この機能は、プラットフォームのバージョン7.3でリリースされたもので、![]() (ベータ)状態になっています。
(ベータ)状態になっています。
Kore.aiは、外部のサービスに依存することなく、お客様のデータのニーズを管理します。データ提供により、データテーブル、テーブルビューを定義したり、バーチャルアシスタントから操作したりすることができます。データテーブルを使用すると、カスタムデータを永続化して、必要なときにいつでも取得することができるようになります。これらは、「フィードバック」や「アンケート」のタスク用のデータポイント収集、後で取得可能なユーザー入力の収集などとして使用できます。
ハイライト
- あらゆるビジネスニーズに対応するカスタムデータテーブルを作成します。
- 2つ以上のテーブルを結合して、カスタムデータビューを作成します。
- セキュアフィールド、インデックス、リファレンスをサポートします。
- すべての読み取り、書き込み、更新の要件に対応する、ボットビルダーのダイアログタスクのサービスノードとの組み込み連携。
- データの読み取り、書き込み、更新、削除を行うためのAPI。
- 特定のボットやアプリにテーブルやビューをスコーピングする機能。
このドキュメントでは、Kore.ai ボットプラットフォームにおけるデータテーブルの機能と実装について説明します。データテーブルを段階的に導入するためのユースケースの例に移動するには、こちらをクリックしてください。
概要
Kore.ai ボットプラットフォームで提供するデータ表は、2つのパートに分かれています。
- 以下を含むデータ定義:
- データテーブルとビューの定義。
- これらのテーブルおよびビューからデータを操作するためのボットに対するアクセス権の付与。
- 定義を安全にエクスポート、インポートしたり、ビューやデータテーブルからデータを照会したりするためのアプリの定義。
- データの操作:以下により、データテーブルのデータに対してCRUDオペレーションを実行することができます。
- ダイアログタスク内でサービスノードを使用してボットから
- APIコールを使用して
このドキュメントでは、これらの点についてそれぞれ詳述しています。この機能を利用するには、RDBMSの簡単な知識が必要です。以下に記載されている用語集を参照して、概念を再確認します。
データの定義
データ定義については、ボットビルダーのランディングページのデータタブにアクセスする必要があります。こちらから以下のことができます。
- データテーブルの作成
- テーブルビューの定義
- アクセス用のアプリの作成
![]()
データテーブル作成
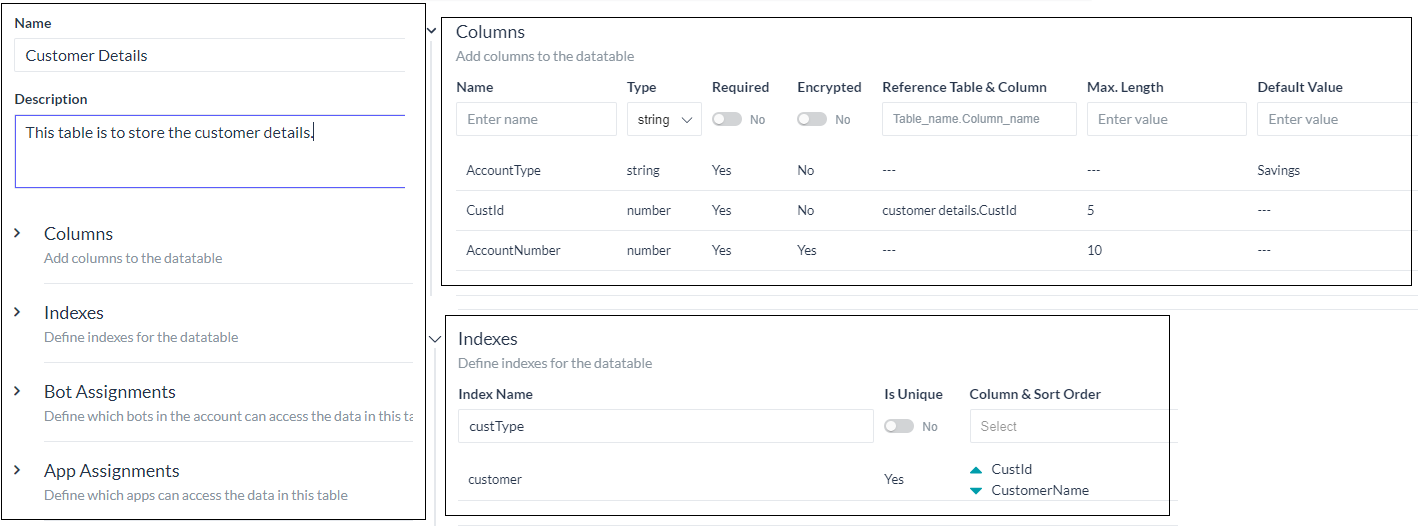
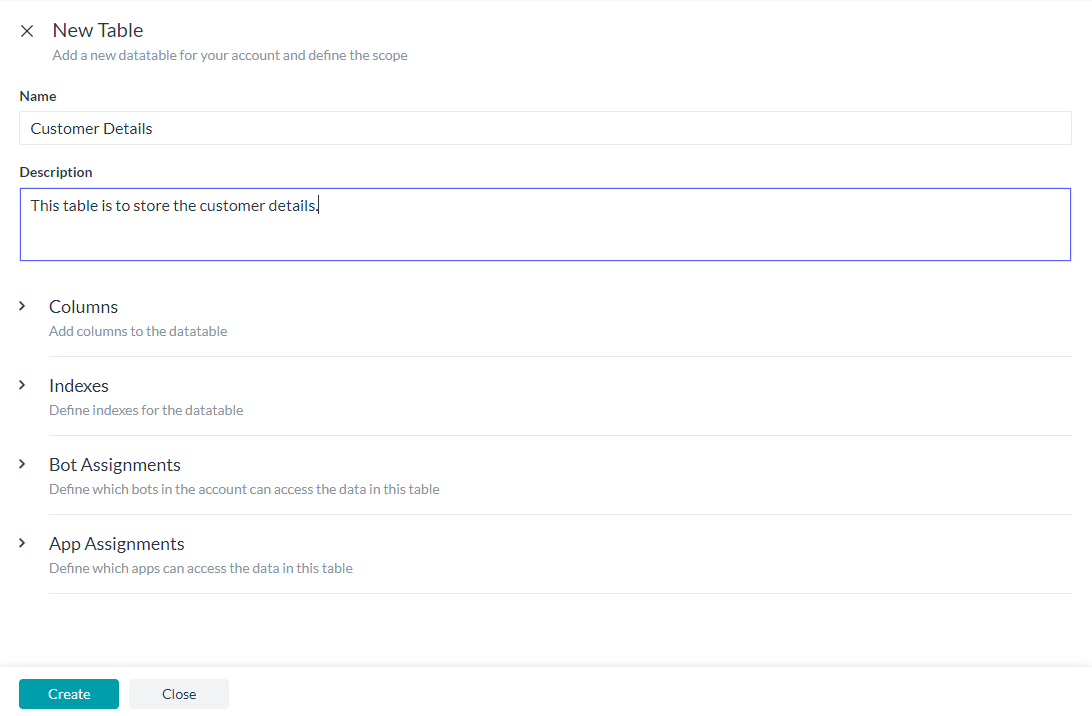
データテーブルの作成をクリックすると、以下の情報を入力する必要がある新規テーブルページが表示されます。
- データテーブルの名前
- データテーブルの説明
- テーブルに含まれる列
- テーブルのインデックス
- このテーブルのデータにアクセスするためのボットの割り当て
- このテーブルのデータにアクセスするためのアプリの割り当て
列の追加
データテーブルの定義に関する2つ目のステップは、テーブルを構成する列を追加することです。列の定義には以下が含まれます。 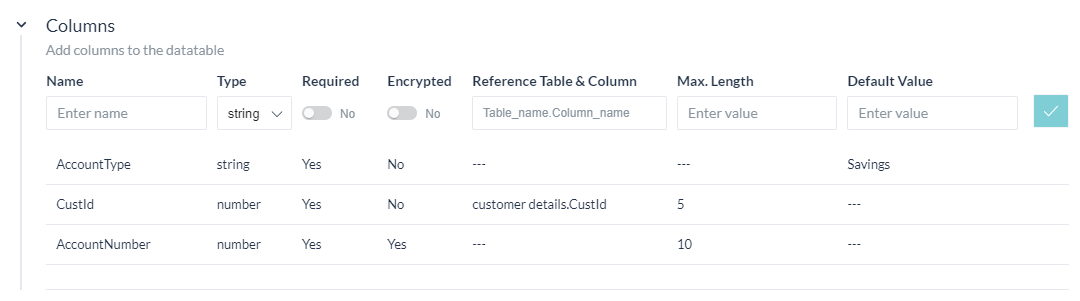
- 列の名前(列の名前に使用できない予約語はこちらをご確認ください)。
- この列に格納できるデータタイプ。以下のいずれかです。
- 文字列
- 日付
- 数字
- 列を必須とするための必須フラグ。
- この列のデータを保護するための暗号化フラグ
