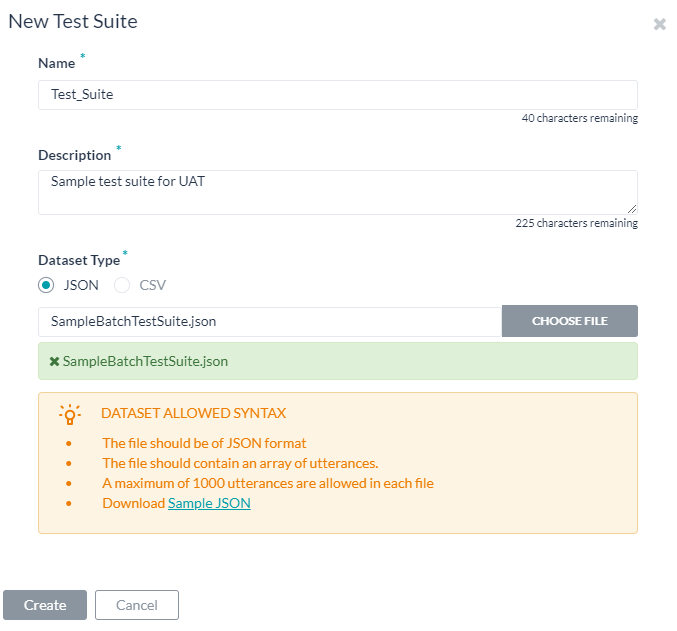
- 作成をクリックします。データセットファイルは、バッチテストページでテストスイートを実行するためのオプションとして表示されます。
テストスイートの実行
次の手順では、Botでバッチテストを実行し、テスト結果に基づいて発話に関する詳細な分析レポートを取得する方法について説明します。 開始するには、ビルダーのテストセクションでバッチテストをクリックします。
たとえば、開発者が定義した発話などのテストスイートを実行するには、開発者が定義した発話に続くテストスイートを実行をクリックします。 これにより、開発者が定義した発話のバッチテストが開始されます。 バージョン7.3のリリース後では、開発中または公開済みバージョンのBotのテストスイートを実行できます。
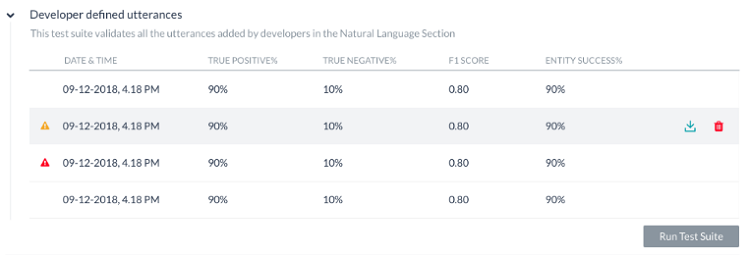
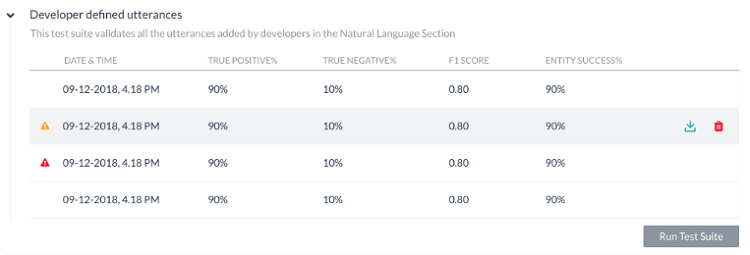
テストでは、以下に説明するような結果が表示されます。 テストを実行するたびに、テストレポートの記録が作成されテスト結果の概要が表示されます。 以下のスクリーンショットのバッチテスト結果には、次の情報が含まれています。
- 最終実行日時では、最新のテスト実行の日付と時刻が表示されます。
- F1スコアは、精度と再現率の加重平均です。
- 精度は、正しく分類された発話の数を、既存のタスクに(正しくまたは誤って)分類された発話の総数で割ったものです。つまり、すべての分類された陽性に対する真陽性の比率(真陽性と偽陽性の合計)となります。
- 再現率は、正しく分類された発話の数を、既存のタスクに正しく分類された、または既存のタスクがない場合に誤って分類された発話の総数で割ったものです。つまり、実際に一致したインテントやタスクに対して正しく分類された発言の比率(真陽性と偽陰性の合計)です。
- インテント成功%は、テストの結果として得られた正しいインテントの認識割合を表示します。
- エンティティ成功%は、テストの結果として得られた正しいエンティティの認識割合を表示します。
- バージョンタイプは、テストスイートが実行されたBotのバージョン(開発版または公開済み)を特定します。
- 各テスト実行から考えられる結果は3つあります。
- 成功-ファイル内に存在するすべてのレコードが処理された場合です
- 警告付きの成功-システムエラーのためにスイート内に存在する1つ以上のレコードが検出から破棄された場合です
- 失敗-システムエラーが発生し、リカバリー後にテストを再開できなかった場合です
警告/エラーアイコンの上にカーソルを合わせると、その理由を示すメッセージが表示されます。
