지식 그래프 추출 서비스를 사용하면 기업의 기존 FAQ(자주 묻는 질문)를 봇 지식 그래프로 편리하게 이동할 수 있습니다. 이 기능은 웹 페이지, PDF 문서 등의 구조화되지 않은 콘텐츠뿐만 아니라 CSV 파일과 같은 구조화된 콘텐츠에서도 추출할 수 있도록 지원합니다. 추출을 완료한 후에는 사용이 편리한 인터페이스를 사용하여 질문과 답변을 편집하고 관련 지식 그래프 노드에 구성할 수 있습니다.
추출 프로세스
지식 추출 서비스를 사용하여 데이터를 지식 그래프로 이동하려면 다음 단계를 수행합니다.
- 추출: PDF, 웹 페이지, CSV 파일과 같은 질문-답변 데이터의 구조화되거나 구조화되지 않은 데이터 소스에서 기존 FAQ 콘텐츠를 추출합니다. 이 추출은 봇의 지식 그래프를 생성하기 전이나 후에 수행할 수 있습니다. 참고 사항: 지식 추출 서비스는 각 소스 유형에 대해 특정 콘텐츠 구조를 지원합니다. 자세한 내용은 지원되는 형식 섹션을 참조하세요.
- 편집: 데이터를 성공적으로 추출하면 지식 그래프로 이동하기 전에 질문과 답변 텍스트를 편집할 수 있습니다.
- 이동: KG(지식 그래프)를 생성하기 전이나 후에 봇에 데이터를 추가할 수 있습니다. 추출된 콘텐츠가 존재하기 전에 KG에 추출 콘텐츠를 추가하려고 하면, 봇이 자동으로 봇 이름을 가진 콘텐츠를 생성합니다.
지식 추출기를 사용해 추출된 콘텐츠를 지식 그래프에 추가할 수 있습니다.
- 지식 그래프에 추가는 선택한 질문을 지식 그래프의 루트 노드로 이동시킵니다. 이 옵션은 필요한 용어가 KG에 아직 추가되지 않았거나 봇에 지식 그래프가 없는 경우에 사용할 수 있습니다.
- 특정 용어에 추가: 봇이 이미 지식 그래프로 구성된 경우 선택한 콘텐츠를 필요한 노드로 끌어서 놓습니다.
웹 사이트에서 추출하기
- 콘텐츠를 추출하려는 봇을 엽니다.
- 빌드 상위 메뉴 항목을 선택합니다.
- 왼쪽 메뉴에서 대화형 스킬 > 지식 그래프를 클릭합니다.
- 추출 섹션에서 URL에서 추출을 클릭합니다.
- 추출용 이름을 입력합니다.
- 페이지의 URL을 입력한 다음 진행을 클릭합니다.

- 추출이 완료되면 성공 상태가 표시된 페이지가 나타납니다.
- 지식 정보에 관련 질문을 검토 및 추가합니다. 자세한 내용은 아래를 참조하세요.
파일에서 추출
참고 사항: 파일 크기는 5MB를 초과할 수 없습니다. 파일 형식에 대한 자세한 내용은 아래 지원되는 형식 섹션을 참조하세요.
- 콘텐츠를 추출하려는 봇을 엽니다.
- 빌드 상위 메뉴 항목을 선택합니다.
- 왼쪽 메뉴에서 대화형 스킬 > 지식 그래프를 클릭합니다.
- 추출 섹션에서 URL에서 추출을 클릭합니다.
- 찾아보기를 클릭하여 파일(PDF 또는 CSV)을 찾습니다.
- 진행을 클릭합니다.

- PDF 파일의 경우 추출 전에 문서에 주석을 달 수 있는 옵션이 있습니다. 자세한 내용은 아래를 참조하세요.
- 추출이 완료되면 성공 상태가 표시된 페이지가 나타납니다.
- 지식 정보에 관련 질문을 검토 및 추가합니다. 자세한 내용은 아래를 참조하세요.
주석 달기 및 추출
(v8.0에서 도입됨) 비즈니스와 관련된 모든 FAQ가 PDF 파일로 제공되지만 플랫폼에서 요구하는 형식에서는 제공되지 않을 수 있습니다. v8.0 이전 버전에서는 이러한 파일을 사용할 수 없습니다. 하지만 주석 도구를 도입하여 문서에 주석을 달아 콘텐츠의 주요 섹션을 식별할 수 있습니다. 지식 추출 엔진은 이 정보를 사용하여 문서에서 FAQ를 추출합니다. 참고 사항: PDF 문서에만 적용됩니다.
- 새 PDF 파일 또는 이전에 추출한 PDF 파일을 선택합니다. 해당 파일에 질문이 포함되어 있지 않은 경우 이전에 추출한 파일을 지식 그래프에 추가할 수 있습니다.
- 주석 달기 및 추출(이미 추출된 파일의 경우 검토 및 추가 옵션)을 클릭합니다.
