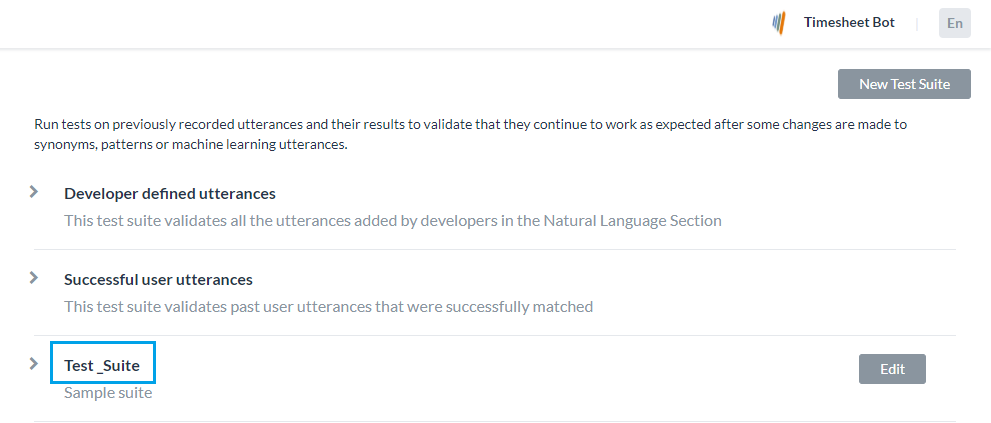
봇을 구축하고 학습시킨 후, 가장 중요한 질문은여러분의 봇의 학습 모델은 얼마나 좋을것인가입니다. 따라서, 봇의 성능을 평가하는 것은 봇이 사용자의 발화를 얼마나 잘 이해하는지 설명하는 데 중요합니다. 배치 테스트 기능을 사용하면 봇이 주어진 발화 세트에서 예상되는 의도와 엔티티를 올바르게 인식하는 능력이 있는지 식별하는 데 도움이 됩니다. 여기에는 일련의 테스트를 수행하여 자세한 통계 분석을 얻고 봇의 ML 모델 성능을 측정하는 과정이 포함됩니다. 배치 테스트를 수행하려면, 빌더에서 사용할 수 있는 사전 정의된 테스트 스위트를 사용하거나 사용자 정의 테스트 스위트를 만들 수 있습니다. 요구 사항에 따라, 테스트 스위트를 실행하여 원하는 결과를 볼 수 있습니다. 이 옵션은 빌드 탭에서 왼쪽 메뉴의 테스트 -> 배치 테스트 옵션에서 액세스할 수 있습니다. 
테스트 스위트 관리하기
Kore.ai는 배치 테스트 수행을 위해 즉시 사용할 수 있는 테스트 스위트를 몇 가지 제공합니다. ‘개발자가 정의한 발화’ 및 ‘성공적인 사용자 발화’는 배치 테스트 수행을 위해 실행할 수 있는 내장된 테스트 스위트입니다. 사용자 정의 발화 세트를 테스트하기 위해 새 테스트 스위트를 만들 수도 있습니다. 
개발자가 정의한 발화
이 테스트 스위트는 기계 학습 발화 화면에서 개발자가 이전에 추가하고 학습시킨 발화를 검증합니다. 이 테스트 스위트를 사용한다는 것은 개발자가 봇의 모든 작업에 대해 추가한 전체 발화 세트를 총체적으로 테스트하는 것을 의미합니다.
성공적인 사용자 발화
이 테스트 스위트에는 의도가 성공적으로 일치한 모든 사용자 발화가 포함되어 있으며 해당 작업은 완전히 실행됩니다. 또한, 분석 모듈의 '발견된 의도' 섹션에서 이러한 발화를 찾을 수 있습니다.
새 테스트 스위트 추가하기
새 테스트 스위트를 사용하면 배치 파일에서 한 번에 일괄적으로 테스트 발화의 배열(데이터 세트라고도 함)을 가져올 수 있습니다. 데이터 세트 파일은 CSV 또는 JSON 형식으로 작성해야 하며 최대 10,000개의 발화를 포함할 수 있습니다. 새 테스트 스위트 옵션을 사용하여 테스트 스위트 생성의 일부로 샘플 CSV 또는 JSON 파일 형식을 다운로드할 수 있습니다. 테스트 스위트용 JSON 형식 사용자 정의 스위트 생성을 위해 JSON 형식을 사용하면 테스트 사례 배열(각 테스트 사례는 테스트할 발화, 발화와 비교해 테스트할 의도로 구성되어야 함)을 정의할 수 있으며, 선택적으로 발화에서 결정될 예상 엔티티 목록을 정의할 수 있습니다. 예상되는 의도가 하위 의도인 경우, 고려할 부모 의도를 포함할 수도 있습니다. 
- 다중 항목이 활성화된 엔티티의 경우, 값을 다음과 같이 지정해야 합니다.
entity1||entity2 - 복합 엔티티에는 다음 형식의 값이 필요합니다.
component1name:entityValue|component2name:entityValue2
- 엔티티를 추출하는 순서는 다음과 같이 지정할 수 있습니다.
"entityOrder":["TransferAmount", "PayeeName"]. 순서가 제공되지 않거나 부분적으로 제공된 경우, 플랫폼은 모든 엔티티를 포괄하는 최단 경로를 기본 순서로 결정합니다.