テスト実行の詳細な分析を取得するには、ダウンロードアイコンををクリックして、テストレポートをCSV形式でダウンロードします。 必要に応じて、テスト結果を削除するオプションがあります。レポートの上部のセクションには、次のフィールドを含む要約が含まれています。
- Bot名
- テストスイートのレポート名
- Bot言語(7.3以降のリリース)
- 実行タイプは、テストスイートが実行されたBotのバージョン(開発版または公開済み)を特定します。
- しきい値設定(7.3以降のリリース)は、このテストスイートの実行時に適用されるNLPのしきい値の詳細を示し、3つのNLエンジンのそれぞれの設定に続いて以下の詳細を示します。
- モード-ml、faq、cs
- minThreshold
- maxThreshold
- exactMatchThreshold
- isActive
- taskMatchTolerance
- wordCoverage
- suggestionsCount
- pathCoverage
- 最終テスト: 開発者が定義した発話の最新のテスト実行日です。
- 発話数: テスト実行に含まれる発話の総数です。
- 成功/失敗率: 正常に予測された発話の総数を、発話の総数で割った値に100を掛けたものです。
- 真陽性(TP): 予想されるインテントに正しく一致した発話の割合です。
スモールトークの場合は、期待されるインテントと実際のインテントのリストが同じである場合です。
特性の場合、これには予想される一致に加えて一致する特性が含まれます。 - 真陰性(TN): どのインテントとも一致することが期待されておらず、一致しなかった発話の割合です。 スモールトークには適用されません。
- 偽陽性(FP): 予想しないインテントに一致した発話の割合です。スモールトークの場合、予想されるインテントと実際のインテントのリストが異なる場合があります。
- 偽陰性(FN): 予想されるインテントと一致しない発話の割合です。 スモールトークの場合、予想されるスモールトークのインテントのリストが空白で、実際のスモールトークがインテントにマッピングされている場合です。
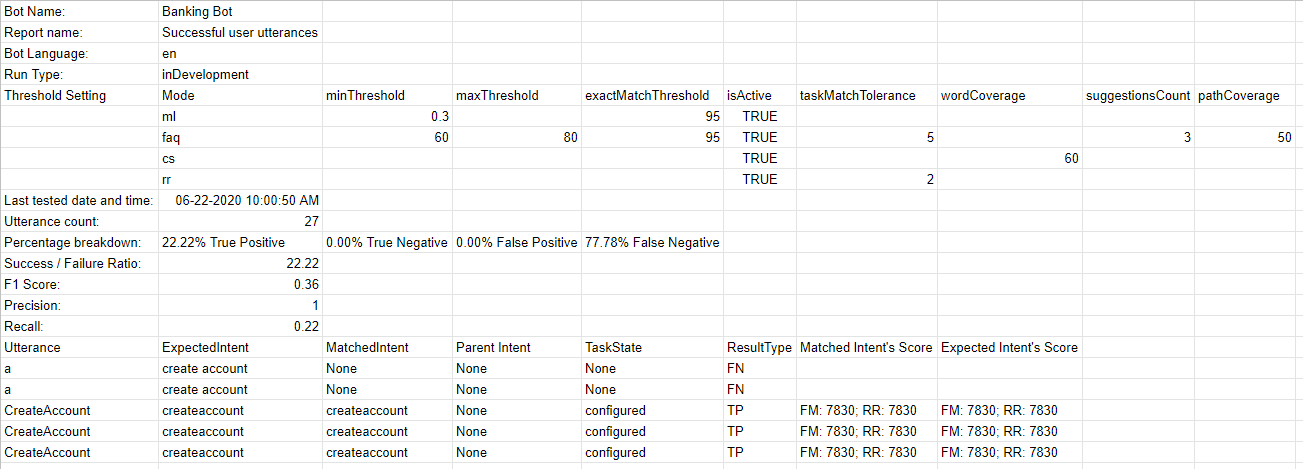
このレポートには、各テスト発話とそれに対応する結果に関する詳細情報も含まれています。
- 発話-対応するテストスイートで使用される発話です。
- 予想されるインテント-特定の発話に一致すると予想されるインテントであり、該当する場合は特性プレフィックスが付いた特性が含まれます。
- 一致したインテント-バッチテスト中に発話に一致したインテントです。 これには、特性プレフィックスが付いた一致した特性が含まれます(7.3以降のリリース)。 これには、一致したスモールトークのインテントが含まれます(8.0以降のリリース)。