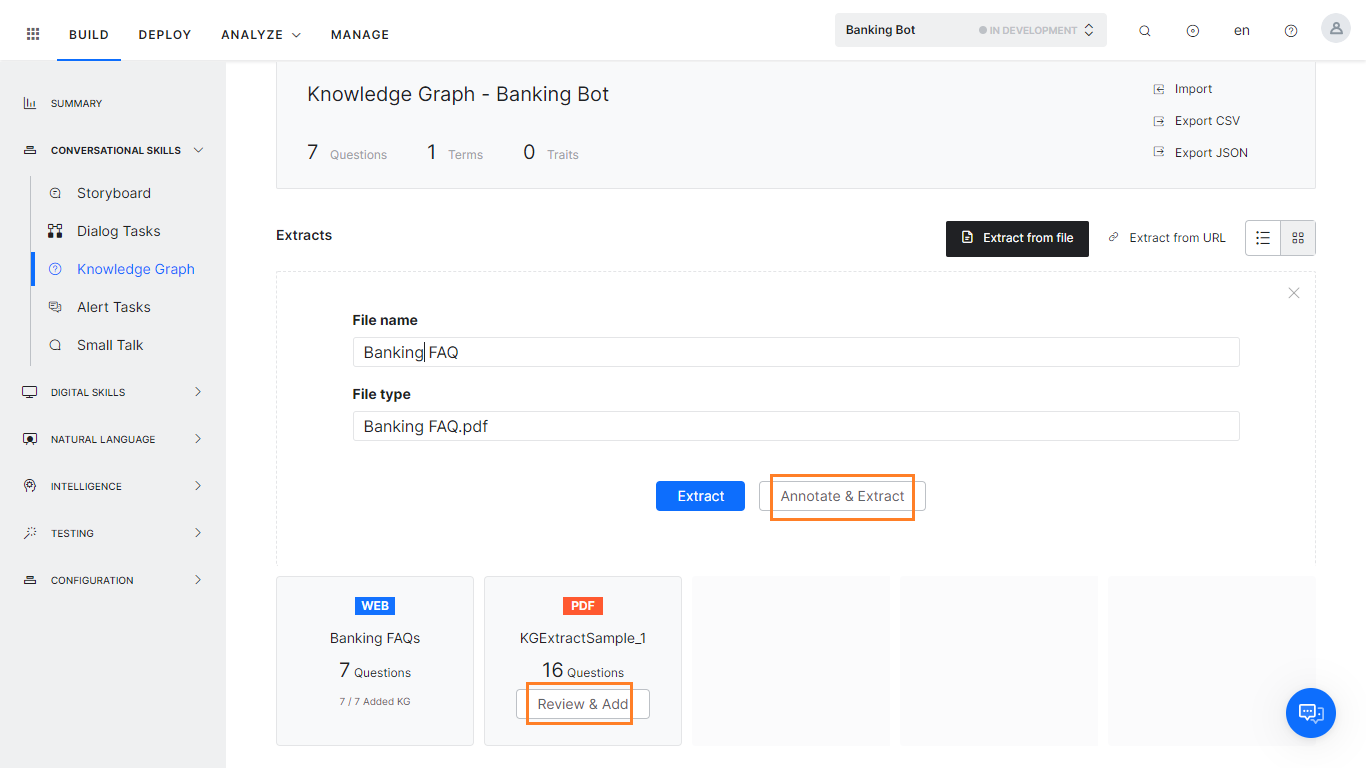
- PDF 문서가 주석 도구에 로드되어 문서의 여러 섹션에 주석을 달 수 있습니다.
- 주석을 달려면 텍스트를 선택하고 다음과 같이 태그를 지정합니다.
- 제목 태그는 질문을 식별하는 데 사용됩니다. 제목은 모델을 교육하여 질문을 식별하는 데 사용되며 두 개의 연속된 제목 사이의 콘텐츠를 이전 제목에 대한 대답으로 취급합니다.
- 헤더 – 이렇게 표시된 텍스트는 무시됩니다. 헤더로 표시된 텍스트는 모델을 식별하고 무시하도록 학습하는 데 사용됩니다. 헤더에 바닥글이나 단락 등의 텍스트를 표시하면 백엔드 ML 모델을 무효화하고 최적의 결과를 얻기 어려우므로 헤더에 텍스트를 무작위로 표시하는 것은 피해야 합니다.
- 바닥글 – 이렇게 표시된 텍스트는 무시됩니다. 바닥글로 표시된 텍스트는 모델을 식별하고 무시하도록 학습하는 데 사용됩니다. 헤더와 마찬가지로 바닥글에 헤더나 단락 등의 텍스트를 표시하면 백엔드 ML 모델을 무효화하고 최적의 결과를 얻기 어려우므로 바닥글에 텍스트를 무작위로 표시하는 것은 피해야 합니다.
- 제외 – 이 텍스트는 추출에 사용되지 않습니다.
- 페이지 무시 – 무시됨으로 표시된 페이지는 추출에 사용되지 않습니다.
- 주석을 제거하여 잘못된 주석을 수정할 수 있습니다.
- 지식 그래프 엔진은 추출 과정에서 제목, 헤더 및 바닥글을 사용합니다. 이 모델은 KG 엔진으로 학습했기 때문에 문서 전체에 주석을 달 필요가 없습니다. 두, 세 페이지에 제목, 헤더, 바닥글을 포함하여 주석을 달고 질문을 추출하고 검토할 수 있습니다. 결과가 만족스럽다면 지식 그래프에 계속해서 질문을 추가할 수 있습니다. 그렇지 않다면 결과가 만족스러울 때까지 주석 프로세스를 반복합니다.
