Threshold & Configurations
To train and improve the performance, Threshold and Configurations can be specified for all three NLP engines – FM, KG, and ML. You can access these settings from Natural Language > Training > Thresholds & Configurations.
NOTE: If your bot is multilingual, you can set the Thresholds differently for different languages. If not set, the Default Settings will be used for all languages. This feature is available from v7.0 onwards.
The settings for the Knowledge Graph engine are discussed in detail in the following sections.
Navigate to Threshold and Configurations
- Open the bot for which you want to configure Knowledge Graph settings.
- Hover over the left pane and click Natural Language > Training.
- Click the Thresholds & Configurations tab.
- Below is a detailed discussion about the Knowledge Graph section on this page.
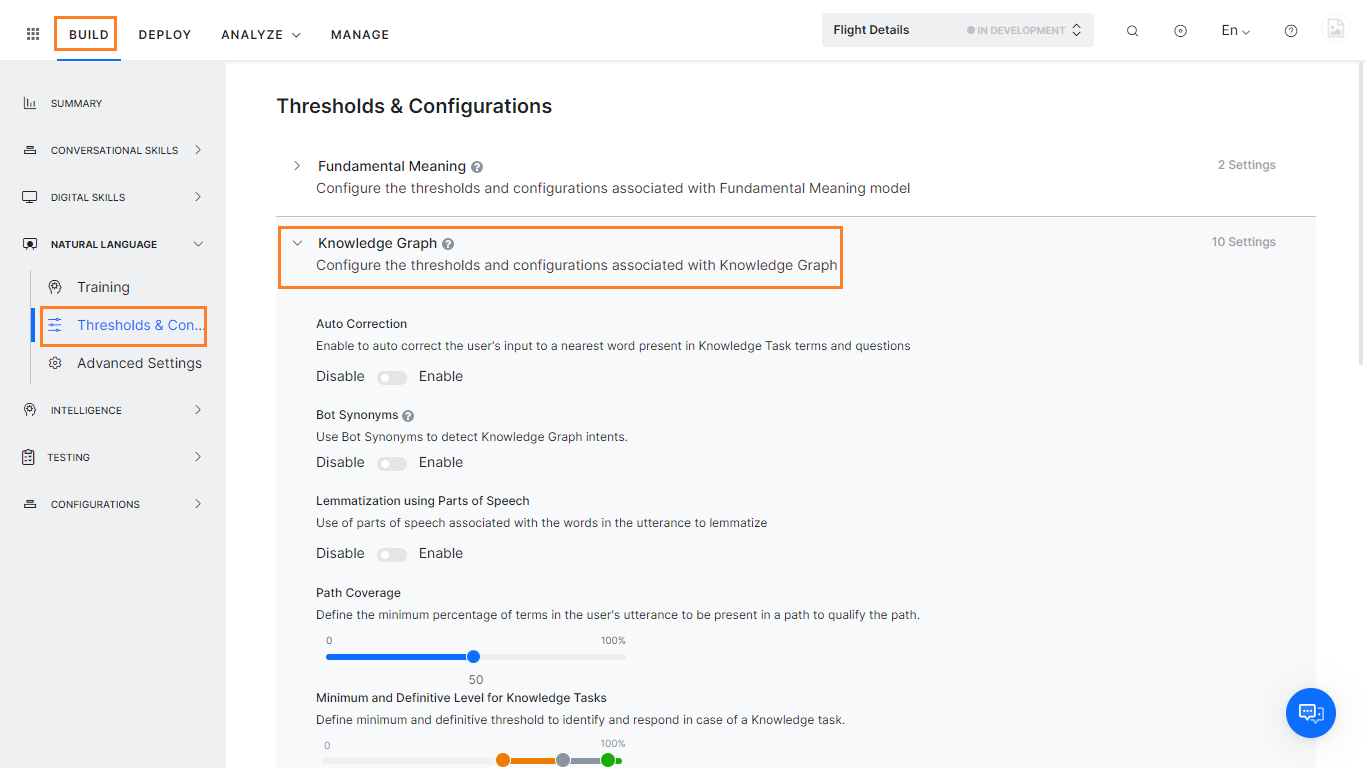
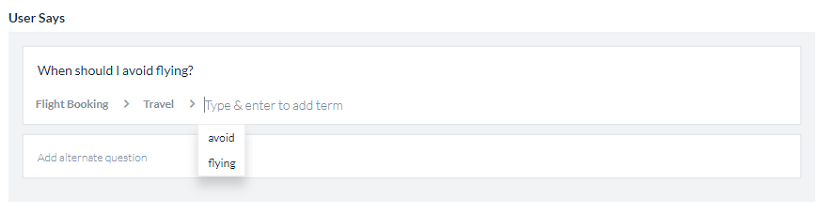
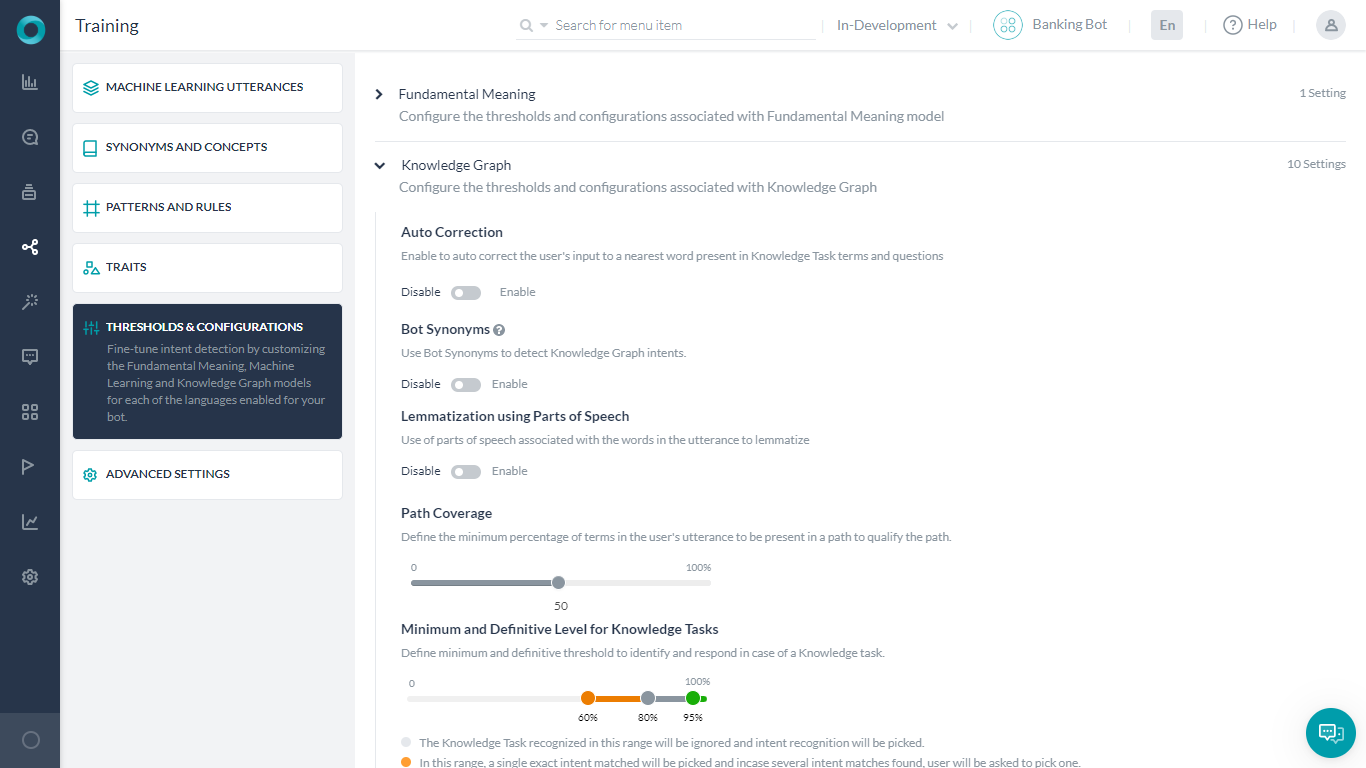
Auto-Correction will spell correct the words in the user input to the closest matching word from the bot’s Knowledge Graph domain dictionary. Knowledge Graph domain dictionary comprises of the words extracted from Knowledge Graph’s questions, alternate questions, nodes, and synonyms.