- 親インテント-発話をインテントと照合するために検討される親のインテントです。
- タスク状態-インテントが特定されているインテントやタスクの状態です。使用可能な値には、設定済みまたは公開済みがあります。
- 結果タイプ-真陽性または真陰性または偽陽性または偽陰性に分類される結果です。
- エンティティ名-発話から検出されたエンティティの名前です。
- 予想されるEntityValue-バッチテスト中に決定されると予想されるエンティティ値です。
- 一致したEntityValue-発話から特定されたエンティティ値です。
- エンティティの結果-期待されるエンティティ値が実際のエンティティ値と同じであるかどうかを示すために、真または偽に分類される結果です。
- 予想されるエンティティのオーダー-入力ファイルからのエンティティ値です。
- 実際のエンティティのオーダー –
- 予想されるすべてのエンティティのオーダーが指定されている場合、同じオーダーがこの列に含まれます。
- オーダーが用意されていない場合、システムが決定したオーダーが列に含まれます。
- 一部のエンティティに対してオーダーが与えられている場合、ユーザー定義のオーダーとシステム定義のオーダーの組み合わせが含まれます。
- 一致したインテントのスコア -偽陽性と偽陰性の場合、FM、機械学習、ナレッジグラフエンジンからの信頼スコアが、発話からの一致したインテントに対して表示されます。 エンジンがインテントを検出した場合にのみスコアが付与されることに注意してください。つまり、3つのエンジンすべてのスコアが常に表示されるとは限りません。
- 予想されるインテントのスコア-偽陽性の場合、特定の発話に一致すると予想されるインテントの信頼スコアが示されます。 この場合も、インテントを検出するエンジンによってスコアが与えられます。
重要な注意事項::
- Bot NLPトレーニングへの最適なアプローチは、最初にBotが特定する必要のあるほとんどのユースケース(ユーザーの発話)のテストスイートを作成し、それをモデルに対して実行して、失敗したものについてトレーニングを開始することです。
- 使用頻度の高い発話のためのバッチテストモジュールを作成・更新します。
- 詳細なテストを行った後でのみ、トレーニング済みモデルを公開します。
- インテントに名前を付けるときは、名前が比較的短く(3~5語)、特殊文字やストップワードリストの単語が含まれていないことを確認してください。 インテント名が、ユーザーが発話で要求する名前に近いことを確認してください。
- バッチテストの実行ではユーザーのコンテキストは検討されません。 したがって、コンテキストを検討した場合、実際のBotでは真陽性であるのに、テスト結果ではいくつかの偽陰性が表示される場合があります。