- 추가 문서 정보가 제공됩니다.
- 문서 정보 – 문서의 이름, 크기 및 페이지 수입니다.
- 주석 요약 – 특정 페이지와 전체 문서의 각 범주에 대해 표시된 주석의 수입니다.
- 주석을 추가한 후 문서를 추출할 수 있습니다.

- 질문 검토 탭은 주석 및 학습에 따라 KG 엔진에서 추출한 질문을 제공합니다. 지식 그래프에 추가할 항목을 선택할 수 있습니다. 지식 그래프의 적절한 노드로 끌어서 놓습니다.
- 추출된 콘텐츠가 만족스럽지 않은 경우 언제든지 문서에 주석을 다시 달 수 있습니다. 주석 도구로 돌아가려면 주석 달기 탭을 클릭합니다.
- 주석을 다시 추가하기 위해 위에서 언급한 동일한 절차를 따릅니다. 다시 주석을 달려면 다음 사항을 염두에 두어야 합니다.
- 이 파일의 질문이 지식 그래프에 추가되지 않은 경우 문서에 주석을 다시 달 수 있습니다.
- 질문이 이미 추가된 경우 주석이 달린 문서의 복사본을 만들어 작업할 수 있습니다. 복사본이 생성되면 모든 주석이 그대로 유지됩니다.
추출된 콘텐츠 편집
- 봇을 엽니다.
- 빌드 상위 메뉴 항목을 선택합니다.
- 왼쪽 창에서 대화형 스킬 > 지식 그래프를 클릭합니다.
- 지식 추출 섹션에는 모든 추출 목록이 표시됩니다.
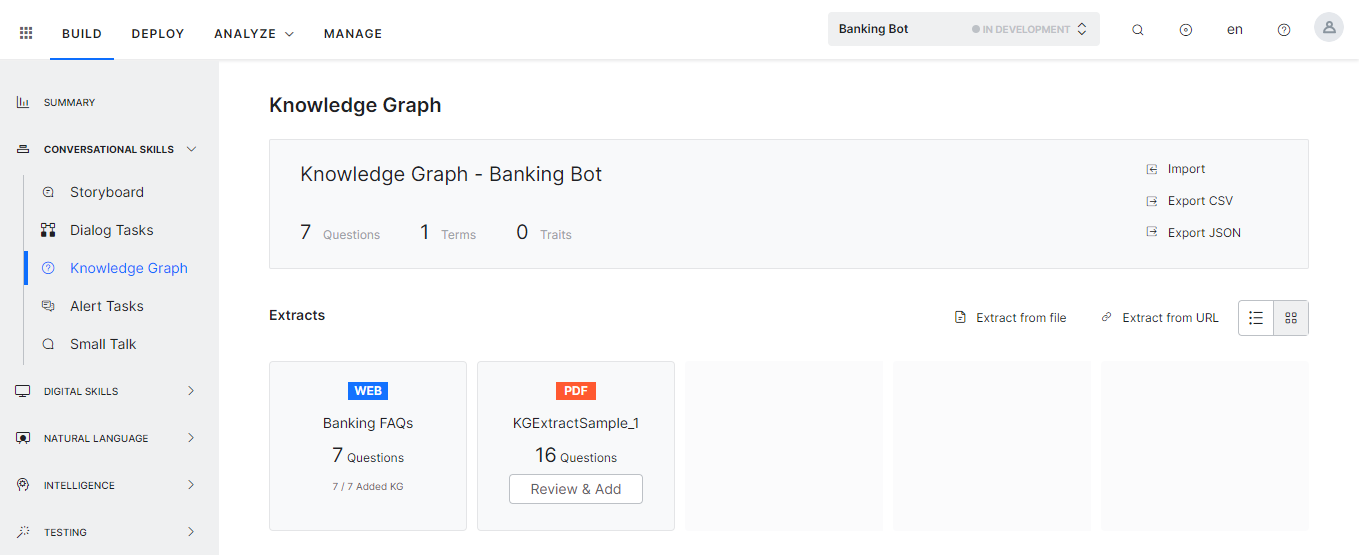
- 편집할 성공적인 추출의 이름을 클릭합니다.
- 편집할 질문-답변 쌍 위에 마우스를 놓고 편집 아이콘을 클릭합니다.

- 필요한 사항을 변경하고 저장을 클릭합니다.
추출된 콘텐츠 추가
추출된 내용을 지식 그래프에 추가하는 두 가지 방법이 있습니다.
추출 섹션에서
- 봇을 엽니다.
- 빌드 상위 메뉴 항목을 선택합니다.
- 왼쪽 메뉴에서 대화형 스킬 > 지식 그래프를 클릭합니다.
- 지식 추출 섹션에서 추가할 추출의 이름을 선택합니다.
- 필요한 Q&A를 추가할 노드/용어에 끌어서 놓습니다. 끌어서 놓으면 자식 노드가 확장됩니다.
- 여러 개의 Q&A를 선택하고 일괄 이동을 수행할 수 있습니다.
