봇이 관련 작업으로 사용자 발화에 응답하는지 확인하려면, 다양한 사용자 입력으로 봇을 테스트하는 것이 중요합니다. 예상되는 사용자 입력의 많은 샘플로 봇을 평가하면 봇 응답에 대한 통찰력을 제공할 뿐만 아니라 인간의 다양한 표현을 해석하도록 봇을 학습시킬 수 있는 좋은 기회를 제공합니다. 발화 테스트 모듈에서 봇의 모든 학습 관련 활동을 수행할 수 있습니다. 테스트 및 학습 문서에서 예시로 사용하기 위해 다음 작업으로 구성된 항공편 예약 봇을 사용할 것입니다. 
봇 테스트
간단히 말해, 봇 테스트는 봇이 가장 적절한 작업으로 사용자 발화에 응답할 수 있는지 확인하는 것을 의미합니다. 언어의 유연성을 고려할 때, 사용자는 같은 의도를 표현하기 위해 다양한 문구를 사용할 것입니다. 예를 들어, 1월 1일 샌프란시스코에서 로스앤젤레스로 가는 티켓을 변경하고 싶습니다를 다음과 같이 바꿔서 표현할 수 있습니다. 여행 날짜를 변경해 주세요. 1월 1일은 못 갑니다. 요령은 동일한 발화로 이 두 발화를 매핑하도록 봇을 훈련시키거나 예약 수정 작업을 수행하는 것입니다. 따라서, 봇 테스트를 시작하기 위한 첫 번째 단계는 봇 응답을 테스트할 사용자 발화의 대표적인 샘플을 식별하는 것입니다. 지원 채팅 로그, 온라인 커뮤니티, 관련 포털의 FAQ 페이지 등 실제 언어 사용을 반영하는 데이터 소스를 찾습니다.
봇 테스트 방법
봇을 테스트하려면 다음 단계를 따르세요.
- 테스트하려는 봇을 엽니다.
- 상단 메뉴에서 빌드 탭을 선택합니다.
- 왼쪽 메뉴에서 테스트 -> 발화 테스트를 클릭합니다.
- 다중 의도 모델의 경우, 발화를 테스트하려는 의도 모델을 선택할 수 있습니다. ML 엔진은 선택된 모델에서만 의도를 감지합니다.
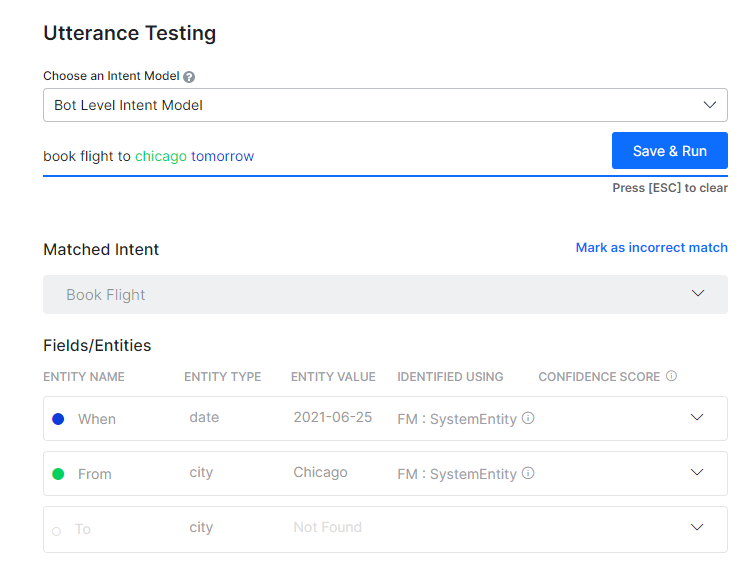
- 사용자 발화 입력 필드에, 테스트하려는 발화를 입력합니다. 예: 항공편 예약:
- 결과에는 단일 의도, 다중 의도 또는 일치하지 않는 의도가 나타납니다.

테스트 결과 유형
봇에 사용자 발화를 테스트할 때, NLP 엔진은 의도와 일치하는 봇 작업을 찾으려고 시도합니다. NLP 엔진은 기계 학습, 기초 의미 및 Knowledge Graph(봇에 있는 경우) 모델을 통한 하이브리드 접근 방식으로 관련성에 대한 일치 의도의 점수를 매깁니다. 모델은 사용자 발화를 가능한 일치 또는 확실한 일치로 분류합니다.

확실한 일치는 높은 신뢰도 점수를 얻은, 사용자 발화와 완벽하게 일치하는 것으로 간주합니다. 게시된 봇에서 사용자 입력이 단일한 확실한 일치와 일치하면, 봇이 작업을 직접 실행합니다. 발화가 여러 개의 확실한 일치와 일치하는 경우, 최종 사용자가 하나를 선택할 수 있는 옵션으로 전송합니다. 반면에, 가능한 일치는 사용자 입력에 대해 꽤 좋은 점수를 받지만 정확한 일치라고 부를 만큼 확실하다는 생각이 들지 않는 의도입니다. 내부적으로 시스템은 점수에 따라 가능한 일치를 좋은 일치와 확실하지 않은 일치로 추가 분류합니다. 게시된 봇에서 최종 사용자의 발화가 가능한 일치를 생성한 경우, 봇은 이러한 일치를 “이런 뜻이 맞습니까?”라는 제안 형태로 최종 사용자에게 보냅니다. 다음은 사용자 발화 테스트의 가능한 결과입니다.
-
- 단일 일치(가능한 또는 확실한): NLP 엔진은 단일 의도 또는 작업과 사용자 발화가 일치하는 것을 찾습니다. 의도는 사용자 발화 필드 아래에 표시됩니다. 발화가 올바른 일치인 경우, 계속해서 다음 발화를 테스트하거나 작업을 학습하여 점수를 향상시킬 수도 있습니다. 발화가 부정확한 일치인 경우, 잘못된 것으로 표시하고 적절한 의도를 선택할 수 있습니다.
- 다중 일치(가능한, 확실한 또는 둘 다): NLP 엔진은 사용자 발화와 일치하는 다중 의도를 식별합니다. 결과에서, 일치하는 작업의 라디오 버튼을 선택하고 학습합니다.

- 알 수 없는 의도: 사용자 입력이 연결된 봇의 어떠한 작업과도 일치하지 않습니다. 의도를 선택하고 사용자 발화와 일치하도록 학습합니다.

