ナレッジ グラフ抽出サービスを利用すると、エンタープライズの既存のよくあるご質問 (FAQ コンテンツ) をボットのナレッジ グラフに簡単に移動できます。
ウェブページや PDF 文書などの構造化されていないコンテンツからの抽出はもちろん、CSV ファイルなどの構造化コンテンツからの抽出にも対応しています。
抽出が完了したら、簡単に操作できるインターフェイスを使用して質問と回答を編集し、関連するナレッジ グラフ ノードの下に整理できます。
抽出プロセス
ナレッジ抽出サービスを利用してデータをナレッジ グラフに移動するには、以下のステップを実行します。
- ステップ 1 抽出: ステップ 1 抽出: PDF、ウェブ ページなどの構造化されていないファイル、または CSV のような構造化されたファイル内の質問と回答のデータ ソースから、既存の FAQ コンテンツを抽出します。抽出は、ボットのナレッジ グラフを作成する前後のいずれでも行うことができます。
注意: ナレッジ抽出サービスは、ソース タイプごとに特定のコンテンツ構造をサポートしています。詳細については、サポートされている形式のセクションを参照してください。
- ステップ 2 編集: データの抽出に成功すると、ナレッジ グラフに移動する前に質問と回答のテキストを編集できます。
- ステップ 3 移動: ナレッジ グラフの作成の前後のいずれでも、ボットにデータを追加できます。ナレッジ グラフが存在しない状態でに抽出した内容を追加しようとすると、ボットは自動的にボットの名前でナレッジ グラフを作成します。
ナレッジ抽出ツールを使用すると、抽出した内容をナレッジ グラフに追加できます。
- [ナレッジ グラフへの追加] で、選択した質問をナレッジ グラフのルート ノードに移動します。必要な用語がまだナレッジ グラフに追加されていない場合、またはボットにナレッジ グラフが存在しない場合にこのオプションを使用できます。
- 特定の用語への追加: ナレッジ グラフがすでにボットに作成されている場合は、必要なノードに選択したコンテンツをドラッグ アンド ドロップします。
ウェブサイトからの抽出
- コンテンツを抽出したいボットを開き、[ナレッジ グラフ] タブをクリックします。
- [抽出] セクションで [URL から抽出] をクリックします。
- 抽出用に [名前] を入力します。
- ページの URL を入力し、[続行] をクリックします。
- 抽出が完了すると、「成功」ステータスのページが表示されます。
ファイルからの抽出
注意: ファイル サイズは 5 MB を超えないようにしてください。
ファイル形式の詳細については、以下のサポートされている形式のセクションを参照してください。
- コンテンツを抽出するボットを開き、[ナレッジ グラフ] タブをクリックします。
- [抽出] セクションの [ファイルから抽出] タブから [参照] をクリックします。
- ファイルを参照して PDF または CSV 形式のファイルを選択し、[続行] をクリックします。
- PDF ファイルには、抽出前に文書に注釈を付けるオプションがあります。詳細については、以下をご覧ください。
- 抽出が完了すると、「成功」ステータスのページが表示されます。
注釈および抽出
(リリース 8.0 で導入)
事業関連のすべての FAQ を、プラットフォームで必須形式ではない PDF ファイルにまとめているとします。リリース 8.0 以前ではこれらのファイルを使用することはできませんでしたが、注釈ツールの導入により、コンテンツの重要な部分を指定して文書に注釈を付けられるようになりました。ナレッジ抽出エンジンは、この情報を用いて文書から FAQ を抽出します。
注意: これは PDF 文書にのみ適用されます。
- 新しく抽出した、または以前に抽出した PDF ファイルを選択します。そのファイルに含まれる質問がナレッジ グラフに追加されていない場合は、以前に抽出したファイルを使用できます。