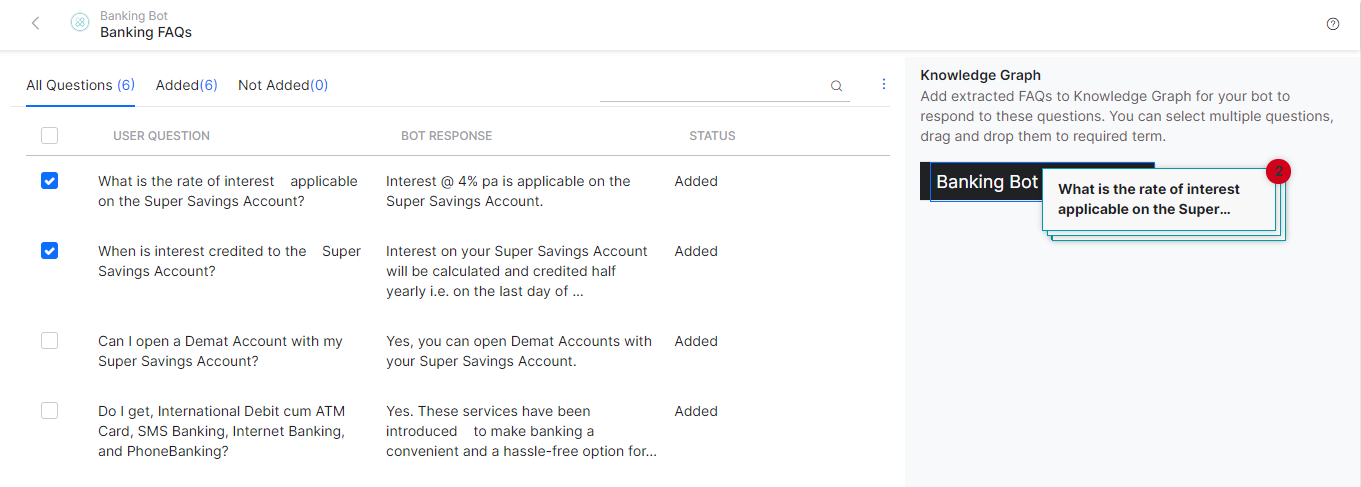
지식 그래프에서
- 봇을 엽니다.
- 빌드 상위 메뉴 항목을 선택합니다.
- 왼쪽 창에서 대화형 스킬 > 지식 그래프를 클릭합니다.
- 이러한 질문-답변을 추가할 노드를 선택합니다.
- 추출물에서 추가를 클릭합니다. 성공 및 실패한 추출 목록이 열립니다.
- 이동하려는 성공적인 추출의 이름을 클릭합니다.
- 이동할 질문-답변 쌍 옆의 확인란을 선택한 다음 추가를 클릭합니다.
 참고 사항: 추출에서 지식 그래프로 질문-답변 쌍을 이동한 후에는 다시 이동할 수 없습니다. 컬렉션에 이미 있는 추출에서 질문을 이동하려고 시도하면 플랫폼에서 중복 오류가 발생합니다. 지식 그래프에서 이동한 콘텐츠를 변경할 수 있습니다. 지식 그래프에서 질문을 수정하거나 삭제한 경우에도 개발자가 지식 그래프에 질문을 다시 추가할 수 있습니다.
참고 사항: 추출에서 지식 그래프로 질문-답변 쌍을 이동한 후에는 다시 이동할 수 없습니다. 컬렉션에 이미 있는 추출에서 질문을 이동하려고 시도하면 플랫폼에서 중복 오류가 발생합니다. 지식 그래프에서 이동한 콘텐츠를 변경할 수 있습니다. 지식 그래프에서 질문을 수정하거나 삭제한 경우에도 개발자가 지식 그래프에 질문을 다시 추가할 수 있습니다.
지원되는 형식
지식 추출 서비스는 지원되는 CSV, PDF 및 URL 형식에서만 FAQ를 추출을 지원합니다. 파일 크기는 5MB를 초과하지 않아야 합니다.
CSV
- 지식 추출 서비스는 첫 번째 열의 텍스트를 질문으로 해석하고 두 번째 열의 텍스트를 답변으로 해석합니다.
- 파일에 헤더가 없어야 합니다.
- 지식 추출 서비스는 다른 열에 있는 헤더와 텍스트를 무시합니다.
- 지식 추출 서비스는 PDF에서 콘텐츠를 처리하여 질문-답변 쌍으로 변환합니다.
- 목차가 있는 문서: 이상적으로는 목차가 있는 문서를 사용하는 것이 좋습니다. 이러한 경우 지식 추출 서비스는 목차를 먼저 추출한 다음 이를 사용하여 문서를 구문 분석하고 제목을 식별합니다. 목차에 있는 정보는 제목(제목, 부제목, 하위 부제목 등)의 계층을 파악하는 데 사용됩니다. 이러한 수준은 추출 프로세스의 일부로 구분 기호(제목 | 부제목 | 하위 부제목)로 세로 선으로 구분됩니다.
- 목차가 없는 문서: 이러한 경우 지식 추출 서비스는 글꼴 스타일 또는 글꼴 크기를 기준으로 제목을 식별하는 사전 학습된 기계 학습 모델을 사용합니다. 글꼴 크기를 사용하는 경우 제목 계층도 파악할 수 있습니다.