엔티티 일치
봇을 테스트하는 동안, 일치하는 엔티티가 표시됩니다. 발화의 엔티티는 다음의 순서로 처리됩니다. 처음으로 NER 및 패턴 엔티티 그다음으로 나머지 엔티티. 플랫폼의 릴리스 8.0 이후, 엔티티가 어떻게 일치하는지에 대한 세부 정보와 신뢰도 점수가 표시됩니다. 세부 정보는 다음을 포함합니다.
- 식별 엔진 – 기계 학습 또는 기초 의미;
- 학습 유형 – NER, 패턴 학습, 엔티티 이름, 시스템 개념 등에서 일치가 있을 수 있습니다. 패턴 일치의 경우, 행을 클릭하여 같은 세부 정보를 얻습니다.
- NER 학습을 사용하여 ML 엔진이 식별한 신뢰도 점수(조건부 랜덤 필드가 NER 모델로 선택된 경우에만 해당함)
테스트 결과 분석
사용자 발화를 테스트하는 경우, 일치하는 의도 외에도 NLP 분석 상자가 표시되며, 최종 후보에 오른 의도 및 후보 선정에 사용된 NLP 모델, 상응하는 점수, 최종 우승자에 대한 간략한 개요를 제공합니다. 기초 의미 탭에서는, 최종 후보에 없더라도 모든 의도의 점수를 볼 수 있습니다. 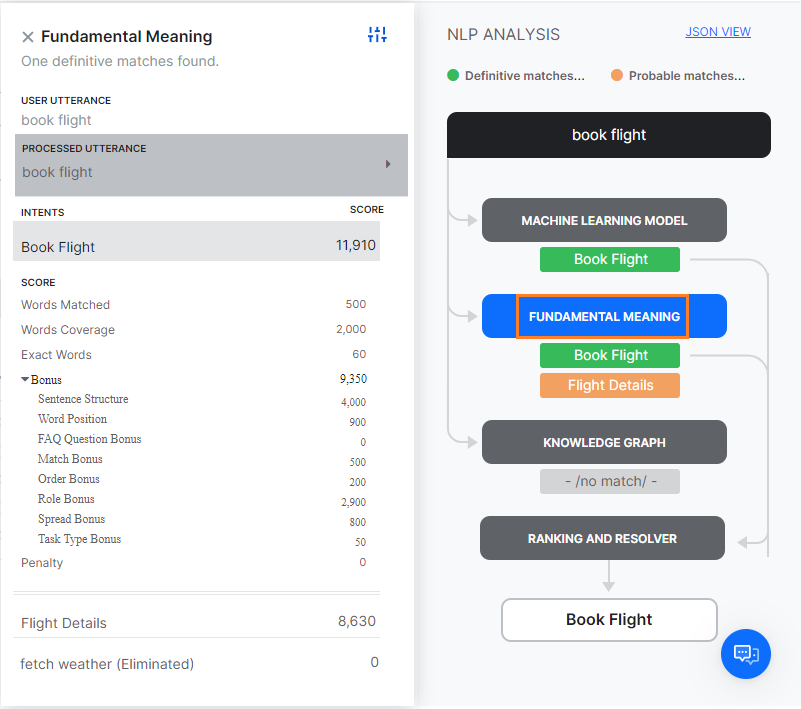 위에서 언급한 대로, Kore.ai NLP 엔진은 기계 학습, 기초 의미 및 Knowledge Graph(있는 경우) 모델을 사용하여 의도를 일치시킵니다. NLP 엔진이 기본 모델 중 하나를 통해 단일의 확실한 일치를 찾은 경우, 해당 작업을 일치하는 의도로 간주합니다. 테스트에서 하나 이상의 확실한 일치가 확인되는 경우, 올바른 의도를 선택할 수 있는 옵션이 주어집니다. 모델이 하나 이상의 가능한 일치를 후보로 선정한 경우, 기초 의미 모델을 사용하여 순위와 해결에 의해 모든 후보 의도의 점수를 다시 채점하여 최종 승자를 결정합니다. 때로는, 여러 가능한 일치가 재채점 후에도 같은 점수를 확보하는데, 이 경우 개발자에게 여러 일치를 제시하여 하나를 선택하도록 합니다. NLP 분석 상자에서 학습 모델의 이름이 있는 탭을 클릭하여 의도 점수를 볼 수 있습니다.
위에서 언급한 대로, Kore.ai NLP 엔진은 기계 학습, 기초 의미 및 Knowledge Graph(있는 경우) 모델을 사용하여 의도를 일치시킵니다. NLP 엔진이 기본 모델 중 하나를 통해 단일의 확실한 일치를 찾은 경우, 해당 작업을 일치하는 의도로 간주합니다. 테스트에서 하나 이상의 확실한 일치가 확인되는 경우, 올바른 의도를 선택할 수 있는 옵션이 주어집니다. 모델이 하나 이상의 가능한 일치를 후보로 선정한 경우, 기초 의미 모델을 사용하여 순위와 해결에 의해 모든 후보 의도의 점수를 다시 채점하여 최종 승자를 결정합니다. 때로는, 여러 가능한 일치가 재채점 후에도 같은 점수를 확보하는데, 이 경우 개발자에게 여러 일치를 제시하여 하나를 선택하도록 합니다. NLP 분석 상자에서 학습 모델의 이름이 있는 탭을 클릭하여 의도 점수를 볼 수 있습니다.
참고: NLP 점수는 절댓값이며 동일한 입력의 다른 작업과 비교할 때에만 사용할 수 있습니다. 작업 점수는 다른 발화에서 비교할 수 없습니다.
각 모델 대화 상자에서, 오른쪽 상단의 아이콘을 클릭하면 해당 엔진에 적용된 설정과 임계값이 표시됩니다. 
ML 모델
ML 모델은 사용자 입력을 작업 레이블 및 각 작업의 학습 발화와 일치시키려 합니다. 사용자 입력이 여러 문장으로 구성된 경우, 각 문장은 작업 이름과 작업 발화에 대해 별도로 실행됩니다. 기계 학습 모델 버튼을 클릭하여 NLP 분석의 기계 학습 모델 섹션을 엽니다. 긍정적인 점수를 확보한 작업의 이름만 표시됩니다. 일반적으로, 작업에 추가된 학습 발화의 수가 많을수록, 발견 가능성이 더 높아집니다. 자세한 내용은, 기계 학습을 읽어보세요. 