- [注釈および抽出] (既に抽出されているファイルの場合には [レビューおよび追加] オプション) をクリックします。

- PDF 文書が注釈ツールによって読み込まれ、文書内のさまざまなセクションに注釈を付けられるようになります。
- 注釈を付けるには、テキストを選択して以下のようにタグ付けを行います。
- 見出しタグは質問の識別に使用します。見出しは質問を識別できるようモデルをトレーニングするために使用され、2つの連続した見出しの間の内容は前の見出しの回答として扱われます。
- ヘッダー – このようにマークされたテキストは無視されます。ヘッダーとしてマークされたテキストは、モデルがテキストを識別したり無視したりできるようトレーニングするために使用されます。フッターや段落などのテキストを誤ってヘッダーとしてマークすると、バックエンドの機械学習モデルが無効となり、最適な結果が得られなくなります。
- フッター – このようにマークされたテキストは無視されます。フッターとしてマークされたテキストは、モデルがテキストを識別したり無視したりできるようトレーニングするために使用されます。ヘッダーと同様に、ヘッダーや段落などのテキストを誤ってフッターとしてマークすると、バックエンドの機械学習モデルが無効となり、最適な結果が得られなくなります。
- 除外 – このようにマークされたテキストは抽出には使用されません。
- ページを無視する – 無視とマークされたページは抽出には使用されません。
- 注釈を削除することで、間違った注釈を修正できます。
- ナレッジ グラフ エンジンは、抽出処理で見出し、ヘッダー、フッターを使用します。ナレッジ グラフ エンジンがモデルを学習するため、文書全体に注釈を付ける必要はありません。数ページにわたって見出し、ヘッダー、フッターの注釈を付けたあと、質問を抽出して確認できます。納得のいく結果が得られた場合はナレッジ グラフに質問を追加することができ、そうでなければ納得のいく結果が得られるまで注釈をつける作業を繰り返します。
- その他の文書情報について記載しています。
- 文書情報 – 文書の名前、サイズ、ページ数。
- 注釈の概要 – 特定のページおよび文書全体にマークされた、カテゴリ別の注釈の数。
- 注釈を付けると、文書を抽出できるようになります。

- [質問のレビュー] タブから、ナレッジ グラフ エンジンが注釈およびトレーニングに従って抽出した質問を確認できます。そこからナレッジ グラフに追加するものを選択できます。ナレッジ グラフの適切なノードにドラッグ アンド ドロップします。
- 抽出された内容に納得がいかない場合は、いつでも文書に注釈を付け直すことができます。[注釈] タブをクリックすると、注釈ツールに戻ることができます。
- 注釈を付け直す場合は、上記と同様の手順で行います。実行する際には以下の点にご注意ください。
- ファイルに含まれる質問がナレッジ グラフに追加されていない場合は、文書に再度注釈をつけることができます。
- すでに質問が追加されている場合は、注釈付き文書のコピーを作成して作業できます。コピーはすべての注釈が損なわれることなく作成されます。
抽出した内容の編集
- ボットを開いて [ナレッジ グラフ] タブをクリックします。
- すべての抽出結果の一覧が [ナレッジ抽出] セクションに表示されます。
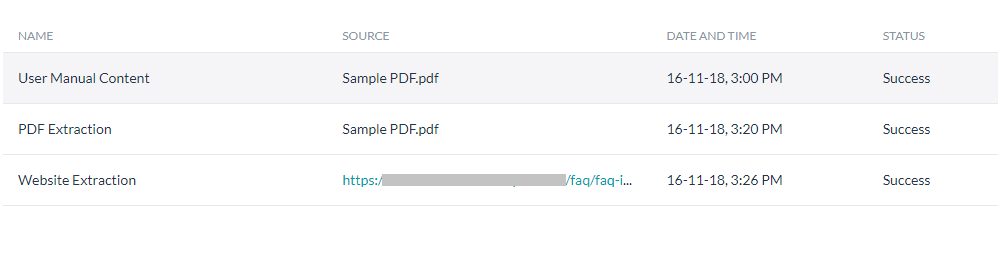
- 内容を編集したい抽出物の名前をクリックします。
- 編集するには、質問と回答の組み合わせにカーソルを合わせて [編集] アイコンをクリックします。
- 必要な変更を行い、[保存] をクリックします。
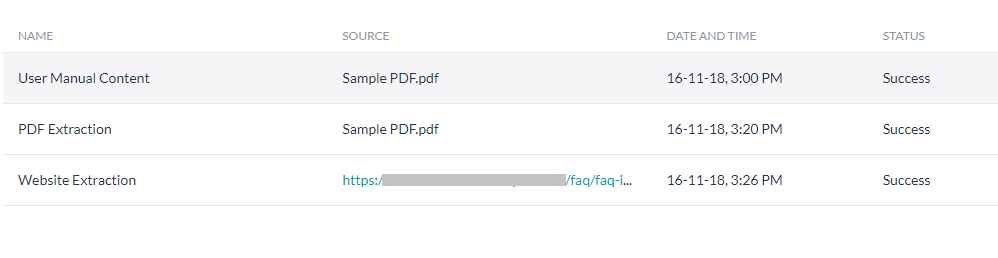
抽出されたコンテンツの追加
