Kore.ai 지식 그래프를 사용하면 정적 FAQ 텍스트를 지능적이고 개인화된 대화 경험으로 바꿀 수 있습니다. Kore.ai 지식 그래프는 일반적인 질문-답변 쌍의 형태로 FAQ를 캡처하는 일반적인 방식을 넘어섭니다. 대신에, 지식 그래프는 주요 도메인 용어의 온톨로지 구조를 만들고 이 구조를 상황에 맞는 질문과 해당 대체어, 동의어, 기계 학습 가능한 특성과 연관 짓습니다. 이 플랫폼에서 교육을 받은 경우 그래프는 지능형 FAQ 경험을 지원합니다. 이 문서는 지식 그래프의 개념, 용어 및 구현을 설명합니다. 지식 그래프에 대한 사용 사례 중심의 접근 방법은 여기를 참조하십시오.
지식 그래프를 사용하는 이유는 무엇입니까?
사용자는 다양한 방법으로 쿼리를 표현합니다. 모든 대체 질문을 수동으로 시각화하고 추가하는 것은 어려운 작업입니다. Kore.ai는 가능한 모든 일치 항목을 쉽게 처리할 수 있도록 노드, 태그 및 동의어를 포함하는 지식 그래프를 설계했습니다. 지식 그래프는 노드, 태그 및 동의어를 사용하여 학습을 통해 다양한 대체 질문을 처리할 수 있습니다. 사용자가 질문을 할 때마다 지식 그래프의 노드 이름을 확인하고 사용자 발화의 키워드와 일치시킵니다. 노드 이름, 태그 및 동의어를 확인하고 스코어링을 기준으로 질문을 가장 일치하는 항목 또는 의도가 있는 항목으로 선정합니다. 그런 다음 이러한 선정된 질문을 실제 사용자 발화와 비교하여 사용자에게 제시할 수 있는 가능한 최적의 의도를 제시합니다. 응답은 단순 응답 또는 대화 작업 실행의 형식을 취할 수 있습니다. 이렇게 하면 FAQ에 완전히 다른 대체 질문을 몇 개 추가하고 태그, 동의어 및 노드 이름을 적절히 제공하여 학습하지 않은 질문도 일치시킬 수 있습니다. 지식 그래프의 성능과 지능은 적절한 노드 이름, 태그 및 동의어를 사용하여 학습하는 방법에 따라 달라집니다.
용어
이 문서는 읽는 사람이 지식 그래프 작성에 사용되는 용어에 익숙해지도록 돕기 위한 것입니다. KG 생성으로 바로 가기.
용어 또는 노드
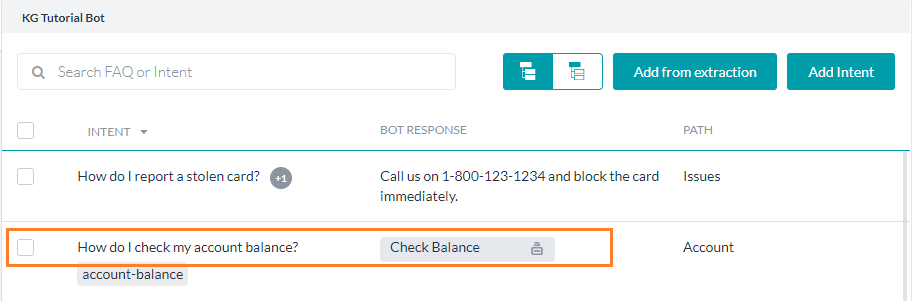
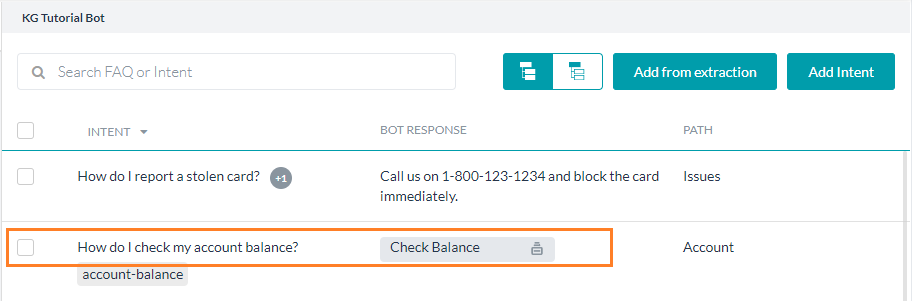
용어 또는 노드는 온톨로지의 구성 요소로, 비즈니스 도메인의 기본 개념과 카테고리를 정의하는 데 사용됩니다. 아래 이미지와 같이, 조직의 정보 흐름을 나타내기 위해 봇 온톨로지 창의 왼쪽 창에서 용어를 계층적 순서로 구성할 수 있습니다. 여기서 용어를 생성, 구성, 편집 및 삭제할 수 있습니다. 최대 노드 수 20k개와 FAQ 수 50k개의 플랫폼 제한이 있습니다. 보다 쉽게 표현하기 위해 다음과 같은 이름을 사용하여 몇 가지 특수 노드를 식별합니다. 