- 別のテーブルの列との依存関係を作成する、つまり外部キー制約を追加する参照列これにより、この列に入力された値が、参照されるテーブルの列に存在することが確認されます。
- 列の値の最大の長さを制限する最大長
- 行の追加時に値が見つからない場合のデフォルト値
デフォルトでは、プラットフォームによって以下の列が定義されます。
- sys_Id: テーブルの各行に対してプラットフォームで生成された一意のID。
- Created_On: このテーブルが作成された時のタイムスタンプ。
- Updated_On: このテーブルが更新された時のタイムスタンプ。
- Created_By: このテーブルを作成した開発者のユーザーID。
- Updated_By: このテーブルを最後に更新した開発者のユーザーID。
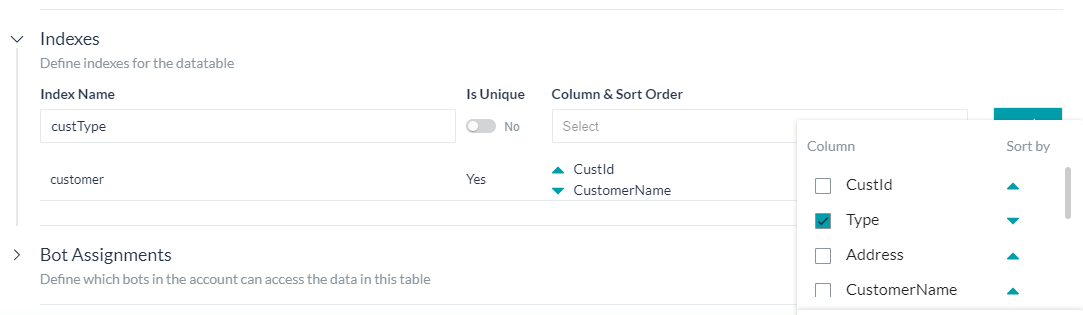
インデックスの定義
データの検索時のパフォーマンスを向上させるために、データテーブルにインデックスを定義することができます。これには以下が含まれます。
- 参照用のインデックス名
- インデックスに一意の値が含まれているかどうかを定義するためのIs Uniqueフラグ
- 列およびソート順 – インデックスに含まれる列一覧。複数の列を選択し、選択した各列のソート順(昇順または降順)を指定することができます。
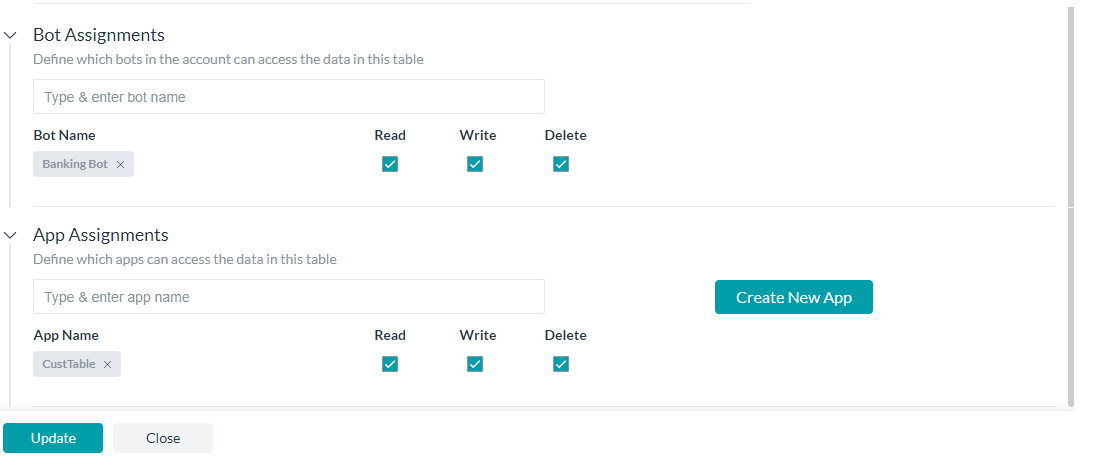
割り当て
各データテーブルの割り当てを以下のように定義することができます。
- ボットの割り当て:
- 読み取り、書き込み、削除の各権限をボットに割り当てます。提示された一覧からボットを選択することができます。これらは、お客様が所有し、共有しているボット一覧になります。
- 割り当てられたボットのみが、そのボットのダイアログタスクのサービスノードを使用して、データテーブルからデータにアクセスすることができます。
- アプリの割り当て:
- 読み取り、書き込み、削除の各権限をアプリに割り当てます。
- 一覧から選択するか、新しくアプリを作成することができます。
- データテーブルのCRUD APIは、アプリに割り当てられたテーブルにのみアクセスできるように制限されます。
インポートおよびエクスポート
データテーブルの定義は、JSON形式のファイルとしてエクスポートおよびインポートすることができます。エクスポート:
- エクスポートしたいテーブル定義の上にカーソルを置きます。
- モアアイコン(省略)をクリックして、定義のエクスポートを選択します。
- JSONファイルが生成され、ダウンロードされます。

インポート:
- 新規テーブルボタンの横にある下矢印をクリックします。
- テーブル定義をインポートオプションを選択します。
- テーブル名を入力し、テーブル定義を含むJSONファイルを選択します。
- インポートをクリックします。

データ定義JSONファイルのサンプル
{"name":"customertable", "description":"Table containing customer details", "indexes":[], "schemaDef":[{"name":"CustEmail", "type":"string", "isRequired":false, "isEncrypted":false, "reference":{}, "maxLength":"", "default":""}, {"name":"CustType", "type":"string", "isRequired":false, "isEncrypted":false, "reference":{}, "maxLength