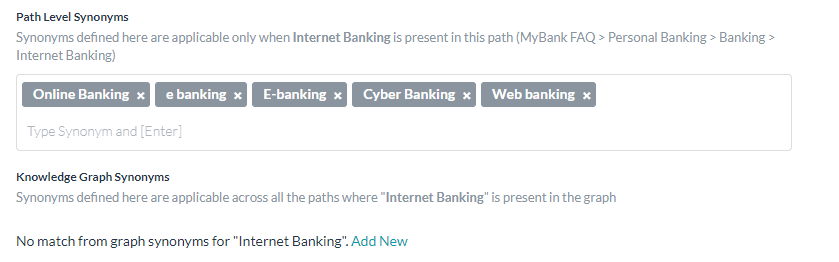
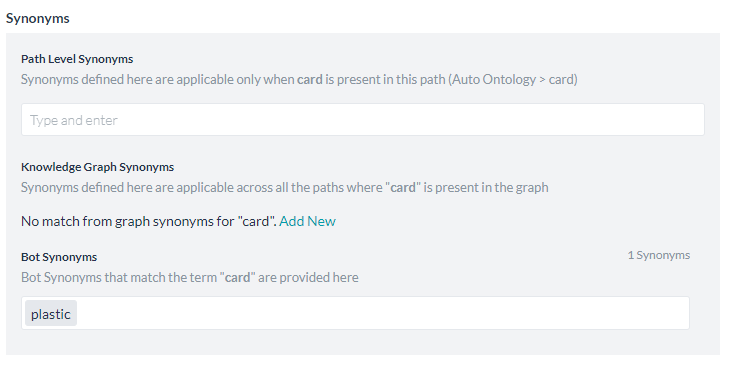
Bot Synonyms will enable the Bots platform to use the Bot Synonyms in Knowledge Graph as well. Inclusion of Bot Synonyms for intent detection by the KG engine requires training. Click Proceed when prompted to enable this setting and initiate training.
Lemmatization using Parts of Speech will enable the use of parts of speech associated with the words in the utterance to lemmatize. (see below for more)
Path Coverage can be used to define the minimum percentage of terms in the user’s utterance to be present in a path to qualify it for further scoring. The default setting is 50% i.e. at least half of the terms in the user utterance should match the node names and terms.
Minimum and Definitive Level for Knowledge Graph Intent allows you to set the confidence levels for a Knowledge Graph intent. You can view and adjust the confidence level percentages for the graph in one of three ranges:
- Definitive Range – Matches in this range (green area) are picked and any other probable matches are discarded, default set to 93-100%.
- Probable Range – Matches in this range (dark gray area) are considered for rescoring and ranking, by default set to 80-93%
- Low Confidence Range – If no other intents have matched, low confidence matches (orange area) are presented to end-user for intent confirmation, by default set to 60-80%
- Not Matching an Intent – The light gray area represents the knowledge graph intent NLP interpreter confidence levels as too low to match the knowledge graph intent, default set to 60%.