| 속성 이름 | 유형 | 설명 |
|---|---|---|
| 테스트 케이스 | 배열 |
다음과 같이 구성됩니다.
|
| input | 문자열 | 최종 사용자 발화. 배치 테스트에서 발화가 3,000자를 초과하는 경우 배치 테스트 업로드는 실패합니다. |
| intent | 문자열 | 최종 사용자 발화의 목적을 결정(FAQ 테스트 사례의 경우 작업 이름 또는 주요 질문이 될 수 있음) 이 속성은 접두사 "특성" 을 사용하여 이 발화에 대해 식별할 특성을 정의하는 데 사용할 수 있습니다. 예: 특성: 특성 이름1|| 특성 이름2||특성 이름3 이 속성은 예상되는 스몰 토크 패턴을 포함할 수 있습니다. |
| parentIntent | 문자열[옵션] | 의도가 하위 의도인 경우 고려할 부모 의도를 정의합니다. 스몰 토크의 경우, 이 필드는 스몰 토크가 문맥적 후속 의도일 때 채워져야 합니다. 다단계 문맥적 의도인 경우, 부모 의도를 구분자 ||로 구분해야 합니다. |
| entities | 배열[옵션] |
입력 문장에서 결정될 엔티티 배열로 구성됩니다.
|
| entityValue | 문자열 | 발화에서 결정될 것으로 예상되는 엔티티의 값입니다. 예상되는 엔티티 값을 문자열로 정의하거나 정규 표현식을 사용할 수 있습니다. 배치 테스트를 위해, 플랫폼은 모든 엔티티 값을 문자열 형식으로 평탄화합니다. 자세한 내용은 엔티티 형식 변환을 참조하세요. |
| entityName | 문자열 | 발화에서 결정될 것으로 예상되는 엔티티의 이름 |
| entityOrder | 배열[옵션] | 엔티티가 추출되는 순서를 지정하는 엔티티 이름의 배열입니다. 순서가 제공되지 않거나 부분적으로 제공된 경우, 플랫폼은 모든 엔티티를 포괄하는 최단 경로를 기본 순서로 결정합니다. |
테스트 스위트용 CSV 형식 사용자 정의 스위트 생성을 위해 CSV 형식을 사용하면 테스트 케이스를 CSV의 레코드로 정의할 수 있으며(각 테스트 케이스는 테스트할 발화, 발화와 비교해 테스트할 의도로 구성되어야 함), 선택적으로 발화에서 결정될 엔티티를 정의할 수 있습니다. 테스트 사례에서 한 문장에서 추출할 엔티티가 하나 이상 필요한 경우, 탐지될 추가 엔티티 각각에 대한 추가 행을 포함해야 합니다. 예상되는 의도가 하위 의도인 경우, 고려할 부모 의도를 포함할 수도 있습니다. 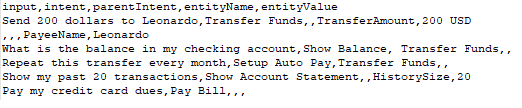
- 다중 항목이 활성화된 엔티티의 경우 값을 다음과 같이 지정해야 합니다.
entity1||entity2 - 복합 엔티티에는 다음 형식의 값이 필요합니다.
component1name:entityValue|component2name:entityValue2
- 엔티티 값의 추출 순서는 다음 형식으로 참조할 수 있습니다.
entity3>entity4>entity1. 순서가 제공되지 않거나 부분적으로 제공된 경우, 플랫폼은 모든 엔티티를 포괄하는 최단 경로를 기본 순서로 결정합니다.
| 열 이름 | 유형 | 설명 |
|---|---|---|
| input | 문자열 | 최종 사용자가 제공한 발화입니다. 배치 테스트에서 발화가 3,000자를 초과하는 경우 배치 테스트 업로드는 실패합니다. |
| intent | 문자열 | 최종 사용자 발화의 목적을 결정(FAQ 테스트 사례의 경우 작업 이름 또는 주요 질문이 될 수 있음) 이 속성은 접두사 "특성" 을 사용하여 이 발화에 대해 식별할 특성을 정의하는 데 사용할 수 있습니다. 예: 특성: 특성 이름1|| 특성 이름2||특성 이름3 이 속성은 예상되는 스몰 토크 패턴을 포함할 수 있습니다. |
| parentIntent | 문자열[옵션] | 의도가 하위 의도인 경우 고려될 상위 의도를 정의합니다. 스몰 토크의 경우, 이 필드는 스몰 토크가 문맥적 후속 의도일 때 채워져야 하며 후속 의도 조건이 충족된다고 가정할 때 의도가 일치할 것입니다. 다단계 문맥적 의도의 경우 부모 의도는 구분자 ||로 구분해야 합니다 |
| entityValue | 문자열[옵션] | 발화에서 결정될 것으로 예상되는 엔티티의 값입니다. 예상되는 엔티티 값을 문자열로 정의하거나 정규 표현식을 사용할 수 있습니다. 배치 테스트를 위해, 플랫폼은 모든 엔티티 값을 문자열 형식으로 평탄화합니다. 자세한 내용은 엔티티 형식 변환을 참조하세요. |
| entityName | 문자열[옵션] | 발화에서 결정될 것으로 예상되는 엔티티의 이름 |
| entityOrder | 배열[옵션] | 엔티티가 추출되는 순서를 지정하는 >로 구분된 엔티티 이름의 배열입니다. 순서가 제공되지 않거나 부분적으로 제공된 경우, 플랫폼은 먼저 NER을 처리하고 패턴 엔티티를 처리한 다음 나머지 엔티티를 처리하는 암시적 순서를 정의합니다. |
엔티티 형식 변환