":"", "default":"Preferred"}, {"name":"Address", "type":"string", "isRequired":false, "isEncrypted":false, "reference":{}, "maxLength":"", "default":""}, {"name":"CustName", "type":"string", "isRequired":true, "isEncrypted":false, "reference":{}, "maxLength":"", "default":""}, {"name":"CustId", "type":"number", "isRequired":true, "isEncrypted":true, "reference":{}, "maxLength":"5", "default":""}, {"name":"sys_Id","type":"string","isRequired":true,"readOnly":true}, {"name":"Created_On","type":"date","isRequired":true,"readOnly":true}, {"name":"Updated_On","type":"date","isRequired":true,"readOnly":true}, {"name":"Created_By","type":"string","isRequired":true,"readOnly":true}, {"name":"Updated_By","type":"string","isRequired":true,"readOnly":true}]}
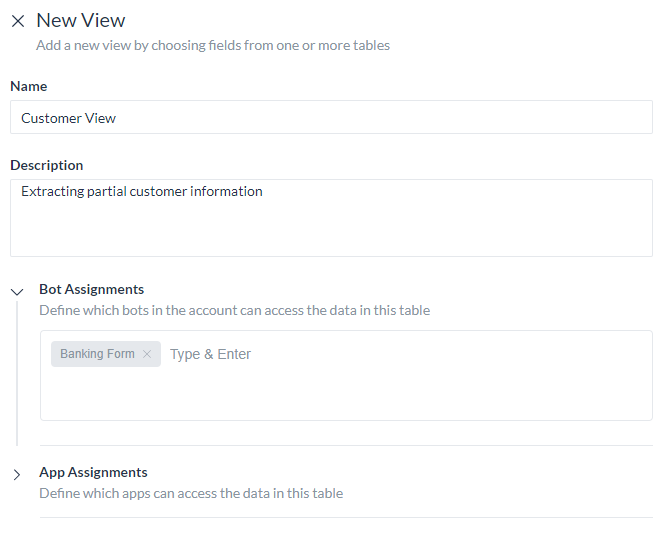
テーブルビューの定義
テーブルビューでは、1つ以上のデータテーブルを結合してカスタムデータセットを作成することができます。これらの定義は、必要な結合を使用して1つ以上のデータテーブルからデータを抽出するためのクエリに変換されます。列の定義には以下が含まれます。
- ビューの名前
- ビューの説明
- ビューにアクセスするボットやアプリの割り当て
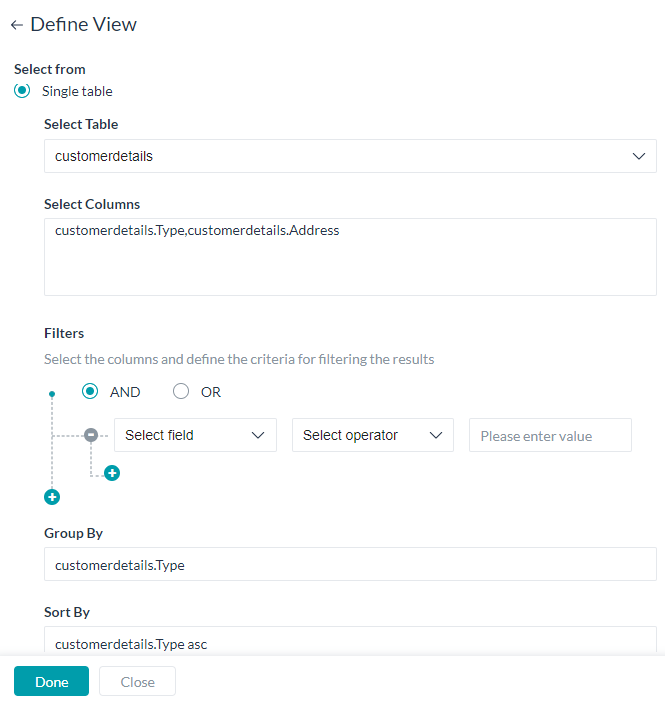
- ビューは、単一のテーブルまたは複数のテーブルから構築することができます。
- どちらのタイプでも、以下のことが必要です。
- テーブルを選択します。
- ビューに含める列を選択します。
sum, avg, min, max and countなどの集計関数を使用することができます。使用例:count(<table_name>.<column_name>) - 以下を使用して結果をフィルタリングするための基準
- 列名 – ドロップダウンリストから選択
- 比較演算子 – 「=」、「!」、「<」、「>」から選択
- 比較値
- AND/OR演算子で接続された複数のフィルター基準を設定することができます。
- 同一のデータを
<table_name>.<column_name>のようにグループ分けするためのグループ列 - 結果を並べ替えるためのソート列
<table_name>.<column_name> asc/desc
- また、複数テーブルビューの場合、以下を設定することで結合基準を指定する必要があります。
- 結合されるテーブル
- 結合タイプ(内側、右外側、左外側)
- 結合列 – ドロップダウンリストから選択
- 「=」「!=」「>」「<」などの演算子を使用して結合基準を指定します。
- 複数の結合条件を持つことができます。最大4つの結合条件を持つことができます。