루트 노드
루트 노드는 봇 온톨로지의 최상위 용어를 이루고 있습니다. 지식 그래프는 하나의 루트 노드로 구성되며 온톨로지의 다른 모든 노드는 자식 노드가 됩니다. 루트 노드는 기본적으로 봇의 이름을 사용하지만 원하는 경우 변경할 수 있습니다. 이 노드는 노드 정규화 또는 처리에 사용되지 않습니다. 경로 정규화는 첫 번째 수준 노드에서 시작됩니다. 루트 노드 바로 아래에 FAQ를 두는 것은 바람직하지 않지만, 필요한 경우를 대비해 루트 노드에서 FAQ 수를 최대 100개로 제한하시기 바랍니다.
첫 번째 수준 노드
루트 노드의 바로 다음 수준 노드를 첫 번째 수준 노드라고 합니다. 컬렉션에는 여러 개의 첫 번째 수준 노드가 있을 수 있습니다. 부서 이름이나 기능과 같은 상위 수준의 용어를 나타내려면 첫 번째 수준의 노드를 보관하는 것이 좋습니다. 예: 개인 뱅킹, 온라인 뱅킹, 기업 뱅킹.
리프 노드
질문 답변 집합 또는 대화 작업이 추가되는 모든 노드를 리프 노드라고 하며, 어느 수준에나 존재합니다.
노드 관계
온톨로지에서의 위치에 따라 노드는 첫 번째 수준 노드, 두 번째 수준 노드 등으로 부릅니다. 첫 번째 수준 노드는 두 번째 수준 노드라고 부르는 하나 이상의 하위 카테고리를 가진 카테고리입니다. 예를 들어 대출은 주택 대출과 개인 대출의 첫 번째 수준 노드입니다. 개인 대출은 다시 두 개의 하위 카테고리 노드를 가질 수 있습니다. 요금 및 수수료, 도움말 및 지원.
참고 사항: 노드의 계층적 구조는 관련 질문을 함께 보관할 수 있는 편의성을 제공합니다. 지식 그래프 엔진은 일치하는 질문을 평가하는 동안 상위-하위 관계를 고려하지 않습니다. 모든 노드가 FAQ 구조의 위치와 관계없이 동일한 방식으로 고려되므로 계층은 FAQ 일치를 처리하는 데 어떠한 영향도 미치지 않습니다.
태그
각 용어/노드에 대해 사용자 정의 태그를 추가할 수 있습니다. 태그는 용어와 정확히 같게 작동하지만 혼란을 피하기 위해 지식 그래프 온톨로지에는 나타나지 않습니다. 용어와 마찬가지로 동의어와 특성을 태그에 추가할 수 있습니다.