| 엔티티 유형 | 샘플 엔티티 값 유형 | Flat 형식의 값 | 키 순서 |
|---|---|---|---|
| 주소 | P.O. Box 3700 Eureka, CA 95502 | P.O. Box 3700 Eureka, CA 95502 | |
| 공항 | { "IATA": "IAD", "AirportName": "Washington Dulles International Airport", "City": "Washington D.C.", "CityLocal": "Washington", "ICAO": "KIAD", "Latitude": "38.94", "Longitude": "-77.46" } | Washington Dulles International Airport IAD KIAD 38.94 -77.46 Washington D.C. Washington | AirportName IATA ICAO Latitude Longitude City CityLocal |
| 도시 | Washington | Washington | |
| 국가 | { "alpha3": "IND", "alpha2": "IN", "localName": "India", "shortName": "India", "numericalCode": 356} | IN IND 356 India India | alpha2 alpha3 numericalCode localName shortName |
| 회사 또는 조직 이름 | Kore.ai | Kore.ai | |
| 색상 | Blue | Blue | |
| 통화 | [{ "code": "USD", "amount": 10 }] | 10 USD | 금액 코드 |
| 날짜 | 2018-10-25 | 2018-10-25 | |
| 날짜 기간 | { "fromDate": "2018-11-01", "toDate": "2018-11-30" } | 2018-11-01 2018-11-30 | fromDate toDate |
| 날짜 시간 | 2018-10-24T13:03:03+05:30 | 2018-10-24T13:03:03+05:30 | |
| 설명 | 샘플 설명 | 샘플 설명 | |
| 이메일 | user1@emaildomain.com | user1@emaildomain.com | |
| 항목 목록(열거됨) | Apple | Apple | |
| 항목 목록(조회) | Apple | Apple | |
| 위치 | { "formatted_address": "8529 Southpark Cir #100, Orlando, FL 32819, USA", "lat": 28.439148,"lng": -81.423733 } | 8529 Southpark Cir #100, Orlando, FL 32819, USA 28.439148 -81.423733 | formatted_address lat lng |
| 숫자 | 100 | 100 | |
| 사람 이름 | Peter Pan | Peter Pan | |
| 백분율 | 0.25 | 0.25 | |
| 전화번호 | +914042528888 | +914042528888 | |
| 수량 | { "unit": "meter", "amount": 16093.4, "type": "length", "source": "10 miles" } | 16093.4 미터 길이 10 마일 | amount unit type source |
| 문자열 | 샘플 문자열 | 샘플 문자열 | |
| 시간 | T13:15:55+05:30 | T13:15:55+05:30 | |
| 시간대 | -04:00 | -04:00 | |
| URL | https://kore.ai | https://kore.ai | |
| 우편번호 | 32819 | 32819 |
데이터 세트 파일 가져오기
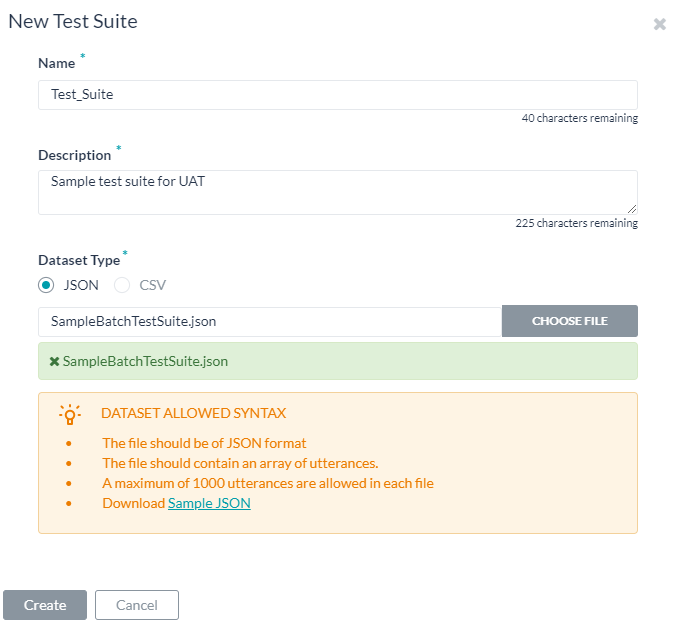
- 배치 테스트 페이지에서 새 테스트 스위트를 클릭합니다. 데이터 세트를 가져오기 위한 대화 상자가 나타납니다.
- 이름, 설명을 입력하고, 데이터 세트 파일의 각 상자에서 데이터 세트 유형을 선택합니다.
- 데이터 세트 파일을 가져오려면, 파일 선택을 클릭하고 선택한 데이터 세트 유형에 따라 발화가 포함된 JSON 또는 CSV 파일을 찾아 선택합니다.

- 생성을 클릭합니다. 데이터 세트 파일이 배치 테스트 페이지에서 테스트 스위트를 실행할 수 있는 옵션으로 나타납니다.

테스트 스위트 실행하기
다음 단계에서는 봇에서 배치 테스트를 실행하는 방법과 테스트 결과를 기반으로 발화에 대한 자세한 분석 보고서를 얻는 방법을 안내합니다. 시작하려면, 빌더의 테스트 섹션에서 배치 테스트를 클릭합니다.
참고: 테스트하기 전에, 봇을 추가하고 기계 학습을 사용하여 상당히 많은 발화로 봇을 학습시키는 것이 필수입니다.