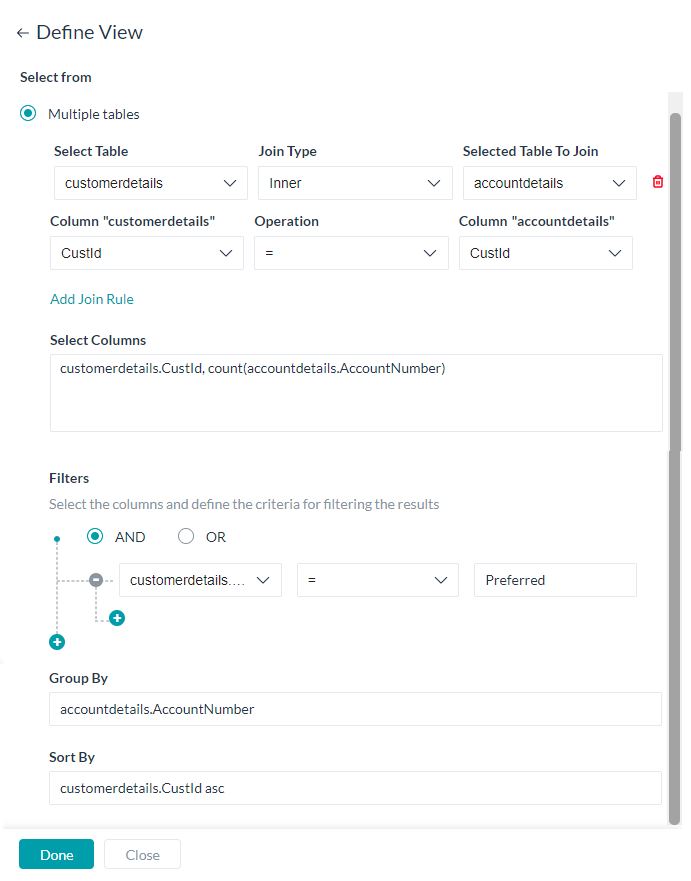
- どちらのタイプでも、以下のことが必要です。
アプリの定義
データテーブルやデータビューからデータに安全にアクセスするためのアプリを定義することができます。これらのアプリは、以下の用途で使用されます。
- 公開されたAPIを介してデータのテーブルやビューへのアクセス
- データテーブルやビューを定義するためのエクスポートおよびインポートAPIへのアクセス
アプリの定義には以下が含まれます。
- アプリ名の入力
- お客様のご要望に応じたJTI/JWEの実施(詳細はこちらを参照してください)
データの操作
データテーブルに存在するデータは、以下の方法で追加、更新、削除することができます。
- ボットの定義 – サービスコール
- APIアクセスの公開
サービスコール – テーブル
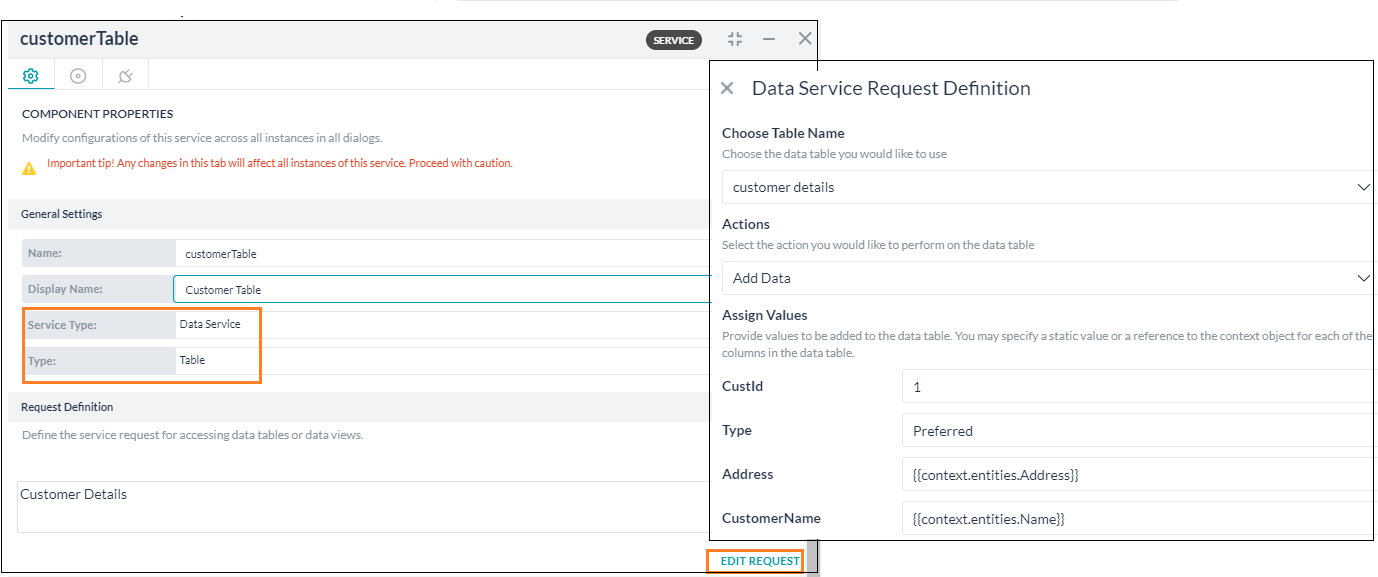
任意のデータテーブル/テーブルビューに割り当てられたボットから、ダイアログタスクのサービスノードを使用して、データを照会したり操作したりすることができます。サービスノードの設定のステップ
- データにアクセスしたいボットとダイアログタスクを開きます。
- プロセスフローの適切な位置にサービスノードを追加します。
- サービスノードの詳細はこちらをクリックしてください。ここでは、データテーブルの統合のための設定についてご紹介します。
- コンポーネントのプロパティの設定
- 基本設定セクション
- 名前 – ノードの名前を入力します。
- 表示名 – ノードの表示名を入力します。
- サービスタイプ – データサービスを選択します。
- タイプ – テーブルを選択します。
- 基本設定セクション
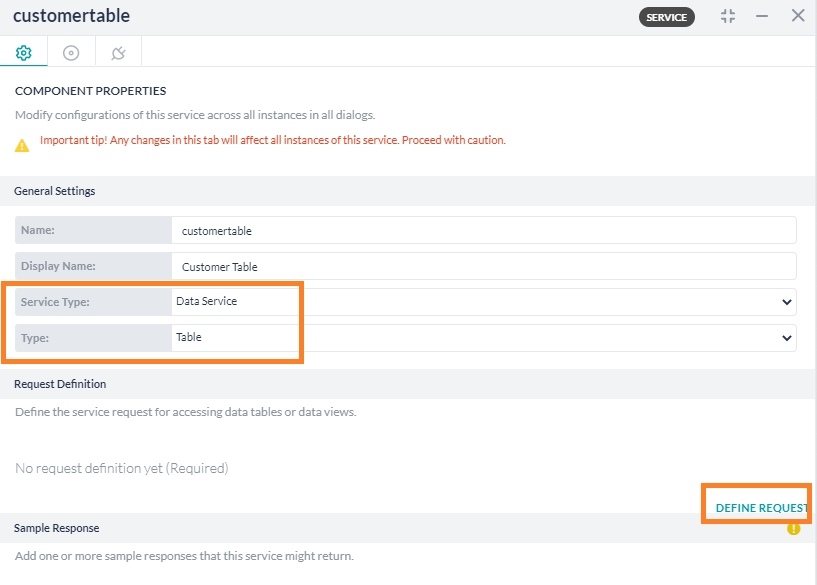
リクエストの定義 – リクエストを定義リンクをクリックしてサービスリクエストを定義します。スライドアウトページでは以下を設定します。
- データテーブルを選択 – このボットに割り当てられているデータテーブルを一覧から選択することができます。
- 動作 – 実行したいアクションを選択します。
- データを追加 – データを追加します(詳細は以下をご確認ください)。
- データを取得 – テーブルからデータを取得します(詳細は以下をご確認ください)。
- データを更新 – 既存のデータを変更します(詳細は以下をご確認ください)。
- データを削除 – データテーブルから行を削除します(詳細は以下をご確認ください)。
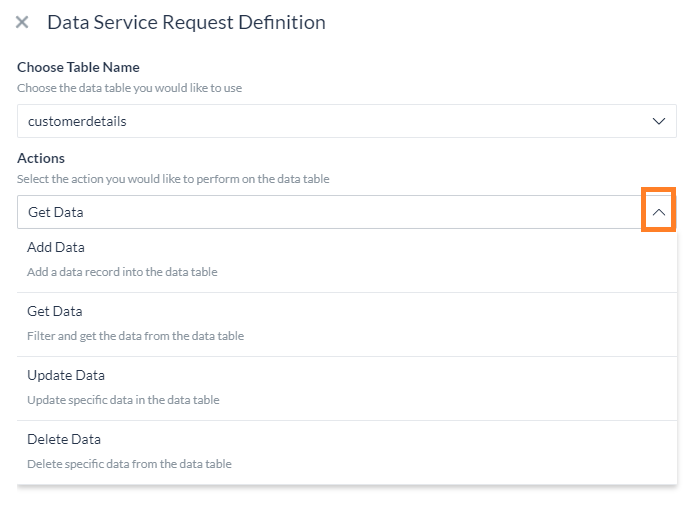
- サービスリクエストをテストすることができます。コンテキスト参照を使用したテストは、実行時に評価されてそれまではデータが利用できないため、失敗することにご留意ください。
- サービスリクエスト定義を保存する
- ボットの要件に応じて、インスタンスプロパティと接続プロパティを設定することができます。
- データテーブルから返されたデータは、コンテキストオブジェクトからアクセスして、必要に応じてタスクで使用することができます。
データを追加する
データを追加するには、以下のことが必要です。
- データテーブルの各列の値を入力します。
- これらの値は、静的なもの、あるいはコンテキストオブジェクトへの参照です。例は以下の通りです。
{{context.entities.<entity-name>}}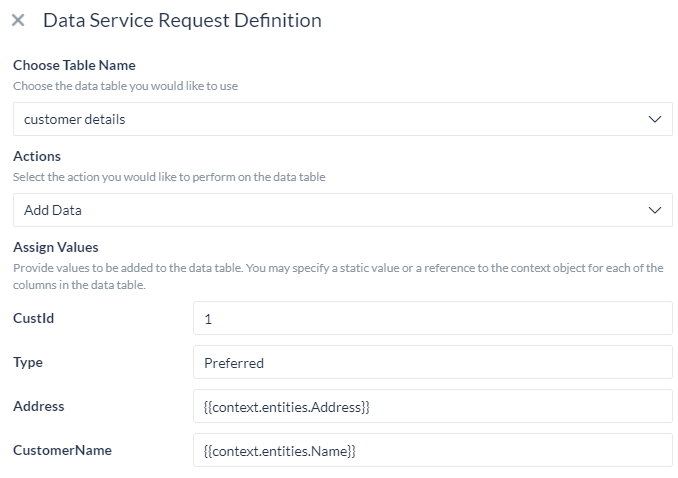
- この電話での応答は、次のようになります。