동의어
사용자는 자신의 온톨로지 용어로 다양한 대체어를 사용합니다. 지식 그래프를 통해 가능한 모든 대체어 형태의 용어를 포함하도록 용어의 동의어를 추가할 수 있습니다. 동의어를 추가하면 대체 질문으로 봇을 교육시킬 필요가 줄어듭니다. 예를 들어 인터넷 뱅킹 노드에는 다음 동의어가 추가될 수 있습니다. 온라인 뱅킹, 전자 뱅킹, 사이버 뱅킹 및 웹 뱅킹. 지식 그래프에서 용어의 동의어를 추가할 때 로컬 또는 전역 동의어로 추가할 수 있습니다. 로컬 동의어 또는 경로 수준(동의어)는 해당 특정 경로의 용어에만 적용되는 반면 전역 동의어 또는 지식 그래프(동의어)는 온톨로지의 다른 경로에 나타나는 경우에도 용어에 적용됩니다. 7.2 출시 이후에는 경로 정규화 및 질문 일치를 위해 지식 그래프 엔진 내에서 봇 동의어를 사용하도록 설정할 수 있습니다. 이 설정을 사용하면 봇 동의어 및 KG 동의어에서 동일한 동의어 집합을 다시 만들 필요가 없습니다.
특성
참고 사항: v7.0부터 특성은 v6.4 이하의 클래스를 대체하는 것입니다. 특성은 특정 의도와 관련된 정보를 요청할 때 질문의 성격을 정의하는 일반적인 최종 사용자 발화의 모음입니다. 특성에 대한 자세한 내용은 여기를 참조하세요. 특성은 봇 온톨로지의 여러 용어에 적용됩니다.
참고 사항: 또한 특성은 연결된 사용자 발화를 기반으로 노드를 필터링하는 데 도움이 됩니다. 따라서 사용자가 특성이 있는 발화를 입력하면 해당 특성이 적용되는 노드만 검색합니다. 특성이 적용되지 않는 다른 노드에 발화가 있는 봇은 해당 노드를 무시합니다.
의도
봇은 대화 작업 또는 FAQ를 실행하여 사용자의 질문에 응답할 수 있습니다.
- FAQ: 봇 온톨로지의 관련 노드에 질문-답변 쌍을 추가해야 합니다. 최대 50k개의 FAQ가 허용됩니다. 사용자마다 질문이 다르게 제시되며, 이를 지원하려면 각 질문마다 여러 대체어 형태를 연결해야 합니다. 대체 질문 앞에 ||를 추가하여 FAQ(릴리스 버전 7.2 이후)의 패턴을 입력할 수 있습니다.

- 작업: 대화 작업을 KG 의도와 연결하면 지식 그래프와 대화 작업의 기능을 활용하여 복잡한 대화가 포함된 FAQ를 처리하는 데 도움이 됩니다.
성능 개선
지식 그래프 엔진은 기본 설정에서 원활하게 작동됩니다. 봇 개발자는 다양한 방법으로 KG 엔진 성능을 미세 조정할 수 있습니다.
- 용어, 동의어, 기본 질문과 대체 질문 또는 사용자 발화를 정의하여 지식 그래프를 설정합니다. 계층은 KG 엔진 성능에 영향을 미치지 않지만 KG 엔진 작업을 구성하고 안내하는 데 도움이 됩니다.
- 다음 매개 변수 설정:
- 경로 범위 – 추가 스코어링을 위해 경로에 존재하는 사용자 발화 용어의 최소 백분율을 정의합니다.
- KG 확정 스코어링 – KG 의도 일치에 대한 최소 스코어링을 정의하여 확실한 일치로 간주하고 다른 의도 일치를 삭제합니다.
- 지식 작업에 대한 최소 및 명확한 수준 – 지식 작업의 경우 식별하고 대응하기 위한 최소 및 확정 임계값을 정의합니다.
- KG 제안 수 – 명확한 KG/FAQ 일치를 사용할 수 없을 때 표시하는 최대 KG/FAQ 제안 수를 정의합니다.
- 제안된 일치에 근접함 – 똑같이 중요한 것으로 취급하기 위해 최고 점수와 바로 다음 제안된 질문 사이에 허용되는 최대 차이를 정의합니다.
플랫폼은 위에서 언급한 임계값에 대한 기본값을 제공하지만 자연어 > 학습 > 임계값 및 설정에서 사용자 정의할 수 있습니다.