테스트 스위트(예: 개발자가 정의한 발화)를 실행하려면, 개발자가 정의한 발화 및 테스트 스위트 실행을 차례로 클릭합니다. 그러면 개발자가 정의한 발화의 배치 테스트가 시작됩니다. 개발 중 또는 게시된 버전의 봇에 대해 테스트 스위트를 실행할 수 있습니다.
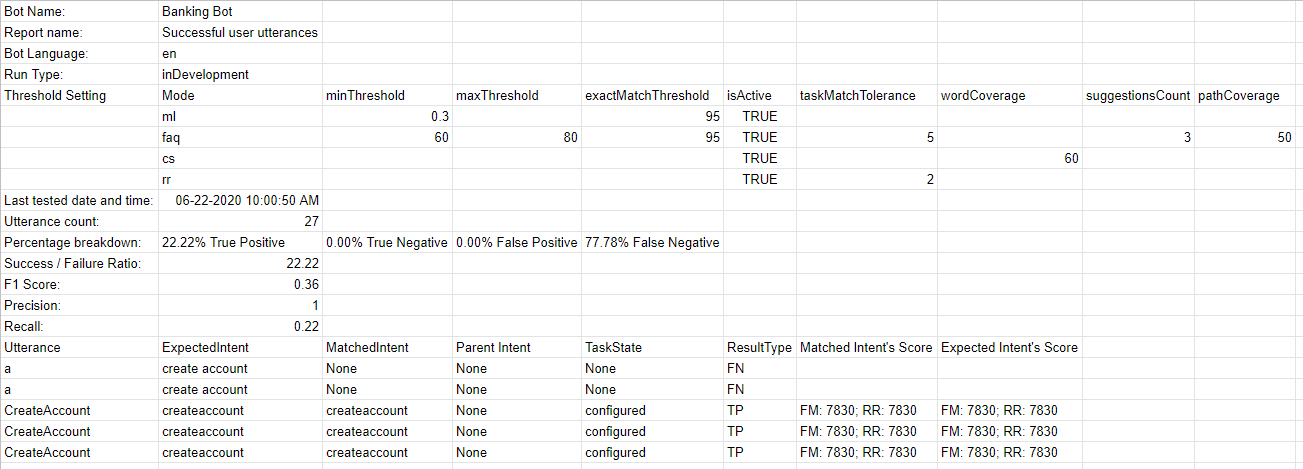
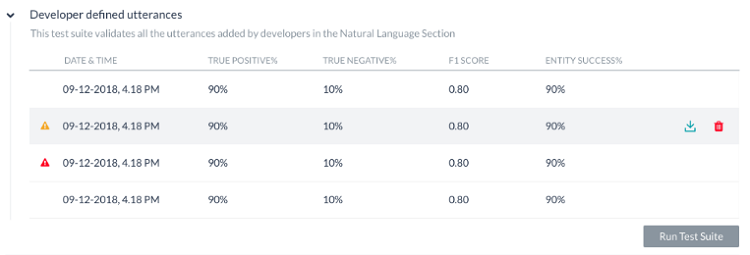
테스트는 아래에 설명된 대로 결과를 표시합니다. 각 테스트를 실행하면 테스트 보고서 기록이 생성되며 테스트 결과의 요약이 표시됩니다. 아래 스크린샷의 배치 테스트 결과에는 다음 정보가 포함됩니다.
- 마지막 실행 날짜 및 시간은 마지막으로 테스트를 실행한 날짜와 시간을 표시합니다.
- F1 점수는 정밀도와 재현율의 가중 평균입니다. 즉, (2*정밀도*재현율)/(정밀도+재현율).
- 정밀도는 올바르게 분류된 발화의 수를 기존 작업으로 (정확하게 또는 부정확하게) 분류한 발화의 수로 나눈 것입니다. 즉, 모든 분류된 긍정에 대한 참 긍정의 비율(참 긍정 및 긍정 오류의 합), TP/(TP+FP).
- 재현율은 올바르게 분류된 발화의 수를 기존 작업으로 올바르게 분류한 발화의 총수 또는 기존 작업의 부재로 부정확하게 분류한 발화의 총수로 나눈 것입니다. 즉, 실제 일치 의도/작업에 대한 올바르게 분류된 발화의 비율(참 긍정 및 긍정 오류의 합), TP/(TP+FN).
- 의도 성공률(%)은 테스트 결과 올바르게 인식한 의도의 비율을 표시합니다.
- 엔티티 성공률(%)은 테스트 결과 올바르게 인식한 엔티티의 비율을 표시합니다.
- 버전 유형은 테스트 스위트가 실행된 개발 또는 게시된 봇 버전을 식별합니다.
- 각 테스트 실행에서 가능한 세 가지 결과는 다음과 같습니다.
- 성공 – 파일에 있는 모든 레코드가 처리될 때
- 경고와 함께 성공 – 스위트에 있는 하나 이상의 레코드가 시스템 오류로 인해 탐지에서 삭제될 때
- 실패 – 시스템 오류가 발생하여 복구 후 재개할 수 없을 때.
경고/오류 아이콘 위에 마우스를 올리면 이유를 암시하는 메시지가 표시됩니다.

테스트 실행에 대한 자세한 분석을 얻으려면, 다운로드 아이콘을 클릭하여 CSV 형식의 테스트 보고서를 다운로드하세요. 필요한 경우 테스트 결과를 삭제할 수 있습니다. 보고서의 상단 섹션은 다음 필드가 있는 요약으로 구성됩니다.