FM 모델
ML 모델 외에도, 봇의 각 작업은 작업 이름 및 동의어, 패턴의 다양한 조합을 포함하는 종합적인 맞춤형 NLP 알고리즘을 사용하여 사용자 입력에 대해 점수가 매겨집니다. Fundamental meaning(FM) 모델 탭에는 봇의 모든 의도에 대한 분석이 표시됩니다. 탭을 클릭하면 각 작업의 점수를 볼 수 있습니다. 처리된 발화를 클릭하면 사용자 발화를 분석하고 처리한 방법을 알 수 있습니다. 릴리스 7.2부터, FM 엔진은 봇의 언어에 따라 두 가지 방식으로 모델을 생성합니다. 접근 방법 1: 독일어 및 프랑스어를 지원합니다. 원어, 보편적인 품사, 의존 관계 및 관련 단어와 관계된 단어 분석 요소가 자세히 설명되어 있습니다. 그 다음, 처리된 각 의도의 점수 구분이 표시됩니다. 스코어링된 의도(일치됨 또는 제거됨)를 선택하면 각 단어에 대한 스코어링 세부 정보가 표시됩니다. 여기에는 발화의 단어, 종속성 파싱에 따라 각 단어에 할당된 점수가 포함됩니다. 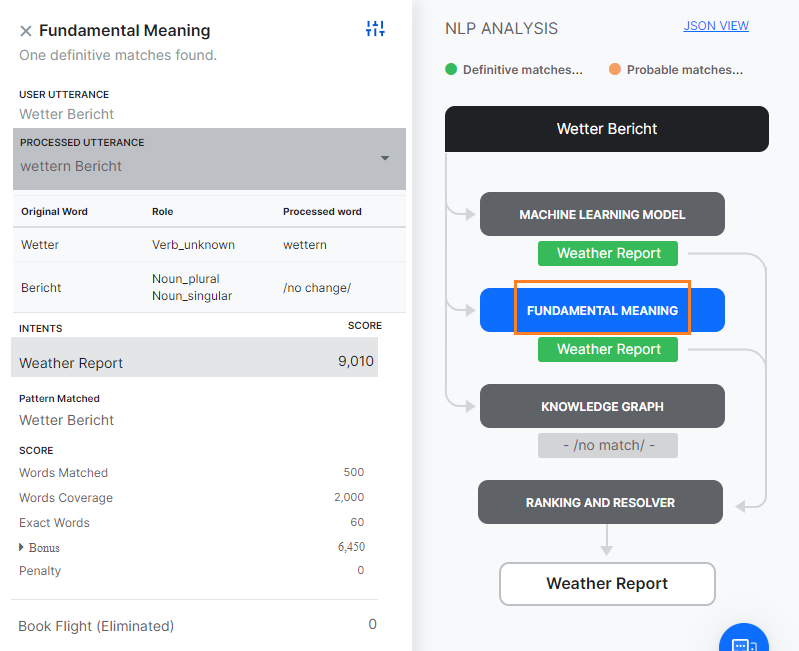
접근 방법 2: 위에서 언급된 언어를 제외한 모든 언어를 지원합니다. 원어, 문장에서의 역할 및 처리된 단어(철자 수정의 경우)와 관계된 단어 분석 요소가 자세히 설명되어 있습니다. 그다음, 처리된 각 의도의 점수 구분이 표시됩니다. 스코어링된 의도(일치됨 또는 제거됨)를 선택하면 각 단어에 대한 스코어링 세부 정보가 표시됩니다. 자세한 분류는 아래와 같습니다.
- 일치된 단어: 작업 이름 또는 작업에 대해 학습된 발화의 단어와 일치하는 사용자 입력에서의 단어 수에 부여된 점수.
- 단어 범위: 작업 이름, 필드 이름, 발화, 동의어를 포함하여 작업의 전체 단어와 일치하는 단어의 비율에 대해 부여된 점수.
- 정확한 단어: 동의어가 아닌 정확히 일치하는 단어 수에 대해 부여된 점수.
- 보너스
- 문장 구조: 사용자 입력과 일치하는 문장 구조에 대한 보너스.
- 단어 위치: 문장 내 단어의 위치에 따라 단어에 부여된 점수. 문장의 시작 부분에 있는 개별 단어에 더 높은 선호도가 부여됩니다. 단어가 문장 시작에 가까우면 추가 점수를 받습니다.
- 순서 보너스: 작업 레이블과 동일한 순서로 된 단어 수에 대한 보너스.
- 역할 보너스: 일치하는 기본 역할 및 보조 역할(주어/동사/목적어)의 수에 대한 보너스.
- 확산 보너스: 패턴에서 첫 번째로 일치하는 단어와 마지막으로 일치하는 단어의 위치 차이에 대한 보너스. 차이가 클수록, 점수가 높아집니다.
- 패널티: 작업 이름 앞에 여러 개의 구문이 있거나 작업 레이블 중간에 접속사가 있는 경우 패널티.
Knowledge Graph
봇이 Knowledge Graph로 구성된 경우, 사용자 발화를 처리하여 용어를 추출하고 Knowledge Graph와 매핑하여 관련 경로를 가져옵니다. 용어 수가 사전 설정된 임계값을 초과하는 모든 경로는 추가 심사를 위해 최종 후보로 등록됩니다. 경로에 100% 용어가 포함되어 있고 유사한 FAQ가 있으면 완벽한 일치로 간주됩니다.
발화가 대화(KG에서 실행에 따른 대화 옵션)를 실행하는 경우, 동일한 것이 일치된 의도 및 일치된 발화로 표시됩니다. 아래 학습 세션에 자세히 설명된 대로 ML 또는 FM 엔진에서 의도에 대해 봇을 추가로 학습시킬 수 있습니다.
여기에서 Knowledge Graph 학습을 자세히 알아보세요.

순위 및 해결
순위 및 해결은 전체 NLP 계산을 통해 최종 승자를 결정합니다. ML 모델 또는 Knowledge Graph 중 하나가 완벽한 일치를 찾을 경우, 순위와 해결은 의도를 다시 스코어링하지 않고 이를 일치된 의도로 표시합니다.
완벽한 일치가 여러 개 있는 경우, 개발자가 선택할 수 있는 옵션으로 제공됩니다. 순위와 해결은 기초 의미 모델을 사용하여 세 가지 모델이 식별한 다른 모든 우수한 일치 및 불확실한 일치의 점수를 재채점합니다. 재채점 후, 의도의 최종 점수가 특정 임계값을 넘는 경우에도 일치로 간주합니다.
순위와 해결 탭을 선택하면 세부 정보가 표시됩니다. 각 일치의 순위와 세부 정보는 일치된 발화를 선택하여 볼 수 있습니다.

봇 언어에 따른 스코어링 모델은 다음과 같습니다.