"stringTable": { "response": { "body": { "CustId": 1, "Type": "Preferred", "Address": "New York", "CustomerName": "John Smith", "Updated_On": 1593687904111, "Created_On": 1593687904111, "Updated_By": "st-b1376ff2-1111-1111-aa34-973ef73212f5", "Created_By": "st-b1376ff2-1111-1111-aa34-973ef73212f5", "sys_Id": "sys-5c46e351-ee51-5c27-80cf-c6c1e8f8f066", "_id": "5efdbf602de5bb5f3f54f728" } } }
データを取得する
テーブルからデータをフィルタリングしたり取得したりするには、以下を行います。
- フィルターを選択して、フィルター基準を定義します。
- 列名 – ドロップダウンリストから選択
- 演算子 – 一覧から選択
- 比較値 – これらの値は、静的なもの、あるいは
{{context.entities.<entity-name>}}のようなコンテキストオブジェクトへの参照です。 - AND/ORコネクタを使用して複数のフィルター基準を定義することができます。
- フィルター基準がない場合、すべての行は、以下で説明する制限値とオフセット値によって制限および取得されます。
- 制限プロパティは、取得するレコード数の上限を設定するために使用します。指定しない場合は、デフォルトで10件のレコードが取得されます。
- オフセットプロパティは、結果のデータセットからスキップされるレコードを指定するために使用します。
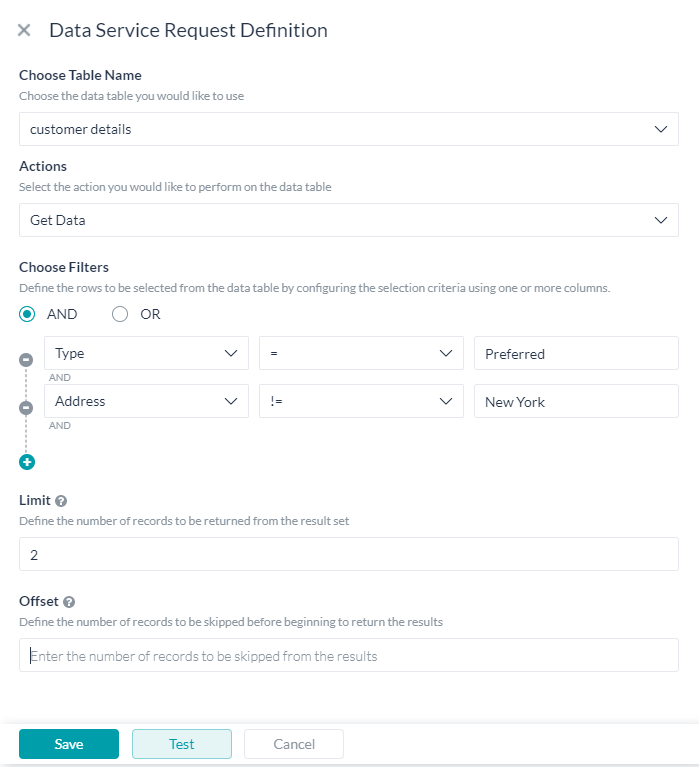
- データの値には、以下の方法でアクセスすることができます。
{{context.<service_node_name>.response.body.queryResult[<index>].<column_name>}} - このサービスでの応答は、次のようになります。
"customerdetails": { "response": { "body": { "hasMore": true, "total": 4, "metaInfo": [ { "name": "City", "type": "string" }, { "name": "Name", "type": "string" }, { "name": "sys_Id", "type": "string" }, { "name": "Created_On", "type": "date" }, { "name": "Updated_On", "type": "date" }, { "name": "Created_By", "type": "string" }, { "name": "Updated_By", "type": "string" } ], "queryResult": [ { "CustId": 1, "Type": "Preferred", "Address": "New York", "CustomerName": "John Smith", "sys_Id": "sys-b088ab59-7640-5a8f-8999-61a265dd2bee", "Created_On": 1593152119161, "Updated_On": 1593152119161, "Created_By": "st-b1376ff2-2384-5541-aa34-973ef73212f5", "Updated_By": "st-b1376ff2-2384-5541-aa34-973ef73212f5" }, { "CustId": 