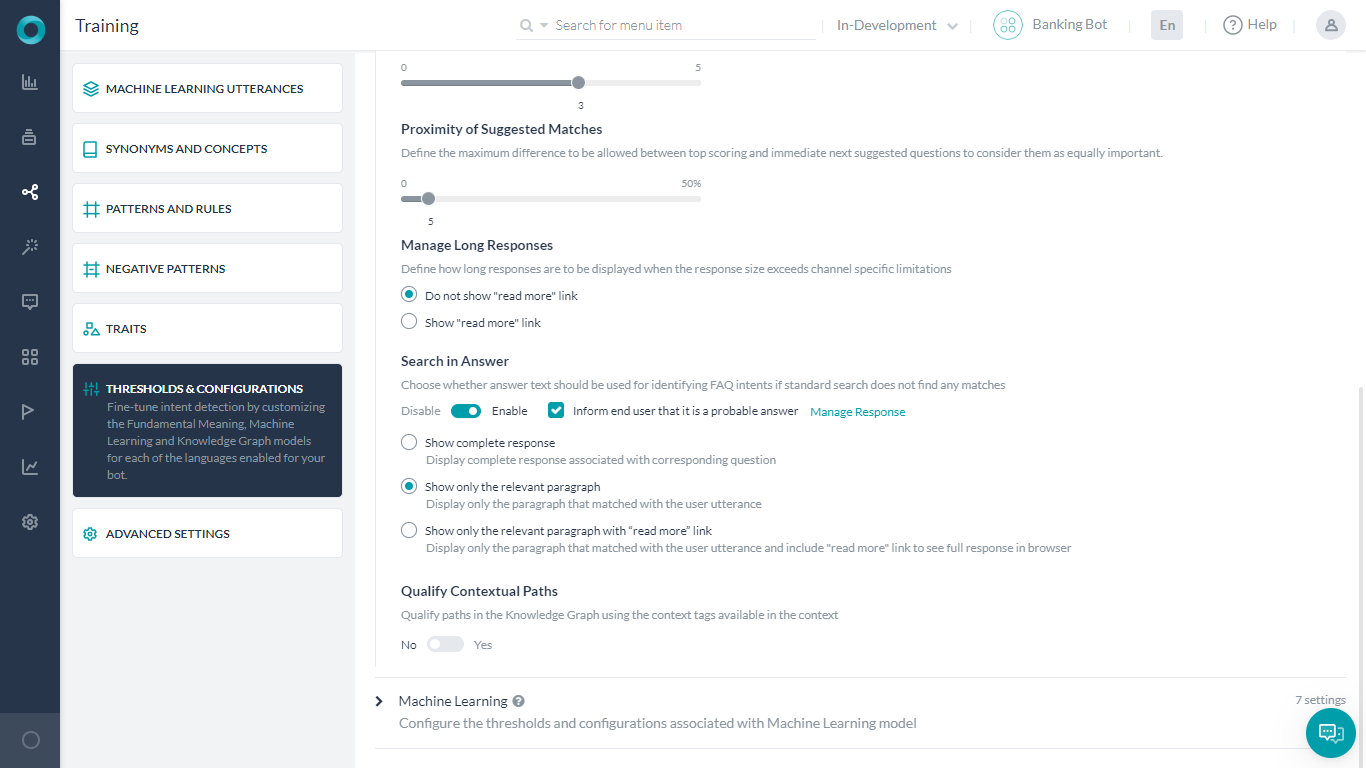
KG Suggestions Count: Define the maximum number of KG/FAQ suggestions (up to 5) to be presented when a definite KG intent match is not available. Default set to 3.
Proximity of Suggested Matches: Define the maximum difference (up to 50%) to be allowed between top-scoring and immediate next suggested questions to consider them as equally important. Default set to 5%. This applies to the matches in the probable range.
Manage Long Responses when the response size exceeds channel-specific limitations. You can choose to truncate the response or display the full response with a Read More link. The link is included at the end of the message. On clicking this link, the complete response is displayed as an answer in the browser. The URL that displays the long response in a web browser is set by default by the platform, but you can provide a custom URL too.
The following table provides the channel-specific limitations set for the length of the response messages. The Read More link is displayed at the end of the message if the complete response crosses the set limit.
| Channel |
Message Limit (in characters) |
| Facebook |
1900 |
| Google Assistant |
540 |
| Web/Mobile Client |
900 |
Note: For all other channels, there is no restriction to the length of the message. The entire response would be displayed on the same page.
Search in Answer for the qualifying FAQs (see below for more)
Qualify Contextual Paths in the Knowledge Graph using the context tags available in the context. Enabling this option will ensure that the paths are shortlisted using terms or tags from the context. These tags can come from previous matched paths or intent or custom-defined tags.
The platform also offers some advanced configurations. Refer here for more details.