- 단어 역할, 문장/단어 위치 및 단어 순서 기반, 또는
- 종속성 파싱(독일어 및 프랑스어 지원) 기반
세 엔진이 서로 다른 확실한/가능한 일치를 반환할 때, 순위 및 해결에 의한 의도 제거의 기준은 다음과 같습니다.
- 날짜, 숫자 등 엔티티 값에 따라 일치된 의도는 기계 학습 모델에 의해 제거됩니다.
- 세 가지 엔진 중 하나로 식별된 모든 가능한 일치는 확실한 일치가 발견되는 경우 제거됩니다.
- 사용자 발화에서 이전에 또 다른 확실한 일치가 발견되는 경우 확실한 일치는 제거됩니다. 사용자 발화에 두 개의 의도가 포함된 경우입니다. 예를 들어, “항공편 예약 후 택시 예약”은 “항공편 예약” 및 “택시 예약”과 일치하지만 “택시 예약”은 “항공편 예약” 이후 제거됩니다.
- 확실한 의도 일치 다음에 나오는 의도 패턴 일치는 제거됩니다. 예를 들어, “이메일 전송 작업 생성”의 사용자 발화는 “작업 생성” 및 “이메일 전송”의 의도와 일치하지만, 이 경우 “이메일 전송”은 “작업 생성” 의도 다음에 나왔으므로 제거됩니다.
- 임계값 및 설정 섹션에서 설정된 최솟값 점수 미만의 점수를 받은 의도는 제거됩니다.
- 네거티브 패턴과 일치하는 확실한 일치.
- 정의된 경우, 사전 조건이 충족되지 않는 의도는 제거됩니다.
- 확실한 일치가 Knowledge Graph 엔진에서 답변에서 검색에서 나왔으며 다른 일치된 의도가 있습니다.
봇 학습시키기
학습은 NLP 엔진의 성능을 향상하여 사용자 입력에 따라 다른 것보다 봇 작업 또는 사용자 의도를 우선시하는 방법입니다. 봇을 테스트하고, 필요한 경우, 가능한 모든 사용자 발화에 대해 봇을 학습시켜야 합니다.
봇 학습
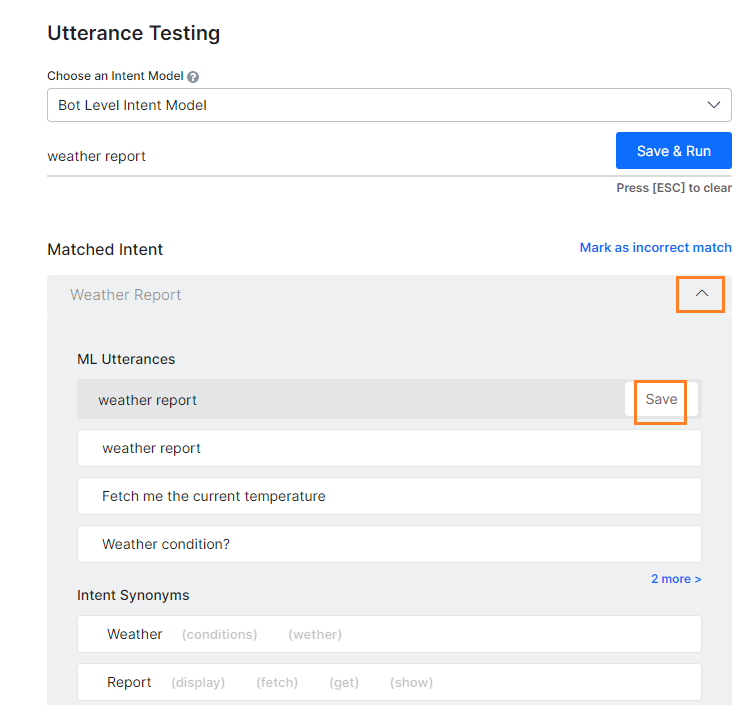
- 사용자 발화를 입력한 후, 테스트 결과에 따라 다음 중 하나를 수행하여 학습 옵션을 엽니다.
- 일치하지 않은 의도의 경우: 의도 선택 드롭다운 목록에서, 사용자 발화와 일치시킬 의도를 선택합니다.
- 일치하는 의도가 여러 개인 경우: 일치시킬 의도의 라디오 버튼을 선택합니다.
- 일치하는 의도가 하나인 경우: 일치하는 의도의 이름을 클릭합니다.
- 입력한 사용자 발화는 ML 발화 섹션 아래의 필드에 표시됩니다. 의도에 발화를 추가하려면, 저장을 클릭합니다. 원하는 만큼 차례대로 발화를 추가할 수 있습니다. 자세한 내용은, 기계 학습을 읽어보세요.
- 의도 동의어 섹션에서, 작업 이름의 각 단어는 별도의 라인 항목으로 나타납니다. NLP 인터프리터의 정확도를 최적화하여 올바른 작업을 인식하기 위한 단어의 동의어를 입력합니다. 자세한 내용은, 동의어 관리하기를 읽어보세요.
- 의도 패턴 섹션에서, 의도의 작업 패턴을 입력합니다. 자세한 내용은, 패턴 관리하기를 읽어보세요.
- 관련 학습 항목 입력을 모두 완료한 경우, 발화 재실행을 클릭하여 의도 점수가 개선되어 높은 신뢰도 점수를 얻었는지 확인합니다.
FAQ로 학습
봇이 FAQ로 사용자 발화에 응답하도록 하려면, 다음 두 가지 방법을 수행합니다.
- FAQ 페이지에서 용어, 용어 설정 또는 클래스를 설정하고, KG를 학습시킨 후 발화를 다시 테스트합니다.
- 대체 질문의 형태로 발화를 Knowledge Graph 페이지에서 선택한 FAQ에 추가하고, KG를 학습시킨 후 발화를 다시 테스트합니다.
Knowledge Graph 학습을 자세히 알아보세요.
잘못된 일치 표시
사용자 입력이 잘못된 작업과 일치하는 경우, 다음 작업을 수행하여 올바른 의도와 일치시킵니다.
- 일치된 의도 이름 위에서, 잘못된 일치로 표시 링크를 클릭합니다.
- 일치된 의도 드롭다운 목록이 열리고 다른 의도를 선택합니다.
- 사용자 입력에 해당하는 의도를 선택하고 봇을 훈련시킵니다.