2, "Type": "Privileged", "Address": "Chicago", "CustomerName": "Jane Doe", "sys_Id": "sys-632c69ef-f6dd-5d83-ab32-f7837c8b63f9", "Created_On": 1593152443035, "Updated_On": 1593152443035, "Created_By": "st-b1376ff2-2384-5541-aa34-973ef73212f5", "Updated_By": "st-b1376ff2-2384-5541-aa34-973ef73212f5" } ] } } }
データを更新する
既存のものを変更するには、以下の方法があります。
- 更新される各列に対して値を割り当てます。いずれかの値が空白のままの場合、対応する列の元の値は保持されず、空白に設定されます。
- これらの値は、静的なもの、あるいはコンテキストオブジェクトへの参照です。
- フィルターを選択して、以下を使用して更新する行を指定するためのフィルター基準を定義します。
- 列名
- 演算子
- フィルター値 – これらの値は、静的なもの、あるいは
{{context.entities.<entity-name>}}のようなコンテキストオブジェクトへの参照です。 - AND/ORコネクタを使用して複数のフィルター基準を定義することができます。
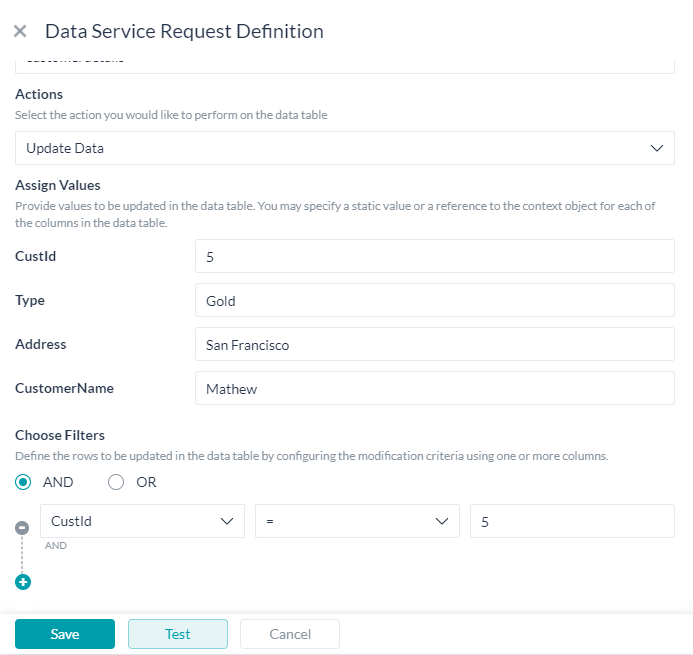
- このサービスでの応答は、次のようになります。
"customerdetails": { "response": { "body": { "records": [] } } }
データを削除する
データテーブルから行を削除するには、以下の方法があります。
- 以下を使用して削除する行を指定するためのフィルター基準を定義する
- 列名
- 演算子
- フィルター値。これらの値は、静的なもの、あるいは
{{context.entities.<entity-name>}}のようなコンテキストオブジェクトへの参照です。AND/ORコネクタを使用して複数のフィルター基準を定義することができます。
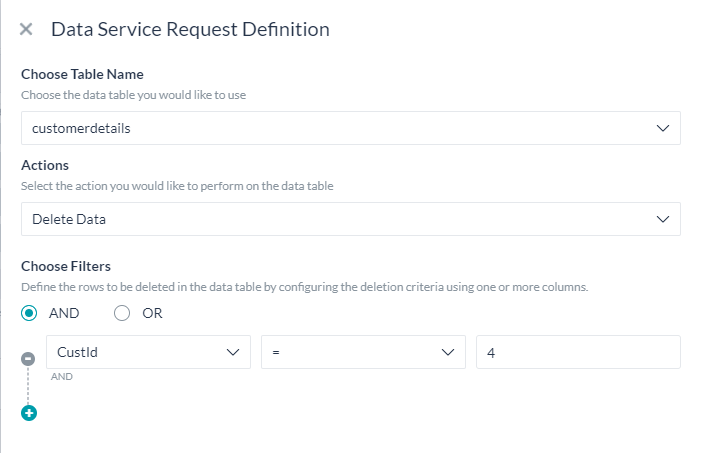
- このサービスリクエストからの応答は、次のようになります。
"customerdetails": { "response": { "body": { "nDeleted": 1 } } }
サービスコール – ビュー
任意のデータテーブル/テーブルビューに割り当てられたボットから、ダイアログタスクのサービスノードを使用して、データを照会したり操作したりすることができます。サービスノードの設定のステップ
- データにアクセスしたいボットとダイアログタスクを開きます。
- プロセスフローの適切な位置にサービスノードを追加します。
- サービスノードの詳細はこちらをクリックしてください。ここでは、データテーブルの統合のための設定についてご紹介します。
- コンポーネントのプロパティの設定
- 基本設定セクション
- 名前 – ノードの名前を入力します。
- 表示名 – ノードの表示名を入力します。
- サービスタイプ – データサービスを選択します。
- タイプ – ビューを選択します。
- リクエストの定義 – リクエストを定義リンクをクリックしてサービスリクエストを定義します。
- スライドアウトページでは以下を設定します。
- テーブルビューを選択 – このボットに割り当てられているテーブルビューを一覧から選択することができます。