- 컨텍스트 경로 확인 – 이렇게 하면 일치하는 의도의 용어/노드로 봇 컨텍스트가 채워지고 유지됩니다. 이렇게 하면 사용자 경험이 더욱 향상됩니다.
- 특성 – 앞에서 언급한 대로 사용자 발화가 용어/노드를 포함하지 않더라도 특성은 노드/용어를 확인하는 데 사용됩니다. 특성은 제안된 의도 목록을 필터링하는 데도 유용합니다.
KG 엔진 작업
지식 그래프 엔진은 사용자 발화에 대한 올바른 응답을 추출하는 동시에 2단계 접근 방법을 사용합니다. 검색 기반 의도 감지 프로세스와 규칙 기반 필터링을 결합합니다. 사용자 발화의 경로 적용 범위(필요한 용어의 비율) 및 용어 사용(필수 또는 선택 사항)에 대한 설정은 FAQ 의도의 초기 필터링에 도움이 됩니다. 토큰화 및 n-그램 기반 코사인 스코어링 모델은 최종 검색 기준을 충족하는 데 도움이 됩니다. 지식 그래프 학습에는 다음 단계가 포함됩니다.
- 동의어와 함께 모든 용어/노드가 식별되고 인덱싱됩니다.
- 이러한 인덱스를 사용하여 각 KG 의도에 대해 평평한 경로가 설정됩니다.
지식 그래프 엔진이 사용자 발화를 수신하는 경우:
- 사용자 발화 및 KG 노드/용어는 토큰화되고 n-그램이 추출됩니다(지식 그래프 엔진은 최대 쿼드 그램까지 지원).
- 토큰은 KG 노드/용어와 매핑되어 각각의 인덱스를 얻습니다.
- 사용자 발화와 KG 노드/용어 간의 경로 비교는 해당 발화를 위한 정규화된 경로를 설정합니다. 이 단계에서는 위에서 언급한 경로 적용 범위 및 용어 사용을 고려합니다.
- 정규화된 경로의 질문 목록에서 코사인 점수를 기준으로 가장 일치하는 항목이 선택됩니다.
Kore.aiナレッジグラフは、静的なFAQテキストを、インテリジェントでパーソナライズされた会話体験に変えるのに役立ちます。それは、FAQを平面的な質問・回答ペアの形式でキャプチャするという、通常の実践を超えています。その代わりに、ナレッジグラフでは、主要な業界用語のオントロジー構造を作成し、コンテキストに応じた質問およびその代替語、同義語、機械学習対応の示唆などと関連付けることができます。このグラフは、プラットフォームでトレーニングすると、インテリジェントなFAQ体験を実現できます。この文書は、ナレッジグラフの概念、用語、および実装について説明しています。ナレッジグラフのユースケースに基づいたアプローチについては、 こちらをご参照ください。
なぜナレッジグラフなのですか?