- 봇 이름
- 테스트 스위트의 보고서 이름
- 봇 언어(7.3 릴리스 이후)
- 실행 유형은 테스트 스위트가 실행된 개발 또는 게시된 봇 버전을 식별합니다.
- 임계값 설정(7.3 릴리스 이후) 이 테스트 스위트를 실행할 때 적용된 NLP 임계값을 상세히 설명하며, 그다음에는 세 가지의 NL 엔진 각각에 대한 설정이 세부 정보와 함께 표시됩니다.
- Mode – ml, faq, 또는, cs
- minThreshold
- maxThreshold
- exactMatchThreshold
- isActive
- taskMatchTolerance
- wordCoverage
- suggestionsCount
- pathCoverage
- 마지막으로 테스트됨: 개발자가 정의한 발화에 대한 최신 테스트 실행 날짜입니다.
- 발화 수: 테스트 실행에 포함된 총발화 수입니다.
- 성공/실패 비율: 성공적으로 예측한 총발화 수를 총발화 수로 나눈 값에 100을 곱한 값입니다.
- 참 긍정(TP): 예상된 의도와 올바르게 일치하는 발화의 비율입니다. 스몰 토크의 경우, 예상된 의도와 실제 의도의 목록이 동일할 때일 것입니다. 특성의 경우, 예상되는 일치 이상으로 일치된 특성을 포함합니다.
- 참 부정(TN): 의도와 일치할 것으로 예상하지 않았고 일치하지 않은 발화의 비율입니다. 스몰 토크에는 적용되지 않습니다.
- 긍정 오류(FP): 예상하지 않은 의도와 일치하는 발화의 비율입니다. 스몰 토크의 경우, 예상된 의도와 실제 의도의 목록이 다를 때일 것입니다.
- 부정 오류(FN): 예상된 의도가 일치하지 않은 발화의 비율입니다. 스몰 토크의 경우, 예상되는 스몰토크 의도 항목이 비어 있지만 실제 스몰 토크가 의도에 매핑될 때입니다.
 또한, 보고서는 각 테스트 발화와 해당 결과에 대한 자세한 결과를 제공합니다.
또한, 보고서는 각 테스트 발화와 해당 결과에 대한 자세한 결과를 제공합니다.
- 발화 – 해당 테스트 스위트에서 사용된 발화입니다.
- 예상된 의도 – 주어진 발화에 대해 일치할 것으로 예상된 의도는 해당되는 경우 특성 접두사가 있는 특성을 포함합니다
- 일치된 의도 – 배치 테스트 중 발화에 대해 일치하는 의도입니다. 특성 접두사가 있는 일치하는 특성을 포함합니다(7.3 릴리스 이후). 일치하는 스몰 토크 의도를 포함합니다(8.0 릴리스 이후).
- 부모 의도 – 발화를 의도에 일치시키기 위해 고려되는 부모 의도입니다.
- 작업 상태 – 의도 또는 의도가 식별되는 작업의 상태입니다. 가능한 값에는 구성됨 또는 게시됨이 포함됩니다
- 결과 유형 – 참 긍정 또는 참 부정, 긍정 오류, 부정 오류로 분류된 결과
- 엔티티 이름 – 발화에서 감지된 엔티티의 이름입니다.
- 예상되는 엔티티 값 – 배치 테스트 중 결정될 것으로 예상되는 엔티티 값입니다.
- 일치하는 엔티티 값 – 발화에서 식별된 엔티티 값입니다.
- 엔티티 결과 – 예상되는 엔티티 값이 실제 엔티티 값과 동일한지 여부를 나타내기 위한 참 또는 긍정으로 분류된 결과입니다.
- 예상되는 엔티티 순서 – 입력 파일의 엔티티 값
- 실제 엔티티 순서 –
- 모든 예상되는 엔티티 순서가 제공된 경우, 동일하게 이 열에 포함됩니다
- 순서가 제공되지 않은 경우, 시스템이 결정한 순서로 열에 포함됩니다.
- 일부 엔티티의 순서가 제공된 경우, 사용자 정의 순서와 시스템이 정의한 순서의 조합이 포함됩니다
- 일치된 의도 점수 – 긍정 오류 및 부정 오류의 경우, FM, ML 및/또는 KG 엔진으로부터 발화에서 일치한 의도의 신뢰도 점수가 표시됩니다. 점수는 엔진이 의도를 감지한 경우에만 부여되므로 항상 세 엔진 모두에서 점수가 표시되지 않을 수 있습니다.
- 예상된 의도 점수 – 긍정 오류의 경우, 주어진 발화에 대해 일치할 것으로 예상된 의도의 신뢰도 점수가 부여됩니다. 이번에도 엔진은 의도를 감지하여 점수를 부여합니다.
팁: 배치 테스트의 경우, 봇이 올바른 의도를 인식할 수 없는 것으로 나타나면 발화를 기계 학습 모델에 추가하거나 수정하여 성능을 개선할 수 있습니다.
중요 사항:
- 봇 NLP 학습에 대한 최적의 접근 방법은 먼저 봇이 식별해야 하는 대부분의 사용 사례(사용자 발화)의 테스트 스위트를 만들고, 모델에 대해 실행하고 실패한 사례에 대한 학습을 시작하는 것입니다.
- 사용 빈도가 높은 발화를 대상으로 하는 배치 테스트 모듈을 생성/업데이트하세요.
- 상세 테스트를 거친 후에만 학습된 모델을 게시하세요.