ユーザーの発話に関連したタスクでボットが応答することを確認するには、さまざまなユーザー入力でボットをテストすることが重要です。想定されるユーザー入力の大量のサンプルでボットを評価することは、ボットレスポンスへのインサイトが得られるだけでなく、人間のさまざまな表現を解釈できるようにボットをトレーニングする絶好の機会となります。発話テストモジュールから、ボットのトレーニング関連のすべてのアクティビティを実行することができます。テストとトレーニングの記事全体の例として、以下のタスクから成るフライト予約 ボットのサンプルを、使用してみましょう。
ボットのテスト
ボットのテストとは、簡単に言うと、ボットがユーザーの発話に対して最も適切なタスクで応答できるかどうかをチェックすることです。言語の柔軟性から見ると、ユーザーは同じインテントを表現するためにさまざまなフレーズを使用します。例として、“サンフランシスコ発ロサンゼルス着の1月1日便のチケットを変更したい”というフレーズを“旅行日を変更してくださいと言い換えることができます。1月1日の便はできません。”そのトリックは、この両方の発話を同じインテントでマッピングするためにボットをトレーニングするか、あるいは予約の変更タスクを実行することです。そこで、ボットのテストを開始するための最初のステップは、ボットレスポンスをテストするためのユーザーの発話の代表的なサンプルを特定することです。サポートチャットのログ、オンラインコミュニティ、関連ポータルサイトのFAQページなど、実際の言語の使用状況を反映しているデータソースを探します。
ボットのテスト方法
以下の手順でボットをテストします。
- テストしたいボットを開きます。
- トップメニューから構築タブを選択します。
- 左メニューから、テスト->発話のテストをクリックします。
- 複数インテントモデルがある場合は、発話をテストしたいインテントモデルを選択できます。機械学習エンジンは、選択されたモデルからのみインテントを検出します。
- ユーザーの発話を入力フィールドの中に、テストしたい発話を入力します。例:フライトを予約する
- 結果は、単数、複数、または不一致のインテントで表示されます。
テスト結果のタイプ
ボットに対するユーザーの発話をテストする際は、NLPエンジンがインテントに一致するボットタスクを発見しようとします。NLPエンジンは、機械学習、ファンダメンタルミーニング、ナレッジグラフ(ボットにある場合)の3つのモデルを用いたハイブリッドなアプローチで、一致するインテントの関連性をスコアリングします。このモデルでは、ユーザーの発話を一致の可能性と完全一致のいずれかに分類します。
完全一致は高い信頼度のスコアを取得し、ユーザーの発話と完全に一致すると考えられます。公開済みボットでは、ユーザー入力が単一の完全一致であった場合、ボットが直接タスクを実行します。発話に複数の完全一致がある場合は、オプションとして、エンドユーザーが1つを選択して送信します。他方、一致の可能性 は、ユーザー入力に対してかなり良いスコアを出すインテントですが、完全一致と呼ばれるほどの信頼度は得られません。システムの中ではさらに、一致の可能性を、そのスコアに基づいて「良い一致」と「不確かな一致」に分類します。エンドユーザーの発話が、公開済みボットの中で一致の可能性を生成していた場合、ボットはこれらの一致をエンドユーザーに 「そう言う意味でしたか?」 という参考意見を送信します。以下は、ユーザーの発話テストで可能性のある結果です。
-
- 単一の一致(一致の可能性、または完全一致):NLPエンジンは、ユーザーの発話が単一のインテントやタスクに一致するものを見つけます。インテントは、「ユーザー発話」フィールドの下に表示されます。正しく一致していれば、次の発話のテストに移ることができ、あるいはスコアを向上させるためにタスクをさらにトレーニングすることもできます。不適切な一致の場合は、不正確とマークして、適切なインテントを選択することができます。
- 複数の一致(一致の可能性、または完全一致、または両方):NLPエンジンは、ユーザー発話に一致する複数のインテントを識別します。その結果から、一致タスクのラジオボタンを選択し、トレーニングを行います。
- 未特定のインテント:ユーザー入力は、リンクされたボットのいずれのタスクとも一致しませんでした。インテントを選択し、ユーザー発話に一致するようにトレーニングします。
エンティティの一致
ボットのテスト中に、一致したエンティティが表示されます。発話のエンティティは、最初にNERとパターンエンティティ、次に残りのエンティティという順で処理されます。rel8.0以降のプラットフォームでは、エンティティがどのような一致であったのか、また、どのような自信のあるスコアであったのかを含めて、詳細が表示されます。詳細には以下が含まれます。
- 識別エンジン – 機械学習またはファンダメンタルミーニング。
- トレーニングタイプ – NER、パターントレーニング、エンティティ名、システムコンセプトなどから一致できます。パターンが一致した場合、その行をクリックすると同じ行の詳細が表示されます。
- NERトレーニングを使用する機械学習エンジンで識別される信頼度スコア(「条件付きランダム」フィールドがNERモデルとして選択されている場合のみ)
テスト結果の分析
ユーザーの発話をテストすると、一致したインテントに加えて、NLP分析ボックスが表示され、ショートリストされたインテント、ショートリストされたNLPモデル、対応するスコア、そして最終的な勝者の概要が表示されます。“ファンダメンタルミーニング”タブでは、ショートリストされていなくても、すべてのインテントのスコアを見ることができます。 前述したように、Kore.aiのNLPエンジンは、機械学習、ファンダメンタルミーニング、およびナレッジグラフ(存在する場合)のモデルを使用して、インテントを照合します。NLPエンジンが、基礎となるモデルの1つを通して単一の完全一致を発見した場合、そのタスクが一致のインテントとして表示されます。テストの結果、複数の完全一致があった場合は、正しいインテントを選択するためのオプションとして、それらを受け取ることができます。これらのモデルによって複数の一致の可能性と判断された場合、最終的な勝者を決定するために、 ファンダメンタルミーニングモデルを使用して、 ランキングおよび解決 によってすべてのショートリストされたインテントが再スコアリングされます。場合によっては、複数の一致の可能性が再スコアリング後も同じスコアを確保していることがあり、その場合は複数の一致として表示され、開発者は1つを選択することになります。NLP分析ボックス内の学習モデル名のタブをクリックすると、インテントスコアが表示されます。
メモ:NLPスコアは絶対値であり、同じ入力の他のタスクとの比較にのみ使用できます。タスクのスコアは、異なる発話間で比較することはできません。
各モデルのダイアログでは、右上のアイコンをクリックすると、対応するエンジンに定めれられている設定としきい値が表示されます。
機械学習モデル
機械学習モデルは、ユーザー入力とタスクラベルおよび各タスクのトレーニング発話の一致を試みます。ユーザー入力が複数の文から成り立っている場合は、それぞれの文はタスク名およびタスク発話に対して別々に実行されます。機械学習モデルのボタンをクリックすると、NLP分析の[機械学習モデル]セクションが表示されます。ここには、プラスのスコアを確保したタスクの名前だけが表示されています。一般的に、タスクに追加するトレーニング発話の数が多くなればなるほど、発見の可能性がますます高まります。詳細情報ついては、機械学習をお読みください。
FMモデル
ボットの各タスクは、機械学習モデルとは別に、タスク名、同義語、パターンのさまざまな組み合わせを含む総合カスタムNLPアルゴリズムを用いて、ユーザー入力に対してスコアリングします。ファンダメンタルミーニングモデルのタブでは、ボットにおけるすべてのインテントに対して分析結果が表示されます。タブをクリックすると、各タスクのスコアが表示されます。処理済み発話をクリックすると、ユーザー発話がどのように分析および処理されたかが表示されます。rel 7.2以降では、FMエンジンは、ボットの言語に対応して、2種類の方法でモデル生成を行っています。アプローチ1:ドイツ語およびフランス語に対してサポート済み。原語、普遍的な品詞、従属関係詞、関連語にかかわる単語分析 要素を詳しく説明しています。次に、各処理済みインテントのスコアの内訳が表示されます。スコアリング済みのインテント(一致または除外)を選択すると、各単語に対するスコアリング詳細が表示されます。これには、発話からの単語と、係り受け解析に基づいてそれぞれに割り当てられたスコアが含まれます。
アプローチ2:上記以外の言語に対してもサポート済み。オリジナルの単語、文中の役割、処理済み単語(スペル修正の場合)に関連する単語分析要素が詳しく説明されています。次に、各処理済みインテントのスコアの内訳が表示されます。スコアリング済みのインテント(一致または除外)を選択すると、各単語に対するスコアリング詳細が表示されます。詳細な内訳は以下のとおりです。
- 一致した単語:ユーザー入力の中で、タスク名の単語やタスク用のトレーニング発話において一致した単語の数に対して与えられるスコア。
- 単語の範囲:タスク名、分野名、発話、同義語などを含むタスクにおける単語全体の比率と、一致する単語の比率に与えられるスコア。
- 正確な単語:同義語ではなく、正確に一致した単語の数に対して与えられるスコア。
- ボーナス
- 文の構造:ユーザー入力に文の構造が一致した場合のボーナス。
- 単語の位置:文の中で単語の位置をベースに与えられるスコア。 文の最初に位置する単語にはより高い優先度。文頭に近い位置に単語がある場合は、追加のクレジット。
- オーダーボーナス:タスクのラベルと同じ順番の単語の数でボーナス。
- 役割ボーナス:プライマリ役割とセカンダリ役割(主語/動詞/目的語)が一致した数にボーナス。
- スプレッドボーナス:パターンの中で最初に一致した単語と最後に一致した単語の位置の差にボーナス。その差が大きければ大きいほど、スコアも大きくなります。