ユーザーは複数の方法でクエリを表現します。すべての代替質問を手動で可視化して追加するのは、困難なタスクです。Kore.aiは、ナレッジグラフをノード、タグ、同義語で設計しており、すべての一致の可能性が適用されるための作業を簡易化しています。ナレッジグラフは、ノード、タグ、および同義語を使用したトレーニングにより、さまざまな代替質問を処理することができます。ユーザーから質問があると、ナレッジグラフのノード名がチェックされ、ユーザーの発話のキーワードと照合されます。ノード名、タグ、同義語がチェックされ、そのスコアに基づいて、質問が一致する可能性の高いもの、あるいはインテントとしてショートリストに記載されます。ショートリストに載ったこれらの質問は、実際のユーザーの発話と比較され、ユーザーに提示するのに最適なインテントが導き出されます。応答には、単純な応答か、またはダイアログタスクの実行のいずれかの形式があります。このようにして、ごく少数の全く異なる代替質問をFAQに追加し、タグ、同義語、ノード名を適切に提供することで、トレーニングしていないどんな質問も一致させることができます。ナレッジグラフのパフォーマンスとインテリジェンスは、適切なノード名、タグ、同義語を使用してナレッジグラフをトレーニングする方法によって決まります。
用語解説
この文書は、ナレッジグラフの構築に使用される用語を読者に理解していただくことを目的としています。KG作成に直接ジャンプ。
用語またはノード
用語やノードは、オントロジーの構成要素であり、ビジネス業種のファンダメンタルな概念とカテゴリを定義するために使用されます。下の画像のように、「ボットオントロジー」ウィンドウの左側ペインにある用語を階層的に整理して、組織内の情報のフローを表すことができます。そこから用語の作成、整理、編集、および削除を行うことができます。最大ノード数20k、最大FAQ数50kというプラットフォームの制限があります。表現を容易にするために、いくつかの特別なノードを以下の名前で識別します。
ルートノード
ルートノードは、ボットオントロジーの最上位の用語を形成します。ナレッジグラフは1つのルートノードのみで構成され、オントロジー内の他のすべてのノードはその子ノードとなります。ルートノードは、デフォルトではボットの名前を取りますが、必要に応じて変更することができます。このノードは、ノード認定や処理には使用されません。パスの認定は、第1レベルのノードから始まります。ルートノードの直下にFAQを置くことは好ましくありませんが、必要に応じて、FAQの数をルートノードで最大100に制限する必要があります。
第1レベルのノード
ルートノードのすぐ次のレベルのノードを第1レベルノードと呼びます。コレクションには、任意の数の第1レベルノードが存在します。部門名や機能名などの高レベルの用語を表すために、第1レベルのノードを残しておくことをお勧めします。例:パーソナルバンキング、オンラインバンキング、およびコーポレートバンキング。
リーフノード
質問・回答セットやダイアログタスクが追加されたノードは、どのレベルであっても リーフノードと呼ばれます。
ノード関係
オントロジー内での位置に応じて、ノードは第1レベルノード、第2レベルノードなどと呼ばれます。第1レベルノードとは、第2レベルノードと呼ばれる1つ以上のサブカテゴリをその下に持つカテゴリです。例として、ローンはホームローンとパーソナルローンの第1レベルノードです。パーソナルローンは、もう一度、2つのサブカテゴリノードを持つことができます。レートと料金、ヘルプとサポート。
メモ:このようにノードが階層化されているのは、関連する質問をまとめて便利にしておくためです。ナレッジグラフエンジンは、質問が一致するかどうかを評価する際に、親子関係を考慮しません。階層構造は、FAQ組織の中での位置に関係なく、すべてのノードが同じように考慮されるので、FAQの一致処理には何も影響しません。
タグ
各用語/ノードに対して、カスタムタグを追加できます。タグは用語と同じように機能しますが、ナレッジグラフのオントロジーには表示されないため、混乱を避けることができます。タグには、用語と同じように、同義語や特徴を追加できます。
同義語
ユーザーは、オントロジーの用語にさまざまな選択肢を使用します。ナレッジグラフでは、用語の同義語を追加することで、可能性のある代替形式の用語をすべて含めることができます。また、同義語を追加することで、代替質問をボットにトレーニングする必要性も軽減します。例として、インターネットバンキングのノードには、以下のような同義語が追加されます。オンラインバンキング、 eバンキング、サイバーバンキング、 Webバンキング。ナレッジグラフで用語の同義語を追加する際、ローカルまたはグローバルな同義語として追加することができます。ローカルな同義語(またはパスレベルの同義語)は、その特定のパスでのみ用語に適用されるのに対し、グローバルな同義語(またはナレッジグラフの同義語)は、オントロジー内の他のパスに出現しても用語に適用されます。リリース7.2以降では、ナレッジグラフエンジン内でボットの同義語を使用してパスの確認や質問の一意を行うことができます。この設定では、ボットの同義語とKGの同義語に同じ同義語のセットを再作成する必要はありません。
特性
メモ:v7.0以降、v6.4以前のクラスの代わりに特性が採用されています。特性とは、エンドユーザーが特定のインテントに関連する情報を求める際に、質問の性質を定義する一般的なエンドユーザー発話のコレクションです。特性については、こちらをご覧ください。特性は、ボットオントロジーの複数の用語に適用されます。