- 結果のフィルタリング – 以下を使用してフィルター基準をさらに定義することができます。
- 列名
- 演算子
- フィルター値 – これらの値は、静的なもの、あるいは
{{context.entities.<entity-name>}}のようなコンテキストオブジェクトへの参照です。
- AND/ORコネクタを使用して複数のフィルター基準を定義することができます。
- フィルター基準がない場合、すべての行は、以下で説明する制限値とオフセット値によって制限および取得されます。
- 取得したレコード数に制限を設定することができます。
- オフセット値を指定することで、結果データセットからいくつかのレコードをスキップすることができます。
- サービスリクエストをテストすることができます。コンテキスト参照を使用したテストは、実行時に評価されてそれまではデータが利用できないため、失敗することにご留意ください。
- サービスリクエスト定義を保存する
- 基本設定セクション
- ボットの要件に応じて、インスタンスプロパティと接続プロパティを設定することができます。
- データテーブルから返されたデータは、コンテキストオブジェクトからアクセスして、以下を使用して必要に応じてタスクで使用することができます。
{{context.<service_node_name>.response.body.queryResult[<index>].<column_name>}} - このサービスでの応答は、次のようになります。
"CustomerView": { "response": { "body": { "hasMore": true, "total": 4, "metaInfo": [ { "name": "type", "type": "string" }, { "name": "address", "type": "string" } ], "queryResult": [ { "type": "Gold", "address": "New York" }, { "type": "Gold", "address": "Chicago" }, { "type": "Gold", "address": "Chicago" } ] } } }
APIアクセス
データテーブルやデータビューのデータにアクセスするためのAPIは以下の通りです。
- データ挿入API – 詳細はこちらをご確認ください
- データ更新API – 詳細はこちらをご確認ください
- データ削除API – 詳細はこちらをご確認ください
- テーブルからのクエリデータ – 詳細はこちらをご確認ください
- ビューからのクエリデータ – 詳細はこちらをご確認ください
予約語
以下は、予約語であり、列の名前として使用することができない単語の一覧です。
- ACCESS
- ADD
- ALL
- ALTER
- AND
- ANY
- AS
- ASC
- AUDIT
- BETWEEN
- BY
- CHAR\
- CHECK
- CLUSTER
- COLUMN
- COMMENT
- COMPRESS
- CONNECT
- CREATE
- CURRENT
- DATE
- DECIMAL
- DEFAULT
- DELETE
- DESC
- DISTINCT
- DROP
- ELSE
- EXCLUSIVE
- EXISTS
- FILE
- FLOAT
- FOR
- FROM
- GRANT
- GROUP
- HAVING
- IDENTIFIED
- IMMEDIATE
- IN
- INCREMENT
- INDEX
- INITIAL
- INSERT
- INTEGER
- INTERSECT
- INTO
- IS
- LEVEL