- 의도 이름을 지정할 때, 이름은 비교적 짧게(3~5단어)하고 특수 문자나 불용어 단어 목록의 단어가 없도록 하세요. 의도 이름이 사용자 발화에서 사용자가 요청하는 내용과 비슷하도록 하세요.
- 배치 테스트 실행은 사용자의 컨텍스트를 고려하지 않습니다. 따라서, 컨텍스트를 고려할 때 실제 봇에서 참 긍정인 테스트 결과에서 부정 오류가 일부 확인될 수 있습니다.
Botを構築してトレーニングした後、最も重要な問題となるのはBotの学習モデルがどれだけ優れているかということです。したがって、Botのパフォーマンスを評価することは、Botがユーザーの発話をどの程度よく理解しているかを示すために重要です。
バッチテスト機能は、Botが特定の発話セットから期待されるインテントとエンティティを正しく認識する能力を見極めるのに役立ちます。これには、一連のテストを実行して詳細な統計分析を行い、Botの機械学習モデルのパフォーマンスを測定することが含まれます。
バッチテストを実行するには、ビルダーで使用可能な事前定義されたテストスイートを使用するか、独自のカスタムテストスイートを作成します。要件に基づいてテストスイートを実行して、目的の結果を表示することができます。こちらは、左側のナビゲーションメニューよりテスト -> バッチテストオプションからアクセスできます。
テストスイートの管理
Kore.aiは、バッチテストを実行するためにすぐに使用できるテストスイートをいくつか用意しています。開発者が定義した発話および成功したユーザーの発話は、バッチテストを実行できる組み込みのテストスイートです。また、発話のカスタムセットをテストするための新しいテストスイートを作成することもできます。
開発者が定義した発話
このテストスイートは、機械学習の発話画面から、開発者が以前に追加およびトレーニングした発話を検証します。このテストスイートを使用するということは、開発者がBotのすべてのタスクに対して追加した発話セット全体をまとめてテストすることを意味します。
成功したユーザーの発話
このテストスイートには、インテントに正常に一致し、対応するタスクが完全に実行されたすべてのエンドユーザーの発話が含まれています。これらの発話は、分析モジュールの「検出されたインテントI」セクションからも見つけることができます。
新しいテストスイートの追加
新しいテストスイートを使用することで、バッチファイル(データセットとも呼ばれる)に、テスト発話の配列を一度にまとめてインポートできます。データセットファイルはCSVまたはJSON形式で記述する必要があり、最大10,000の発話を含めることができます。新しいテストスイートオプションを使用して、テストスイート作成の一部としてサンプルのCSVまたはJSONファイル形式をダウンロードできます。
テストスイートのJSON形式
カスタムスイートを作成するためのJSON形式を使用すると、テストケースの配列を定義することができます。各テストケースは、テスト対象の発話、テスト対象の発話に対するインテントから構成され、オプションで発話から決定する予定のエンティティのリストを定義します。期待されるインテントが子のインテントである場合は、検討される親のインテントを含めることもできます。
- マルチアイテムが有効になっているエンティティの場合、値は次のように指定する必要があります。
entity1||entity2 - 複合エンティティでは、次の形式で値を指定する必要があります。
component1name:entityValue|component2name:entityValue2
- エンティティが抽出されるオーダーは次のように指定できます。
"entityOrder":["TransferAmount", "PayeeName"]オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。
| プロパティ名 | タイプ | 説明 |
|---|---|---|
| テストケース | 配列 |
以下から構成されます。
|
| 入力 | 文字列 | エンドユーザーの発話 |
| インテント | 文字列 |
エンドユーザーの発話の目的を決定します(FAQテストケースの場合はタスク名や主要な質問にすることもできます) 7.3以降のリリースでは、このプロパティを使用して、trait(特性)の接頭辞を使うことにより、この発話に対して特定される特性を定義できます。例)特性:特性名1 || 特性名2 || 特性名3 8.0以降のリリースでは、このプロパティには予想されるスモールトークパターンを含めることができます。 |
| parentIntent | 文字列[オプション] | インテントがサブインテントである場合に検討される親インテントを定義します。 スモールトークの場合、スモールトークが状況に応じたフォローアップを目的としているときにこのフィールドに入力する必要があります。マルチレベルの文脈上のインテントの場合、親インテントは || を使った区切り文字で区切る必要があります。 |
| エンティティ | 配列[オプション] |
入力文から決定されるエンティティの配列で構成されます。
|
| entityValue | 文字列 | 発話から決定されると予想されるエンティティの値です。期待されるエンティティ値を文字列として定義するか、正規表現を使用できます。バッチテストの目的のために、プラットフォームはすべてのエンティティ値を文字列形式にフラット化します。詳細については、エンティティ形式の変換を参照してください。 |
| entityName | 文字列 | 発話から決定されると予想されるエンティティの名前です。 |
|
entityOrder (バージョン7.1以降) |
配列[オプション] |
エンティティが抽出されるオーダーを指定するエンティティ名の配列です。 オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。 |
テストスイートのCSV形式
カスタムスイートを作成するためのCSV形式では、テストケースをCSVファイルのレコードとして定義することができます。各テストケースは、テスト対象の発話、テスト対象の発話に対するインテントから構成され、オプションで発話から決定するエンティティを定義します。テストケースで文から複数のエンティティを検出する必要がある場合は、検出される追加のエンティティごとに追加の行を含める必要があります。期待されるインテントが子のインテントである場合は、検討される親のインテントを含めることもできます。