- ペナルティ:タスク名の前に複数のフレーズがある場合、またはタスクラベルの中央に接続詞がある場合はペナルティ。
ナレッジグラフ
ボットがナレッジグラフから成り立つ場合は、ユーザー発話を処理して用語を抽出し、ナレッジグラフにマッピングして関連パスを取得します。事前設定されたしきい値より大きい用語数を含むパスはすべて、さらなるスクリーニングのためにショートリストに登録されます。100%の用語がカバーされているパスで、パスの中に類似するFAQがある場合は、完全に一致していると考えられます。発話がダイアログをトリガーする場合(ナレッジグラフにおけるダイアログの実行オプションによる)、同一のものが “一致したインテント”および“一致した発話”として表示されます。さらに、機械学習エンジンやFMエンジンのインテントと同じように、ボットのトレーニングを行うことができます( 以下のトレーニングセクションをご参照ください)。ナレッジグラフトレーニングの詳細は、こちらからご覧ください。
ランキングおよび解決
ランキングおよび解決によって、NLP計算全体の最終勝者が決定されます。機械学習モデルとナレッジグラフのどちらかが完全に一致した場合、ランキングと解決はインテントの再スコアリングを行わず、一致したインテントとして提示します。複数の完全一致があったとしても、開発者には選択できるオプションとして提示されます。ランキングおよび解決は、3つのモデルで特定された他のすべての正確・不正確な一致を、ファンダメンタルミーニングモデルを用いて再スコアリングします。再スコアリングの結果、あるインテントの最終スコアがあるしきい値を超えれば、そのインテントも一致していると見なされます。ランキングおよび解決のタブを選択すると、詳細が示されます。 一致した発話を選択することにより、各一致のランキングと詳細を見ることができます。
ボット言語により、スコアリングモデルは以下のようになります。
- 単語の役割、文と単語の位置関係、および単語の順序の組み合わせに基づく、または
- 係り受け解析に基づく(ドイツ語、フランス語向けにサポート)
3つのエンジンが異なる完全一致/一致の可能性を返す場合のランキング・解決によるインテントの排除の根拠は、以下のとおりです。
- 機械学習モデルによって、日付や数字などのエンティティ値をベースに照合されたインテントは排除されます。
- 3つのエンジンのいずれかによって特定されたすべての一致の可能性は、完全一致が発見された場合は、排除されます。
- ユーザーの発話の中で、これより前に別の完全一致が発見されていた場合、完全一致は排除されます – ユーザーの発話に2つのインテントが含まれるケース。例として、「フライトを予約して、次にタクシーを予約する」では、「フライトを予約」と「タクシーを予約」に一致しますが、「フライトを予約」よりも「タクシーを予約」の方が排除されます。
- 完全なインテントの一致に続くインテントのパターンの一致は、排除されます。例として、「メールを送信するタスクを作成する」というユーザーの発話は、「タスクを作成する」と「メールを送信する」というインテントと一致する可能性があります。このような場合、「メールを送信する」は「タスクを作成する」というインテントに従うため、削除されます。
- 「しきい値と設定」セクションにおいて設定された最小値を下回るスコアのインテントは、排除されます。
- ネガティブパターンに一致する完全一致。
- 前提条件(定義されている場合)が満たされていないインテントは、排除されます。
- 完全一致が回答における検索によってナレッジグラフエンジンから得られた場合は、別の一致したインテントが存在します。
ボットのトレーニング
トレーニングとは、ユーザー入力に基づいて、あるボットのタスクやユーザーインテントを他のものよりも優先させるために、NLPエンジンのパフォーマンスを高めることです。可能性のあるすべてのユーザーの発話および入力に対してボットをテストし、必要に応じてトレーニングを行う必要があります。
ボットのトレーニング
- ユーザーの発話を入力後、テストの結果に従って、トレーニングオプションを開くために、以下のうち1つを実行します。
- 不一致のインテントには:インテントの選択ドロップダウンリストから、ユーザーの発話に一致させたいと思うインテントを選択します。
- 複数の一致したインテントには:照合したいインテントのラジオボタンを選択します。
- 単一の一致したインテントには:一致したインテントの名前をクリックします。
- 入力したユーザー発話は、機械学習発話セクションの下のフィールドに表示されます。インテントに発話を追加するには、保存をクリックします。次々と好きなだけ発話を追加することができます。詳細情報は、機械学習をお読みください。
- インテント同義語セクションでは、タスク名における各単語は個別の行アイテムとして表示されます。正しいタスクを認識するためのNLPインタプリターの精度を最適化するには、単語の同義語を入力します。詳細情報については、同義語の管理をお読みください。
- インテントパターンセクションで、インテントのタスクパターンを入力します。詳細情報については、パターンの管理をお読みください。
- 関連するトレーニングエントリの作成が完了したら、 発話の再実行をクリックして、信頼度の高いスコアを得るためにインテントを改善できたかどうかを確かめます。
FAQでトレーニング
FAQによるユーザーの発話に対してボットが応答するようにしたい場合、2つの方法があります。
- FAQページから用語や用語構成やクラスを設定し、さらにナレッジグラフのトレーニングおよび発話の再テストを実行します。
- ナレッジグラフのページから選択したFAQに対して、代わりの質問として発話を追加し、さらにナレッジグラフのトレーニングしおよび発話の再テストを実行します。
ナレッジグラフトレーニングの詳細については、こちらからご覧ください。
不正確な一致をマーク
ユーザー入力が不正確なタスクに一致した場合、次のようにして正しいインテントに一致させます。
- 一致したインテント名の上にある不正確な一致としてマークリンクをクリックします。
- 一致したインテントのドロップダウンリストが表示され、別のインテントを選択することができます。
- ユーザー入力に対応するインテントを選択して、ボットをトレーニングします。
To make sure your bot responds to user utterances with related tasks, it is important that you test the bot with a variety of user inputs. Evaluating a bot with a large sample of expected user inputs not only provides insights into bot responses but also gives you a great opportunity to train the bot in interpreting diverse human expressions.
You can perform all the training-related activities for a bot from the Utterance Testing module. We will use a sample Flight Booking bot consisting of the following tasks for use as examples across the Test and Train article.
Testing the Bot
Simply put, testing a bot refers to checking if the bot can respond to a user utterance with the most relevant task. Given the flexibility of language, users will use a wide range of phrases to express the same intent.
For example, you can rephrase I want to change my ticket from San Francisco to Los Angeles on Jan 1 as Please change my travel date. Can’t make it on Jan 1. The trick is to train the bot to map both of these utterances with the same intent or Modify Booking task.
So, the first step to start testing a bot is to identify a representative sample of user utterances to test the bot responses. Look for sources of data that reflect real-world usage of the language, such as support chat logs, online communities, FAQ pages of relevant portals.
How to test the bot
Follow these steps to test a bot:
- Open the bot that you want to test.
- Select the Build tab from the top menu.
- From the left menu click Testing -> Utterance Testing.