- 그런 다음 텍스트는 일관된 헤더와 단락 블록으로 형식이 지정됩니다.
웹 페이지
지식 추출 서비스는 다음 세 가지 형식의 FAQ 웹 페이지를 지원합니다.
- 선형 질문-답변 쌍이 포함된 일반 FAQ 페이지.
- 동일한 페이지에 답변을 안내하는 질문 하이퍼링크가 있는 페이지.
- 다른 페이지에 답변을 안내하는 질문 하이퍼링크가 있는 페이지.
다음 조건에서는 웹 페이지의 특정 FAQ를 추출할 수 없습니다.
- 질문 텍스트는 FAQ 페이지에서 여러 HTML 태그로 분할됩니다.
- 답변에 적용된 태그는 HTML DOM 구조에 따라 추출된 질문의 자식 태그도 아니고 형제 태그도 아닙니다.
- 질문에 답변에 대한 하이퍼링크가 없습니다(하이퍼링크가 있는 FAQ에 적용됨).
- 질문에 대한 답변이 하이퍼링크로 표시되어 있지만 답변 위에 질문 문항이 반복되지 않는 경우(하이퍼링크가 있는 FAQ에 적용됨).
페이지가 위에 언급된 FAQ 페이지 유형을 두 개 이상 포함하는 경우 전체 FAQ 페이지 추출이 실패합니다.
ナレッジグラフ抽出サービスを使用すると、企業の既存の「よくある質問と答」(FAQ)をボットナレッジグラフの中へ簡単に移動できます。
この機能は、WebページやPDF文書などの非構造化コンテンツからの抽出だけでなく、CSVファイルなどの構造化コンテンツからの抽出もサポートしています。
抽出完了後は、使いやすいインターフェースを使って質問と回答を編集することができ、また、関連するナレッジグラフノードの下でこれらを整理することができます。
抽出プロセス
ナレッジ抽出サービスを利用したデータのナレッジグラフへの移動は、以下のような手順で行われます。
- 抽出:PDF、Webページ、CSVファイルなど、構造化または非構造化された質問と回答のデータソースから、既存のFAQコンテンツを抽出します。この抽出は、ボットのナレッジグラフを作成する前でも後でも行うことができます。 メモ:ナレッジ抽出サービスは、ソースタイプごとに特定のコンテンツ構造をサポートしています。詳細は、サポートされている形式セクションをご参照ください。
- 編集:データの抽出に成功すると、ナレッジグラフに移す前に質問を編集し、テキストに回答することができます。
- 移動:ボットにデータを追加するのは、ナレッジグラフ(KG)を作成する前でも後でも可能です。抽出したコンテンツが存在する前にKGに追加しようとすると、ボットが自動的にボット名でそれを作成します。
ナレッジエクストラクターによって、抽出したコンテンツをナレッジグラフに追加することができます。
- ナレッジグラフに追加で、選択した質問をナレッジグラフのルートノードに移動させます。このオプションは、必要な用語がまだKGに追加されていない場合や、ボットにナレッジグラフが存在していない場合に使用できます。
- 特定用語に追加:ボットがナレッジグラフをすでに構成している場合、必要なノードに選択したコンテンツをドラッグアンドドロップします。
Webサイトからの抽出
- コンテンツの抽出先ボットを開きます。
- 構築のトップメニューアイテムを選択します。
- 左側ペインから、会話スキル > ナレッジグラフをクリックします。
- 抽出セクションで、URLから抽出をクリックします。
- 抽出のための名前を入力します。
- ページのURLを入力して、 続行をクリックします。
- 抽出が完了すると、成功ステータスのページが表示されます。
- ナレッジグラフに対して、関連する質問を見直して追加します。 詳細は下記をご覧ください。
ファイルから抽出
メモ:ファイルサイズは5MB以下とします。ファイル形式の詳細については、サポートされている形式をご参照ください。
- コンテンツの抽出先ボットを開きます。
- 構築のトップメニューアイテムを選択します。
- 左側ペインから、会話スキル > ナレッジグラフをクリックします。
- 抽出セクションで、URLから抽出をクリックします。
- ブラウズをクリックして、ファイル(PDFまたはCSV)を探します。
- 続行をクリックします。
- PDFファイルの場合は、抽出前に文書に注釈を付けるオプションがあります。詳細は以下をご確認ください。
- 抽出が完了すると、成功ステータスのページが表示されます。
- ナレッジグラフに対して、関連する質問を見直して追加します。 詳細は下記をご覧ください。
注釈と抽出
(v8.0で導入) ビジネスに関連するすべてのFAQがPDFファイルであって、プラットフォームで義務付けられている形式ではないかもしれません。v8.0より前のバージョンでは、このようなファイルは使用できません。しかし、アノテーションツールの導入により、コンテンツの重要なセクションを特定して文書に注釈を付けることができます。ナレッジ抽出エンジンはこの情報を利用して、文書からFAQを抽出します。メモ:これは、PDF文書にのみ適用されます。
- 新規にまたは過去に抽出したPDFファイルを選択します。なお、以前に抽出したファイルを使用することはできますが、そのファイルの質問をナレッジグラフに追加することはできません。
- 注釈と抽出をクリックします(すでに抽出されたファイルの場合は「見直して追加」オプション)。
- PDF文書がアノテーションツールに読み込まれ、文書のさまざまなセクションにアノテーションを施すことができます。
- 注釈をつけるには、テキストを選択し、以下のようにタグをつけます。
- 見出しタグは、質問を識別するために使用します。見出しは、質問を識別するためのモデルのトレーニングに使用され、2つの連続した見出しの間の内容は、前の見出しの回答として扱われます。
- ヘッダー – このようにマークされたテキストは無視されます。ヘッダーとしてマークされたテキストは、モデルの識別と無視のトレーニングに使用されます。フッターやパラグラフなどのテキストをヘッダーとしてマークすると、バックエンドのMLモデルが無効になり、最適な結果が得られなくなるため、テキストをランダムにヘッダーとしてマークすることは避ける必要があります。
- フッター – このようにマークされたテキストは無視されます。フッターとしてマークされたテキストは、モデルの識別と無視のトレーニングに使用されます。フッターと同様にヘッダーやパラグラフなどのテキストをフッターとしてマークすると、バックエンドのMLモデルが無効になり、最適な結果が得られなくなるため、テキストをランダムにフッターとしてマークすることは避ける必要があります。
- 除外 – このテキストは抽出には使用されません。
- 無視ページ – 無視とマークされたページは、抽出に使用されません。
- 誤ったアノテーションを修正するために、アノテーションを除外することができます。
- ナレッジグラフエンジンでは、抽出処理の際に見出し、ヘッダー、フッターを使用します。モデルはKGエンジンによってトレーニングされるため、文書全体に注釈を施す必要はありません。見出し、ヘッダー、フッターで数ページに注釈を施し、質問を抽出して見直すことができます。結果に満足した場合、ナレッジグラフへの質問の追加に進むことができます。そうでない場合は、満足のいく結果が得られるまで、アノテーション処理を繰り返します。
- 追加の文書情報が提供されます。
- 文書情報 – 文書の名前、サイズ、ページ数。