メモ:特性は、関連するユーザーの発話に基づいてノードをフィルタリングするのにも役立ちます。したがって、ユーザーが特性に含まれる発話を入力すると、ボットは特性が適用されているノードのみを検索します。その発話が、特性が適用されていない他のノードに含まれる場合、そのノードはボットによって無視されます。
インテント
ボットは、ユーザーからの質問に対して、ダイアログタスクやFAQを実行して応答することができます。
- FAQ:質問・回答ペアは、ボットオントロジーの関連ノードに追加する必要があります。最大50kのFAQが許容されます。質問はユーザーごとに異なるため、これをサポートするには、各質問に複数の代替形式を関連付ける必要があります。代替質問の前に||をつけると、FAQのパターンを入力することができます(7.2リリース以降)。
- タスク:KGインテントにダイアログタスクをリンクさせることで、ナレッジグラフとダイアログタスクの機能を活用し、複雑な会話を伴うFAQに対応することができます。
パフォーマンスの向上
ナレッジグラフエンジンは、デフォルト設定でも十分に機能します。ボット開発者は、KGエンジンのパフォーマンスをさまざまな方法で微調整することができます。
- 用語、同義語、プライマリ質問と代替質問、ユーザーの発話を定義して、ナレッジグラフを設定します。階層はKGエンジンのパフォーマンスには影響しませんが、KGエンジンの作業を組織化し、正しく導くのに役立ちます。
- 以下のパラメータの設定:
- パスの範囲 – ユーザーの発話に含まれる用語のうち、パスに含まれる最小の割合を定義することで、さらにスコアリングを高めることになります。
- KGの明確なスコア – KGインテント一致の最小スコアを定義することで、確定的な一致と見なし、他のインテントの一致が見つかっても破棄します。
- ナレッジタスクのための最小および決定的なレベル – ナレッジタスクが発生した場合に特定して対応するための最小および確定レベルのしきい値を定義します。
- KG提案数 – KGのインテントが明確に一致しない場合に提示するKG/FAQ提案の最大数を定義します。
- 提案型一致の近接性 – トップスコアとすぐ次の提案された質問の間に許容される最大の差を定義して、それらを同等に重要なものと見なします。
プラットフォームでは、上記のしきい値のデフォルト値が提供されていますが、これらは 自然言語>トレーニング>しきい値と設定からカスタマイズできます。
- コンテキストパスの限定 – これは、ボットのコンテキストが一致したインテントの用語/ノードで入力され、保持されていることを確認するものです。これにより、ユーザー体験をさらに高めることができます。
- 特性 – 前述のように、特性は、ユーザーの発話に用語/ノードが含まれていない場合でも、ノード/用語を限定するために使用されます。特性は、提案されたインテントのリストをフィルタリングするのにも役立ちます。
KGエンジンの作動
ナレッジグラフエンジンは、ユーザーの発話に対する適切な応答を抽出しながら、2段階のアプローチを使用します。これは、検索駆動型のインテント検出処理とルールに基づいたフィルタリングを組み合わせたものです。ユーザーの発話におけるパスの範囲(必要な用語の割合)と用語の使用方法(必須またはオプション)の設定は、FAQインテントの最初のフィルタリングに役立ちます。トークン化とnグラムに基づくコサインスコアリングモデルにより、最終的な検索基準を満たすことができます。ナレッジグラフのトレーニングには、以下のような手順があります。
- すべての用語/ノードおよび同義語が識別され、インデックスが作成されます。
- これらの指標を用いて、KGインテントごとにぴったり合ったパスが確立されます。
ナレッジグラフエンジンがユーザーの発話を受け取ると、次のようになります。
- ユーザーの発話とKGのノード/用語をトークン化し、nグラムを抽出します(ナレッジグラフエンジンは最大4グラムまでサポート)。
- トークンは、それぞれのインデックスを得るために、KGノード/用語とマッピングされます。
- ユーザーの発話とKGノード/用語との間のパス比較により、その発話に対して限定パスが確立されます。このステップでは、上述のパス範囲と用語の使用を考慮します。
- 限定パスの質問のリストから、コサインスコアリングに基づいて最適なものが選ばれます。
Leave a Reply
Kore.ai’s Knowledge Graph helps you turn your static FAQ text into an intelligent, personalized conversational experience. It goes beyond the usual practice of capturing FAQs in the form of flat question-answer pairs. Instead, Knowledge Graph enables you to create an ontological structure of key domain terms and associate them with context-specific questions and their alternatives, synonyms, and Machine learning-enabled traits. This Graph, when trained by the platform, enables an intelligent FAQ experience.