- In the case of a multiple intent model, you can select the Intent Model against with you want to test the utterance. The ML Engine will detect the intents only from the selected model.
- In the Type a user utterance field, enter the utterance that you want to test. Example: Book a flight.
- The result appears with a single, multiple, or no matching intents.
Types of Test Results
When you test a user utterance against a bot, the NLP engine tries to find the bot tasks that match the intent. The NLP engine uses a hybrid approach using Machine Learning, Fundamental Meaning, and Knowledge Graph (if the bot has one) models to score the matching intents on relevance. The model classifies user utterances as either being Possible Matches or Definitive Matches.
Definitive Matches get high confidence scores and are assumed to be perfect matches for the user utterance. In published bots, if user input matches with a single Definitive Match, the bot directly executes the task. If the utterances match with multiple Definitive Matches, they are sent as options for the end-user to choose one.
On the other hand, Possible Matches are intents that score reasonably well against the user input but do not inspire enough confidence to be termed as exact matches. Internally the system further classifies possible matches into good and unsure matches based on their scores. If the end-user utterances were generating possible matches in a published bot, the bot sends these matches as “Did you mean?” suggestions for the end-user.
Below are the possible outcomes of a user utterance test:
-
- Single Match (Possible or Definitive): The NLP engine finds a match for the user utterance with a single intent or task. The intent is displayed below the User Utterance field. If it is a correct match, you can move on to test the next utterance or you can also further train the task to improve its score. If it is an incorrect match, you can mark it as incorrect and select the appropriate intent.
- Multiple Matches (Possible or Definitive or Both): NLP engine identifies multiple intents that match with the user utterance. From the results, select the radio button for the matching task and train it.
- Unidentified Intent: The user input did not match any task in any of the linked bots. Select an intent and train it to match the user utterance.
Entity Match
During testing of the bot, the matched entities are displayed. The entities from the utterance are processed in the following order – first NER and pattern entities and then the remaining entities.
Post rel8.0 of the platform, the details of how the entity was matched, and with what confident scores are also displayed. The details include:
- Identification Engine – Machine Learning or Fundamental Meaning;
- Training Type – match can be from NER, pattern training, entity name, system concept, etc.. In case of pattern match, click the row to get the details for the same;
- Confidence Score identified by the ML engine using NER training (only when Conditional Random Field is selected as the NER model)
Analyzing the Test Results
When you test a user utterance, in addition to the matching intents you will also see an NLP Analysis box that provides a quick overview of the shortlisted intents, the NLP models using which they were shortlisted, corresponding scores, and the final winner.
Under the Fundamental Meaning tab, you can see the scores of all the intents even if they aren’t shortlisted.
As mentioned above, the Kore.ai NLP engine uses Machine Learning, Fundamental Meaning, and Knowledge Graph (if any) models to match intents. If the NLP engine finds a single Definitive Match through one of the underlying models, you will see the task as the matching intent. If the test identifies more than one definitive match, you will receive them as options to pick the right intent.
If the models shortlist more than one possible match, all the shortlisted intents are re-scored by the Ranking and Resolver using the Fundamental Meaning model to determine the final winner.
Sometimes, multiple Possible Matches secure the same score even after the rescoring in which case they are presented as multiple matches to the developer to select one. You can click the tab with the name of the learning model in the NLP Analysis box to view the intent scores.
Note: The NLP score is an absolute value and can only be used to compare against other tasks with the same input. Task scores cannot be compared across different utterances.