- LIKE
- LOCK
- LONG
- MAXEXTENTS
- MINUS
- MLSLABEL
- MODE
- MODIFY
- NOAUDIT
- NOCOMPRESS
- NOT
- NOWAIT
- NULL
- NUMBER
- OF
- ONLINE
- ON
- OFFLINE
- OPTION
- ON
- ORDER
- PCTFREE
- PRIOR
- PRIVILEGES
- PUBLIC
- RAW
- RENAME
- RESOURCE
- REVOKE
- ROW
- ROWID
- RONUM
- ROWS
- SELECT
- SESSION
- SET
- SHARE
- SIZE
- SMALLINT
- START
- SUCCESSFUL
- SYNONYM
- SYSDATE
- TABLE
- THEN
- TO
- TRIGGER
- UID
- UNION
- UNIQUE
- UPDATE
- USER
- VALIDATE
- VALUES
- VARCHAR
- VARCHAR2
- VIEW
- WHENEVER
- WHERE
- WITH
用語集
以下は、プラットフォームで使用されている用語とその定義です。
| 用語 | 定義 |
|---|---|
| データの定義 | データ定義では、テーブル、列、ビューなどの観点からデータの格納方法の定義について扱います。 |
| データの操作 | データの操作とは、データの取得、更新、削除など、日付に対して実行可能な基本的なCRUD操作のことです。 |
| データテーブル | 行および/または列の名前が付いた表形式でデータにアクセスできるデータストレージ。 |
| 列 | 列名とは、テーブルに格納されている個々のフィールド値を指します。 |
| リファレンステーブルおよび列 | これは、参照している列に対するドメインを表しています。つまり、参照されている列の値は、リファレンステーブルの列に含まれています。 |
| インデックス | インデックスとは、テーブル内のデータへのポインタであり、データの検索を高速化するために使用されます。テーブルの行を特定するのに最適だと思われる列を割り当てます。 |
| テーブルビュー | 単一のテーブルから情報のサブセットにアクセスしたり、結合を使用して2つ以上のテーブルからデータを組み合わせたりするために使用可能なバーチャルテーブルです。 |
| フィルター基準 | ビューを定義する際に、このプロパティを使用して結果のデータセットを定義することができます。つまり、指定された列の値に基づいてビューに含まれる行を定義することができます。 |
| グループ別 | ビューを定義する際に、このプロパティを使用して、結果のデータセットから同一のデータをグループに対して配置することができます。 |
| 並べ替え方法 | ビューを定義する際に、このプロパティを使用して、指定された列に基づいて結果のデータセットの行を配置することができます。 |
| 結合 | ビューを定義する際に、結合は2つ以上のテーブルからデータを取得するために使用し、単一のデータセットとして表示するために結合することができます。 |
| 内部結合 | これはシンプルな結合であり、結果は、等価条件に従って2つのテーブル間で一致したデータに基づいています。 |
| 右外部結合 | 右外部結合は、2つのテーブル間で一致したデータ、次に右テーブルの残りの行、および対応する左テーブルの列からのnullを含む結果セットを返します。 |
| 左外部結合 | 左外部結合は、2つのテーブル間で一致したデータ、次に左テーブルの残りの行、および対応する右テーブルの列からのnullを含む結果セットを返します。 |