This document explains about the concepts, terminology, and implementation of Knowledge Graph. For a use case driven approach to Knowledge Graph, refer here.
Why Knowledge Graph
A user expresses a query in multiple ways. It is a difficult task for you to visualize and add all the alternative questions manually.
Kore.ai designed Knowledge Graph with nodes, tags, and synonyms which makes the work easier for you to cover all the possible matches. The Knowledge Graph can handle various alternate questions with the training using the nodes, tags, and synonyms.
Whenever a question is asked by the user, the node names in the Knowledge Graph is checked and matched with the keywords from the user utterance. Node names, tags, and synonyms are checked and based on the score, questions are shortlisted as likely matches or intents. These shortlisted questions are then compared with the actual user utterance to come up with the best possible intent to present to the user. The response can take the form of either a simple response or execution of a dialog task.
This way, you can add a very few completely different alternative questions in the FAQ and provide tags, synonyms, and node names appropriately such that any untrained question can also be matched. The performance and intelligence of the Knowledge Graph depend on the way you train it with the appropriate node names, tags, and synonyms.
Terminology
This document is intended to familiarize the reader with the terms used in building Knowledge Graph.
Terms or Nodes
Terms or Nodes are the building blocks of an ontology and are used to define the fundamental concepts and categories of a business domain.
As shown in the image below, you can organize the terms on the left pane of the Bot Ontology window in a hierarchical order to represent the flow of information in your organization. You can create, organize, edit, and delete terms from there. There is a platform restriction of 20k maximum number of nodes and 50k number of FAQs.
For easier representation, we identify some special nodes using the following names:
Root Node
Root node forms the topmost term of your Bot Ontology. A Knowledge Graph consists of only one root node and all other nodes in the ontology become its child nodes. Root node takes the name of the bot by default, but you can change it if you want. This node is not used for node qualification or processing. The path qualification starts from first-level nodes. While it is not advisable to have FAQs directly under the root node, in case it is essential to your needs restrict the number of FAQs to a maximum of 100 at the root node.
First-level Nodes
The immediate next level nodes of the root node are known as first-level nodes. There can be any number of first-level nodes in a collection. It is recommended to keep first-level nodes to represent high-level terms such as the names of departments or functionality. For example, Personal Banking, Online Banking, and Corporate Banking.
Leaf Node
Any node to which question-answer set or dialog task is added is called a Leaf Node, be it at any level.
Node Relation
Depending on their position in the ontology, a node is referred to as first-level nodes, second-level nodes, etc. A first-level node is a category that has one or more sub-categories under it called the second-level nodes.
For example, a Loan is the first-level node of a Home Loan and Personal Loan. A Personal Loan can again have two subcategory nodes: Rate and Fees, Help and Support.
Note: This hierarchical organization of nodes is for your convenience to keep related questions together. Knowledge Graph Engine does not consider any parent-child relation while evaluating the questions for a match. The hierarchy does not in any way influence the FAQ matching processing since all the nodes are considered the same way irrespective of their position in the FAQ organization.
Tags
For each term/node, you can add custom tags. Tags work exactly like terms but are not displayed in the Knowledge Graph ontology to avoid clutter. You can add synonyms and traits to tags as you do to terms.
Synonyms
Users use a variety of alternatives for the terms of their ontology. Knowledge Graph allows you to add synonyms for the terms to include all possible alternative forms of the terms. Adding synonyms also reduces the need for training the bot with alternative questions.