- アノテーション概要 – 特定のページおよび文書全体について、各カテゴリーにマークされたアノテーションの数。
- アノテーションを行った後は、文書を抽出することができます。
- 質問の見直しタブでは、アノテーションやトレーニングに応じてKGエンジンが抽出した質問が表示されます。ナレッジグラフに追加したいものを選択することができます。それらをナレッジグラフの適切なノードにドラッグアンドドロップします。
- 抽出されたコンテンツに満足できない場合は、いつでも文書に再注釈を施すことができます。アノテーションタブをクリックするだけで、アノテーションツールに戻ることができます。
- 再アノテーションについても、上記と同様の手順に従います。再アノテーションを行う際には、以下の点に留意する必要があります。
- このファイルからの質問がナレッジグラフに追加されていない場合、文書に再注釈を施すことができます。
- すでに質問が追加されている場合は、注釈付きドキュメントのコピーを作成して作業することもできます。作成されたコピーには、すべてのアノテーションがそのまま残っています。
抽出したコンテンツの編集
- ボットを開きます。
- 構築のトップメニューアイテムを選択します。
- 左側ペインから、会話スキル > ナレッジグラフをクリックします。
- ナレッジ抽出セクションには、すべての抽出物のリストが表示されます。
- 編集しようとする成功した抽出物の名前をクリックします。
- 修正する質問と回答のペアをポイントし、[編集]アイコンをクリックします。
- 必要な変更を行い、保存をクリックします。
抽出したコンテンツの追加
抽出したコンテンツをナレッジグラフに追加するには、2つの方法があります。
抽出セクションより
- ボットを開きます。
- 構築のトップメニューアイテムを選択します。
- 左側ペインから、会話スキル > ナレッジグラフをクリックします。
- ナレッジ抽出セクションから、追加したい成功した抽出物の名前を選択します。
- 必要なQ&Aを、追加したいノード/用語にドラッグアンドドロップします。ドラッグアンドドロップすると、子ノードが展開されます。
- 複数のQ&Aを選択し、一括移動することができます。
ナレッジグラフより
- ボットを開きます。
- 構築のトップメニューアイテムを選択します。
- 左側ペインから、会話スキル > ナレッジグラフをクリックします。
- この質問・回答を追加するノードを選択します。
- 抽出から追加をクリックします。成功した抽出、失敗した抽出のリストを開きます。
- 移動先の成功した抽出物の名前をクリックします。
- 移動させたい質問・回答ペアの横にあるチェックボックスを選択して、「追加」をクリックします。
メモ:質問・回答ペアを抽出物からナレッジグラフに移動させると、もう一度移動させることはできません。このプラットフォームでは、コレクションにすでに存在する質問を抽出物から移動させようとすると、重複エラーが発生します。移動したコンテンツの変更は、ナレッジグラフから行うことができます。しかし、質問が修正されたり、ナレッジグラフから除外された場合、開発者はその質問をもう一度ナレッジグラフに追加することができます。
サポートされている形式
ナレッジ抽出サービスでは、サポートされているCSV、PDF、URL形式からのみ、FAQの抽出をサポートすることができます。なお、ファイルサイズは5MB以下とします。
CSV
- ナレッジ抽出サービスは、1列目のテキストを質問とし、2列目のテキストを回答として解釈します。
- ファイルにヘッダーを付けてはいけません。
- ナレッジ抽出サービスでは、ヘッダーや他の列にあるテキストは無視します。
- ナレッジ抽出サービスは、PDFからコンテンツを処理し、質問・回答ペアに変換します。
- 目次のある文書:目次のある文書が理想的であり、推奨されます。このような場合、ナレッジ抽出サービスは、まず目次を抽出し、それを使用して文書を解析し、見出しを特定します。目次に記載されている情報をもとに、見出しの階層(見出し、小見出し、副小見出しなど)を導き出します。これらのレベルは、抽出処理の一環として、デリミター(見出し|小見出し|副小見出し)として縦線で区切られます。
- 目次のない文書:このような場合、ナレッジ抽出サービスでは、事前にトレーニングした機械学習モデルを使用して、フォントスタイルまたはフォントサイズに基づいて見出しを識別します。フォントサイズを利用する場合は、見出しの階層も導き出すことができます。
- 統一されたヘッダーと段落ブロックで、テキストをフォーマット化します。
Webページ
ナレッジ抽出サービスでは、以下の3種類の形式のFAQ Webページをサポートしています。
- 直線的な質問・回答ペアで構成されたプレーンなFAQページ。
- 質問のハイパーリンクが同じページの回答を指しているページ。
- 質問のハイパーリンクが別のページの回答を指しているページ。
以下の条件では、Webページ上の特定のFAQの抽出に失敗します。
- FAQページでは、質問テキストが複数のHTMLタグに分割されます。
- 回答に適用されたタグは、HTML DOMの構造上、抽出された質問の子でも兄弟姉妹でもありません。
- 質問には回答へのハイパーリンクがありません(ハイパーリンクのあるFAQに適用)。
- 質問が回答にハイパーリンクされているが、質問テキストが回答の上に繰り返されない場合(ハイパーリンクのあるFAQに適用)。
上記のような複数のFAQページタイプで構成されている場合は、FAQページ全体の抽出に失敗します。
The Knowledge Graph Extraction service enables you to effortlessly move your enterprise’s existing Frequently Asked Questions (FAQ content) into bot Knowledge Graph.
The feature supports the extraction from unstructured content such as web pages and PDF documents as well as from structured content such as CSV files.
After completing the extraction, you can edit the question and answers using an easy-to-use interface and organize them under the relevant Knowledge Graph nodes.
Extraction Process
Moving data using the Knowledge Extraction service to the Knowledge Graph involves the followings steps:
- Extracting: Extract the existing FAQ content from structured or unstructured sources of question-answer data such as PDF, web pages, and CSV files. This extraction can be done before or after creating a Knowledge Graph for the bot.
