Workbench combines the key aspects of the data indexing configuration process for transforming the content from data sources into objects for indexing.
An Index Pipeline transforms the content into a document suitable for indexing. It consists of a series of configurable index pipeline stages. Each stage performs a different transformation on the data before passing the result to the next stage in the pipeline. For example, you can extract the entity values before processing trait properties. SearchAssist provides a built-in pipeline that allows Index Workbench to develop custom index pipelines to suit any application.
Index Pipeline Stages
The data transformation is done in a series of operations called stages. SearchAssist provides many specialized index stages and custom script stages that allow custom processing. Each stage has a stage-specific configuration. You can order the stages in your preferred flow.
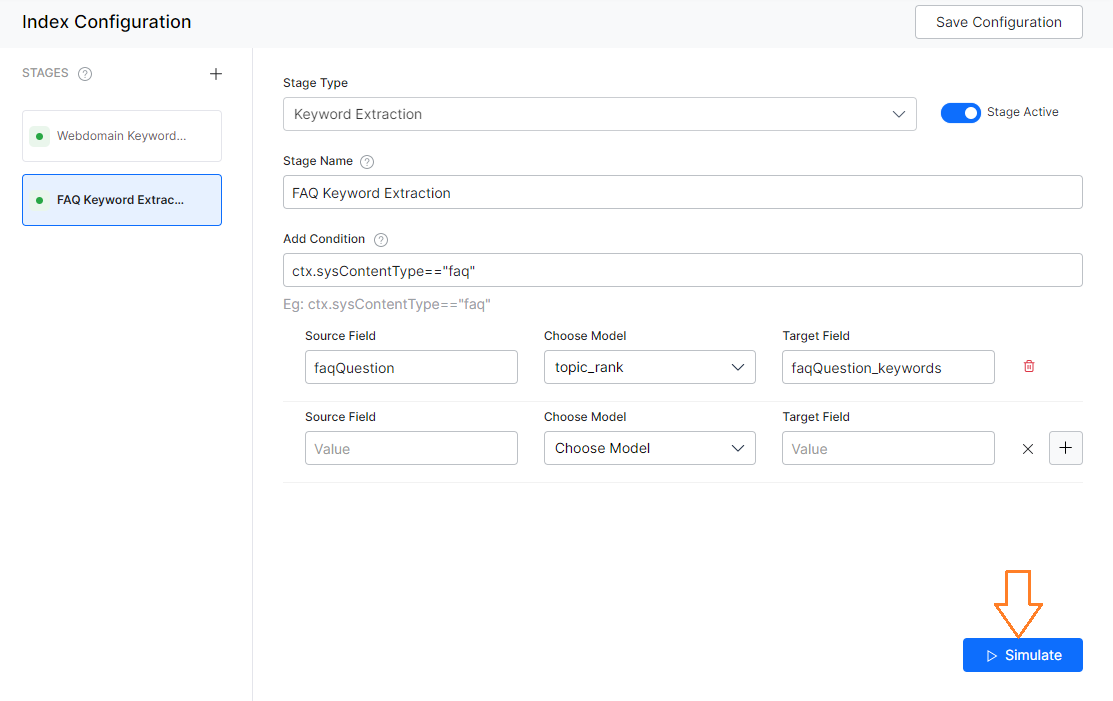
A pipeline stage consists of properties like stage type, stage name, and condition. You can write conditions to choose the documents that must be transformed. For example, you can write a condition to select only FAQs.
Remember to Train your app each time you make changes to any index configuration. This would build the index based on the updated configurations.
In case you want to test the application for select stages and not all, you can choose to render a particular stage inactive. This will retain the stage but at the same time, it won’t be considered for index configuration. You can make the stages active at a later time as per your needs.
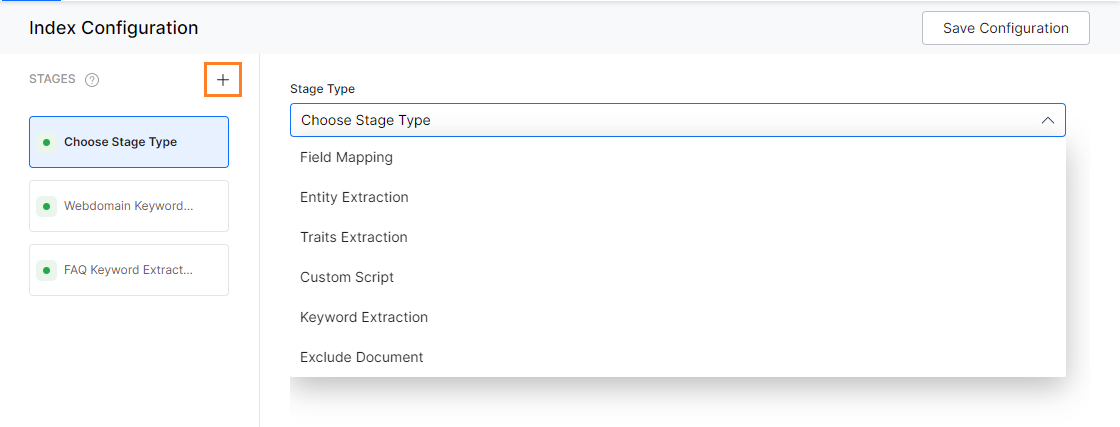
Index pipeline stages are listed below:
- The Field Mapping stage is used to map fields in an index pipeline document to a target field, set values, copy values, remove fields, and much more. Refer here for details.
- Keyword Extraction is a technique to automatically detect important words from the text stored in a field. Refer here for details.
- Traits Extraction extracts specific entities, attributes, or details that the search users might express in their conversations. Refer here for details.
- Entity Extraction uses NLP techniques to identify named entities from the source field. Refer here for details.
- Semantic Meaning analysis is the technique to understand the meaning and interpretation of words, signs, and sentence structure. Refer here for details.
- Custom Script stage allows you to enter customized scripts to perform any field mapping tasks like deleting or renaming fields. Refer here for details.
- Exclude Document stage drops all the documents that match the specified condition. Refer here for details.
Simulate
The Workbench is bundled with a Simulator that provides an interactive preview of how stage rules affect a document before it is indexed.
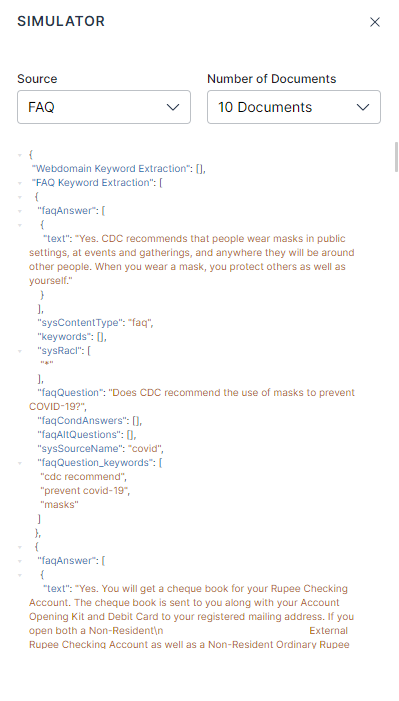
You can simulate the index stage execution of sample documents using the Simulate button. The stages up to the one selected would be implemented. For example, if you have three stages Traits, Webdomain Keyword, and FAQ Keyword Extraction in that order and you hit Simulate in Webdomain keywords stage then the simulation would extract Traits and Webdomain keywords.
The simulated result highlights the impacted fields and allows you to see the fields available in the document.