- マルチアイテムが有効になっているエンティティの場合、値は次のように指定する必要があります。
entity1||entity2 - 複合エンティティでは、次の形式で値を指定する必要があります。
component1name:entityValue|component2name:entityValue2 - エンティティ値の抽出オーダーは、次の形式で記述できます。
entity3>entity4>entity1オーダーが提供されていないか、部分的に提供されている場合、プラットフォームはすべてのエンティティをカバーする最短ルートをデフォルトのオーダーとして決定します。
| 列名 | タイプ | 説明 |
|---|---|---|
| 入力 | 文字列 | エンドユーザーからの発話 |
| インテント | 文字列 |
エンドユーザーの発話の目的を決定します(FAQテストケースの場合はタスク名や主要な質問にすることもできます) 7.3以降のリリースでは、このプロパティを使用して、trait(特性)の接頭辞を使うことにより、この発話に対して特定される特性を定義できます。例)特性:特性名1 || 特性名2 || 特性名3 8.0以降のリリースでは、このプロパティには予想されるスモールトークパターンを含めることができます。 |
| parentIntent | 文字列[オプション] | インテントがサブインテント である場合に検討される親インテントを定義します。スモールトークの場合、このフィールドはスモールトークが文脈上のフォローアップインテントであり、フォローアップインテントの基準が満たされていると仮定してインテントが一致する場合にフィールドに入力する必要があります。マルチレベルの文脈上のインテントの場合、親インテントは区切り文字 || で区切る必要があります。 |
| entityValue | 文字列[オプション] | 発話から決定されると予想されるエンティティの値です。期待されるエンティティ値を文字列として定義するか、正規表現を使用できます。バッチテストの目的のために、プラットフォームはすべてのエンティティ値を文字列形式にフラット化します。詳細については、エンティティ形式の変換を参照してください。 |
| entityName | 文字列[オプション] | 発話から決定されると予想されるエンティティの名前です。 |
|
entityOrder (バージョン7.1以降) |
配列[オプション] |
エンティティを抽出する順番を > で区切ったエンティティ名の配列です。 オーダーが選ばれていないか部分的に選ばれている場合、プラットフォームは暗黙のオーダーを定義して、最初にNERエンティティとパターンエンティティを処理し、次に残りのエンティティを処理します。 |
エンティティ形式の変換
| エンティティタイプ | サンプルエンティティValueType | フラット形式の値 | キーのオーダー |
|---|---|---|---|
| アドレス | P.O.Box 3700 Eureka, CA 95502 | P.O.Box 3700 Eureka, CA 95502 | |
| 空港 | { "IATA": "IAD", "AirportName": "Washington Dulles International Airport", "City": "Washington D.C.", "CityLocal": "Washington", "ICAO": "KIAD", "Latitude": "38.94", "Longitude": "-77.46" } | ワシントン・ダレス国際空港 IAD KIAD 38.94 -77.46 ワシントンD.C. ワシントン | 空港名 IATA ICAO 緯度 経度 市 市地域 |
| 市内 | ワシントン | ワシントン | |
| 国 | { "alpha3": "IND", "alpha2": "IN", "localName": "India", "shortName": "India", "numericalCode": 356} | IN IND 356 インド インド | alpha2 alpha3 数値コード 地域名称 略称 |
| 会社名・組織名 | Kore.ai | Kore.ai | |
| カラー | 青 | 青 | |
| 通貨 | [{ "code": "USD", "amount": 10 }] | 10 USD | 金額コード |
| 日付 | 2018年10月25日 | 2018年10月25日 | |
| 日付期間 | { "fromDate": "2018-11-01", "toDate": "2018-11-30" } | 2018-11-01 2018-11-30 | fromDate toDate |
| 日時 | 2018-10-24T13:03:03+05:30 | 2018-10-24T13:03:03+05:30 | |
| 説明 | サンプル説明 | サンプル説明 | |
| メール | user1@emaildomain.com | user1@emaildomain.com | |
| 項目リスト(列挙) | Apple | Apple | |
| アイテム一覧(検索) | Apple | Apple | |
| 場所 | { "formatted_address": "8529 Southpark Cir #100, Orlando, FL 32819, USA", "lat": 28.439148,"lng": -81.423733 } | 8529 Southpark Cir #100, Orlando, FL 32819, USA 28.439148 -81.423733 | formatted_address lat lng |
| 数 | 100 | 100 | |
| 氏名 | ピーターパン | ピーターパン | |
| 割合 | 0.25 | 0.25 | |
| 電話番号 | +914042528888 | +914042528888 | |
| 量 | { "unit": "meter", "amount": 16093.4, "type": "length", "source": "10 miles" } | 16093.4 メーター 距離 10マイル | 合計 ユニット タイプ ソース |
| 文字列 | サンプル文字列 | サンプル文字列 | |
| 時間 | T13:15:55+05:30 | T13:15:55+05:30 | |
| タイムゾーン | -04:00 | -04:00 | |
| URL | https://kore.ai | https://kore.ai | |