Note: The Knowledge Extraction service supports a specific content structure for each source type. Refer to the Supported formats section for details.
- Editing: Upon successful data extraction, you can edit the questions and answer text before moving it to the Knowledge Graph.
- Moving: You can add data into a bot before or after creating a Knowledge Graph (KG). If you try to add the extracted content to a KG before it exists, the bot automatically creates one with the bot’s name.
The Knowledge Extractor allows you to add the extracted content to the Knowledge Graph:
- Add to Knowledge Graph moves the selected questions to the root node of the Knowledge Graph. You can use this option when the required term is not yet added to the KG or when the bot does not have a Knowledge Graph.
- Add to Specific Term: If the bot already consists of a Knowledge Graph, you drag-drop the selected content to the required nodes.
Extract from a Website
- Open the bot to which you want to extract the content.
- Select the Build top menu item.
- From the left menu, click Conversational Skills > Knowledge Graph.
- Under the Extracts section, click Extract from URL.
- Enter a Name for extraction.
- Enter the URL of the page, and then click Proceed.
- Once the extraction is complete, the page with the success status appears.
- Review & Add the relevant questions to your Knowledge Graph, see below for details.
Extract from File
NOTE: File size must not exceed 5MB.
For file format details, refer to the Supported formats section below.
- Open the bot to which you want to extract the content.
- Select the Build top menu item.
- From the left menu, click Conversational Skills > Knowledge Graph.
- Under the Extracts section, click Extract from URL.
- Click Browse to locate the file (PDF or CSV).
- Click Proceed.
- For PDF files you have an option to annotate the document before extraction. See below for details.
- After the extraction is complete, a page with the success status is displayed.
- Review & Add the relevant questions to your Knowledge Graph, see below for details.
Annotate & Extract
(introduced in v8.0)
You might have all the FAQs related to your business in a PDF file but not in the format mandated by the platform. Before v8.0, you can not use such files. But with the introduction of the Annotation tool, you can annotate documents identifying the key sections of the content. The Knowledge Extraction engine uses this information to extract the FAQs from the document.
NOTE: This is applicable only for PDF documents.
- Select a new or previously extracted PDF file. Note that you can use a previously extracted file provided no questions from that file are added to the Knowledge Graph.
- Click Annotate & Extract (Review & Add option in case of an already extracted file).
- The PDF document is loaded into the Annotation Tool allowing you to annotate the various sections in the document.
- To annotate, select the text and tag it as follows:
- Heading tag is used to identify questions. Headings are used to train the model to identify the questions and the content between two consecutive headings are treated as the answer for the preceding heading.