For example, the Internet Banking node may have the following synonyms added to it: Online Banking, e-banking, Cyberbanking, and Web banking.
When you add a synonym for a term in the Knowledge Graph, you can add them as local or global synonyms. Local synonyms (or Path Level Synonyms) apply to the term only in that particular path, whereas global synonyms (or Knowledge Graph Synonyms) apply to the term even if it appears on any other path in the ontology.
Post-release 7.2, you can enable the usage of Bot Synonyms inside the Knowledge Graph engine for path qualification and question matching. With this setting, you need not recreate the same set of synonyms in Bot Synonyms and KG Synonyms.
Traits
Note: From v7.0, Traits replace Classes of v6.4 and before.
A trait is a collection of typical end-user utterances that define the nature of a question when they ask for information related to a particular intent. See here for more on traits.
A trait is applied to multiple terms across your Bot Ontology.
Note: Traits also help you filter nodes based on associated user utterances. So, if the user types an utterance that is present in a trait, the bot only searches the nodes to which the trait is applied. If the utterance is present in any other node to which the trait is not applied, the node is ignored by the bot.
Intent
A bot can respond to a given question from the user either with an execution of a Dialog Task or a FAQ.
- FAQ: The question-answer pairs must be added to relevant nodes in your bot ontology. A maximum of 50k FAQs is permissible.
A question is asked differently by different users and to support this, you must associate multiple alternate forms for each question.
Preceding an alternate question with || will allow you to enter patterns for FAQs (post 7.2 release). - Task: Linking a Dialog task to a KG Intent helps to leverage the capabilities of the Knowledge Graph and Dialog tasks to handle FAQs that involve complex conversations.
Improving Performance
The Knowledge Graph engine works well with the default settings. As a bot developer, you can fine-tune the KG engine performance in many ways:
- Configure Knowledge Graph by defining terms, synonyms, primary and alternative questions, or user utterances. Though hierarchy does not affect the KG engine performance, it does help in organizing and guiding the working of the KG engine.
- Setting the following parameters:
- Path Coverage – Define the minimum percentage of terms in the user’s utterance to be present in a path to qualify it for further scoring.
- Definite Score for KG – Define the minimum score for a KG intent match to consider as a definite match and discard any other intent matches found.
- Minimum and Definitive Level for Knowledge Tasks – Define minimum and definitive threshold to identify and respond in case of a knowledge task.
- KG Suggestions Count – Define the maximum number of KG/FAQ suggestions to present when a definite KG intent match is not available.
- The proximity of Suggested Matches – Define the maximum difference to allow between top-scoring and immediate next suggested questions to consider them as equally important.
While the platform provides default values for the above-mentioned thresholds, these can be customized from the Natural Language > Training > Thresholds & Configurations.
- Qualify Contextual Paths – This ensures that the bot context is populated and retained with the terms/nodes of the matched intent. This further enhances the user experience.
- Traits – As mentioned earlier, traits are used to qualify nodes/terms even if the user utterance does not contain the term/node. Traits are also helpful in filtering the suggested intent list.
Working of KG Engine
Knowledge Graph engine uses a two-step approach while extracting the right response to the user utterance. It combines a search-driven intent detection process with rule-based filtering. The settings for path coverage (percentage of terms needed) and term usage (mandatory or optional) in user utterance helps in the initial filtering of the FAQ intents. Tokenization and n-gram based cosine scoring model aids in the fulfillment of the final search criteria.
Training of the Knowledge Graph involves the following steps:
- All the terms/nodes along with synonyms are identified and indexed.
- Using these indices, a flattened path is established for each KG Intent.
Once the Knowledge Graph Engine receives a user utterance:
- The user utterance and KG nodes/terms are tokenized, and n-gram is extracted (Knowledge Graph Engine supports a max of quad-gram).
- The tokens are mapped with the KG nodes/terms to obtain their respective indices.
- Path comparison between the user utterance and KG nodes/terms establishes the qualified path for that utterance. This step takes into consideration the path coverage and term usage mentioned above.
- From the list of questions in the qualified path, the best match is picked based upon cosine scoring.