From each model dialog, clicking the icon on the top right will display the configurations and thresholds in place for the corresponding engines.
ML Model
The ML model tries to match the user input with the task label and the training utterances of each task. If the user input consists of multiple sentences, each sentence is run separately against the task name as well as the task utterances.
Click on the Machine Learning Model button to open the Machine Learning Model section of NLP Analysis. This shows only the names of the tasks that secure a positive score. In general, the more the number of training utterances that you add to a task, the greater are its chances for discovery. For more information, read Machine Learning.
FM Model
Apart from the ML model, each task in the bot is also scored against the user input using a comprehensive custom NLP algorithm that involves different combinations of task names, synonyms, and patterns.
The Fundamental Meaning (FM) Model tab shows the analysis for all the intents in the bot. Click the tab to view the scores of each task.
Clicking the Processed Utterance shows how the user utterance was analyzed and processed.
From rel 7.2, the FM engine generates the model in two ways, depending upon the language of the Bot.
Approach 1: Supported for German and French languages.
The word analysis factors pertaining to Original Word, Universal Parts of Speech, Dependency Relation and Related Word are elaborated.
Next, the score breakup for each of the intents processed is displayed. Selecting a scored intent (matched or eliminated) displays the details of the scoring for each word. This includes the words from the utterance and score assigned to each based upon the dependency parsing.
Approach 2: Supported for languages, other than the ones mentioned above.
The word analysis factors pertaining to Original Word, Role in the sentence and Processed word (in case of spell correction) are elaborated.
Next, the score breakup for each of the intents processed is displayed. Selecting a scored intent (matched or eliminated) displays the details of the scoring for each word. The detailed breakdown is given below.
- Words Matched: The score given for the number of words in the user input that matched words in the task name or a trained utterance for the task.
- Word Coverage: The score given for the ratio of the words matched with that of the overall words in the task, including task name, field names, utterances, and synonyms.
- Exact Words: The score given for the number of words that matched exactly and not by synonyms.
- Bonus
- Sentence Structure: Bonus for the sentence structure match to the user input.
- Word Position: Score given to a word based on its position in a sentence Individual words towards the start of the sentence are given higher preference. Extra credit if the word is near to the sentence start.
- Order Bonus: Bonus for the number of words in the same order as the task label.
- Role Bonus: Bonus for the number of primary and secondary roles (subject/verb/object) matched.
- Spread Bonus: Bonus for the difference between the position of first and last matched words in a pattern. The higher the difference, the greater the score.
- Penalty: Penalty if there are several phrases before the task name or if there is a conjunction in the middle of the task label.
Knowledge Graph
If the bot consists of a Knowledge Graph, the user utterances are processed to extract the terms and are mapped with the Knowledge Graph to fetch the relevant paths. All the paths containing more than a preset threshold of the number of terms get shortlisted for further screening. Path with 100% terms covered and having a similar FAQ in the path is considered a perfect match.
In case the utterance triggers a dialog (as per run a dialog option in KG), the same is displayed as matched intent and matched utterance. You can further train the bot as you would for an intent from ML or FM engine as detailed in the train section below.
Know more about Knowledge Graph Training from here.
Ranking and Resolver
Ranking and Resolver determines the final winner of the entire NLP computation. If either the ML model or the Knowledge Graph find a perfect match, the ranking and resolver doesn’t re-score the intent and presents it as a matched intent. Even if there are multiple perfect matches, they will be presented as options to the developers from which they can choose.
The Ranking and Resolver re-scores all the other good and unsure matches identified by the three models using the Fundamental Meaning model. After re-scoring, if the final score of an intent crosses a certain threshold, it too is considered as a match.
Selecting the Ranking and Resolver tab gives the details.
The ranking and details for each match can be viewed by selecting the matched utterance.
Depending upon the Bot language the scoring model can be:
- based on a mixture of word roles, sentence/word positions, and word order; or
- based on dependency parsing (supported for German and French languages)
The basis for intent elimination by Ranking & Resolver when the three engines return different definite/possible matches is as follows:
- Intents matched based upon entity values like date, number etc., by the Machine Learning Model are eliminated.
- All possible matches identified by any of the three engines are eliminated if a definitive match was found.
- Definitive match eliminated if another definitive match was found prior to this in the user utterance – case when the user utterance includes two intents. For example, “Book me a flight and then book a cab” would match “Book Flight” and “Book Cab” but “Book Cab” is eliminated over “Book Flight”.
- Intent pattern matches following a definitive intent match are eliminated. For example, user utterance “create a task to send an email” can match the intents “create task” and “send email”, in such cases the “send email” will be eliminated since it follows the intent “create task”
- Intents with scores below the minimum value set in the Threshold and Configurations section are eliminated.
- Definitive matches which match a Negative Pattern.
- Intents for which the pre-conditions, in case defined, are not met are eliminated.
- If the definitive match was from Knowledge Graph Engine by Search In Answer and there is another matched intent.
Training the Bot
Training is how you enhance the performance of the NLP engine to prioritize one bot task or user intent over another based on the user input. You should test and, if needed, train your bot for all possible user utterances and inputs.
Train the bot
- After you enter a User Utterance, depending on the test result do one of the following to open the training options:
- For an unmatched intent: From the Select an Intent drop-down list, select the intent that you want to match with the user utterance.
- For multiple matched intents: Select the radio button for the intent you want to match.
- For a single matched intent: Click the name of the matched intent.
- The user utterance that you entered gets displayed in the field under the ML Utterances section. To add the utterance to the intent, click Save. You can add as many utterances as you want, one after another. For more information, read Machine Learning.
- Under the Intent Synonyms section, each word in the task name appears as a separate line item. Enter the synonyms for the words to optimize the NLP interpreter accuracy to recognize the correct task. For more information, read Managing Synonyms.
- Under the Intent Patterns section, enter task patterns for the intent. For more information, read Managing Patterns.
- When you are done making the relevant training entries, click Re-Run Utterance to see if you have improved the intent to get a high confidence score.
Train with FAQ
In case you want the Bot to respond to user utterance with FAQs there are two ways to do it:
- set the terms, term configuration, or classes from the FAQ page, train the KG and retest the utterance.
- add the utterance as an alternate question to the selected FAQ from the Knowledge Graph page, train the KG and retest the utterance.
Know more about Knowledge Graph Training.
Mark an Incorrect Match
When a user input matches an incorrect task, do the following to match it with the right intent:
- Above the matched intent name, click the Mark as incorrect match link.
- It opens the Matched Intent drop-down list to select another intent.
- Select the corresponding intent for the user input and train the bot.