抽出したコンテンツをナレッジ グラフに追加する方法は 2 つあります。
抽出セクションから
- ボットを開いてナレッジ グラフタブをクリックします。
- [ナレッジ抽出] セクションで、追加したいコンテンツを含む抽出物の名前を選択します。
- 必要な質問と回答を、追加したいノード/用語にドラッグ アンド ドロップします。ドラッグ アンド ドロップすると、子ノードが展開されます。
- 複数の質問と回答を選択して、一括で移動できます。
ナレッジ グラフから
- ボットを開いて [ナレッジ グラフ] タブをクリックします。
- これらの質問と回答を追加するノードを選択します。
- [抽出から追加] をクリックします。成功した抽出と失敗した抽出の一覧が開きます。
- 移動したい内容を含む成功した抽出物の名前をクリックします。
- 移動したい質問と回答の組み合わせの横にあるチェックボックスを選択し、[追加を] クリックします。
注意: 一度質問と回答の組み合わせを抽出物からナレッジ グラフに移動すると、再び移動することはできません。コレクションにすでに存在する質問を抽出物から移動しようとした場合、プラットフォームは重複エラーを送出します。ナレッジ グラフから移動した内容には変更を加えることができます。一方で、ナレッジ グラフで質問が修正されたり削除されたりした場合には、開発者はナレッジ グラフに再度質問を追加できます。
サポートされている形式
ナレッジ抽出サービスは、サポートされている CSV、PDF、URL 形式からの FAQ の抽出のみをサポートしています。
ファイルサイズは 5 MB を超えないようにしてください。
CSV
- ナレッジ抽出サービスは、最初の列のテキストを質問として、2 列目のテキストを回答として解釈します。
- ファイルにはヘッダーが含まれないようにします。
- ナレッジ抽出サービスは、ヘッダーおよび他の列に存在するテキストを無視します。
- ナレッジ抽出サービスは、PDF からコンテンツを処理し、質問と回答の組み合わせに変換できます。
- 目次を含む文書: 文書には目次が含まれていることが望ましいです。この場合、ナレッジ抽出サービスは最初に目次を抽出し、それを使用して文書を解析して見出しを識別します。目次の情報は、見出しの階層 (見出し、中見出し、小見出しなど) を取得するために使用されます。これらの階層は、抽出プロセスの一部として、区切り記号として縦線 (バーティカル バー) で区切られます (見出し | 中見出し | 小見出し) 。
- 目次を含まない文書: この場合、ナレッジ抽出サービスはフォント スタイルまたはフォント サイズのいずれかに基づいて見出しを識別する、事前トレーニング済みの機械学習モデルを使用します。フォント サイズを使用する場合には、見出しの階層を取得することもできます。
- テキストは、その後統一されたヘッダーや段落ブロックで書式設定されます。
ウェブ ページ
ナレッジ抽出サービスは、以下の 3 つの異なる形式の FAQ ウェブ ページをサポートしています。
- 質問と回答の対の組み合わせを含む単純な FAQ ページ
- 同一ページの回答にリンクされた質問のハイパーリンクを含むページ
- 別のページの回答にリンクされた質問のハイパーリンクを含むページ
以下の条件においては、ウェブ ページ上の特定の FAQ 抽出に失敗します。
- 質問のテキストが、FAQ ページの複数の HTML タグで分割されている場合。
- HTML DOM 構造に従って回答に適用されるタグが、抽出された質問の子でも兄弟でもない場合。
- 質問に、回答にリンクされたハイパーリンクがない場合。 (ハイパーリンクを含む FAQ に適用)
- 質問は回答にリンクされているが、質問文が回答上で繰り返されていない場合。 (ハイパーリンクを含む FAQ に適用)
上記の FAQ ページ タイプが 1 つ以上含まれる場合、FAQ ページ全体の抽出に失敗します。