- Header – Text thus marked is ignored. Text marked as Headers is used to train the model to identify and ignore. Random marking of texts as headers must be avoided as marking text such as footer or paragraphs as the header invalidates the backend ML model, and will not produce the optimal results.
- Footer – Text thus marked is ignored. Text marked as Footers is used to train the model to identify and ignore. Same as the Header, random marking of texts as footers must be avoided as marking text such as header or paragraphs as the footer invalidates the backend ML model, and will not produce the optimal results.
- Exclude – This text is not used for extraction.
- Ignore Page – Pages marked as ignored are not used for extraction.
- You can Remove Annotation to rectify any incorrect annotations.
- The Knowledge Graph Engine uses the headings, headers, and footers in the extraction process. Since the model is trained by the KG Engine, you need not annotate the entire document. You can annotate a couple of pages with headings, headers, and footers, extract and review the questions. If satisfied, you can proceed with adding questions to the Knowledge Graph, else repeat the annotation process till you get satisfactory results.
- Additional document information is provided:
- Document Info – Name, Size, and the Number of Pages of the document.
- Annotation Summary – Number of annotations marked for each category for the particular page and entire document.
- After you annotate, you can Extract the document.
- Review Questions tab gives the questions extracted by the KG Engine as per the annotations and training. You can select the ones you want to add to the Knowledge Graph. Drag and drop them to the appropriate node in your Knowledge Graph.
- If you are not satisfied with the extracted content, you can always re-annotate the document. Just click on the Annotate tab to return to the annotation tool.
- The same procedure mentioned above is followed for re-annotation. The following points need to be kept in mind for re-annotation:
- You can re-annotate the document provided no questions from this file is added to the Knowledge Graph.
- In case questions are already added, you can choose to create a copy of the annotated document and work with it. The copy is created will have all the annotations intact.
Edit the Extracted Content
- Open the bot.
- Select the Build top menu item.
- From the left pane, click Conversational Skills > Knowledge Graph.
- The Knowledge Extraction section displays the list of all extractions.
- Click the name of a successful extract you want to edit.
- Hover over the question-answer pair to modify it and click the edit icon.
- Make the necessary changes and click Save.
Add the Extracted Content
There are two ways to add the extracted content to the Knowledge Graph.
From the Extracts Section
- Open the bot.
- Select the Build top menu item.
- From the left menu, click Conversational Skills > Knowledge Graph.
- From the Knowledge Extraction section, select the name of a successful extract you want to add.
- Drag and drop the required Q&A to the node/term you want to add. As you drag and drop, the child nodes will be expanded.
- You can select multiple Q&As and perform a bulk move.
From Knowledge Graph
- Open the bot.
- Select the Build top menu item.
- From the left pane, click Conversational Skills > Knowledge Graph.
- Select the node you want to add these Question-Answers.
- Click Add from Extraction. It opens the list of successful and failed extractions.
- Click the name of a successful extract you want to move.
- Select the checkboxes next to the question-answer pairs that you want to move and then click Add.
Note: Once you move a question-answer pair from the extract to the knowledge graph, you cannot move it again. The platform throws a duplicate error when you try to move a question from the extract that is already present in the collection. You can make any changes to the moved content from the knowledge graph. However, if the question is modified or removed from the knowledge graph, then the developer is allowed to add it again to the knowledge graph.
Supported Formats
The Knowledge Extraction service supports extracting FAQs only from supported CSV, PDF, and URL formats.
Note that the file size must not exceed 5MB.
CSV
- The Knowledge Extraction service interprets the text in the first column as a question and that in the second column as an answer.
- The file must not have any headers.
- The Knowledge Extraction service ignores any headers and the text present in the other columns.
- The Knowledge Extraction service processes the content from a PDF and converts it into question-answer pairs.
- Documents with the table of contents: Ideally a document with a table of contents is preferred. In such cases, the Knowledge Extraction service extracts the table of contents first and then uses it to parse the document and identify headings. The information present in the table of contents is used to derive the hierarchy of headings (headings, subheadings, sub-sub headings, etc.). These levels are separated by a vertical line as a delimiter (heading | subheading | sub-sub heading) as part of the extraction process.
- Documents with no table of contents: In such cases, the Knowledge Extraction service uses a pre-trained machine learning model that identifies headings based on either font style or font size. In the case of using font size, the heading hierarchy can also be derived.
- The text is then formatted with a uniform header and paragraph blocks.
Web Pages
The Knowledge Extraction service supports the following three different formats of FAQ web pages:
- Plain FAQ pages with linear question-answer pairs.
- Pages with question hyperlinks that point to answers on the same page.
- Pages with question hyperlinks that point to answers on a different page.
Extraction of certain FAQs on the webpage fails under the following conditions:
- The question text is split between multiple HTML tags on the FAQ page.
- The tag applied to the answer is neither the child nor the sibling of the extracted question as per the HTML DOM structure.
- The question does not have a hyperlink to the answer (applies to FAQs with hyperlinks).
- When the questions hyperlink to the answer, but the question statement is not repeated above the answer (applies to FAQs with hyperlinks).
The extraction of the entire FAQ page fails if the page consists of more than one FAQ page types mentioned above.