| 郵便番号 | 32819 | 32819 |
データセットファイルのインポート
- バッチテストページの新しいテストスイートをクリックします。データセットをインポートするためのダイアログボックスが表示されます。
- 名前、説明を入力し、データセットファイルのそれぞれのボックスにデータセットタイプの選択を入力します。
- データセットファイルをインポートするには、ファイルを選択をクリックします。選択したデータセットタイプに従って、発話を含むJSONまたはCSVファイルを探して選択します。
- 作成をクリックします。データセットファイルは、バッチテストページでテストスイートを実行するためのオプションとして表示されます。
テストスイートの実行
次の手順では、Botでバッチテストを実行し、テスト結果に基づいて発話に関する詳細な分析レポートを取得する方法について説明します。 開始するには、ビルダーのテストセクションでバッチテストをクリックします。
注意: テストを行う前に、機械学習を使用し、相当数の発話でBotを追加してトレーニングすることが不可欠です。
たとえば、開発者が定義した発話などのテストスイートを実行するには、開発者が定義した発話に続くテストスイートを実行をクリックします。 これにより、開発者が定義した発話のバッチテストが開始されます。 バージョン7.3のリリース後では、開発中または公開済みバージョンのBotのテストスイートを実行できます。
テストでは、以下に説明するような結果が表示されます。 テストを実行するたびに、テストレポートの記録が作成されテスト結果の概要が表示されます。 以下のスクリーンショットのバッチテスト結果には、次の情報が含まれています。
- 最終実行日時では、最新のテスト実行の日付と時刻が表示されます。
- F1スコアは、精度と再現率の加重平均です。
- 精度は、正しく分類された発話の数を、既存のタスクに(正しくまたは誤って)分類された発話の総数で割ったものです。つまり、すべての分類された陽性に対する真陽性の比率(真陽性と偽陽性の合計)となります。
- 再現率は、正しく分類された発話の数を、既存のタスクに正しく分類された、または既存のタスクがない場合に誤って分類された発話の総数で割ったものです。つまり、実際に一致したインテントやタスクに対して正しく分類された発言の比率(真陽性と偽陰性の合計)です。
- インテント成功%は、テストの結果として得られた正しいインテントの認識割合を表示します。
- エンティティ成功%は、テストの結果として得られた正しいエンティティの認識割合を表示します。
- バージョンタイプは、テストスイートが実行されたBotのバージョン(開発版または公開済み)を特定します。
- 各テスト実行から考えられる結果は3つあります。
- 成功-ファイル内に存在するすべてのレコードが処理された場合です
- 警告付きの成功-システムエラーのためにスイート内に存在する1つ以上のレコードが検出から破棄された場合です
- 失敗-システムエラーが発生し、リカバリー後にテストを再開できなかった場合です
警告/エラーアイコンの上にカーソルを合わせると、その理由を示すメッセージが表示されます。
テスト実行の詳細な分析を取得するには、ダウンロードアイコンををクリックして、テストレポートをCSV形式でダウンロードします。 必要に応じて、テスト結果を削除するオプションがあります。レポートの上部のセクションには、次のフィールドを含む要約が含まれています。
- Bot名
- テストスイートのレポート名
- Bot言語(7.3以降のリリース)
- 実行タイプは、テストスイートが実行されたBotのバージョン(開発版または公開済み)を特定します。
- しきい値設定(7.3以降のリリース)は、このテストスイートの実行時に適用されるNLPのしきい値の詳細を示し、3つのNLエンジンのそれぞれの設定に続いて以下の詳細を示します。
- モード-ml、faq、cs
- minThreshold
- maxThreshold
- exactMatchThreshold
- isActive
- taskMatchTolerance
- wordCoverage
- suggestionsCount
- pathCoverage
- 最終テスト: 開発者が定義した発話の最新のテスト実行日です。
- 発話数: テスト実行に含まれる発話の総数です。
- 成功/失敗率: 正常に予測された発話の総数を、発話の総数で割った値に100を掛けたものです。
- 真陽性(TP): 予想されるインテントに正しく一致した発話の割合です。
スモールトークの場合は、期待されるインテントと実際のインテントのリストが同じである場合です。
特性の場合、これには予想される一致に加えて一致する特性が含まれます。 - 真陰性(TN): どのインテントとも一致することが期待されておらず、一致しなかった発話の割合です。 スモールトークには適用されません。
- 偽陽性(FP): 予想しないインテントに一致した発話の割合です。スモールトークの場合、予想されるインテントと実際のインテントのリストが異なる場合があります。
- 偽陰性(FN): 予想されるインテントと一致しない発話の割合です。 スモールトークの場合、予想されるスモールトークのインテントのリストが空白で、実際のスモールトークがインテントにマッピングされている場合です。
このレポートには、各テスト発話とそれに対応する結果に関する詳細情報も含まれています。
- 発話-対応するテストスイートで使用される発話です。
- 予想されるインテント-特定の発話に一致すると予想されるインテントであり、該当する場合は特性プレフィックスが付いた特性が含まれます。
- 一致したインテント-バッチテスト中に発話に一致したインテントです。 これには、特性プレフィックスが付いた一致した特性が含まれます(7.3以降のリリース)。 これには、一致したスモールトークのインテントが含まれます(8.0以降のリリース)。
- 親インテント-発話をインテントと照合するために検討される親のインテントです。
- タスク状態-インテントが特定されているインテントやタスクの状態です。使用可能な値には、設定済みまたは公開済みがあります。
- 結果タイプ-真陽性または真陰性または偽陽性または偽陰性に分類される結果です。
- エンティティ名-発話から検出されたエンティティの名前です。
- 予想されるEntityValue-バッチテスト中に決定されると予想されるエンティティ値です。
- 一致したEntityValue-発話から特定されたエンティティ値です。
- エンティティの結果-期待されるエンティティ値が実際のエンティティ値と同じであるかどうかを示すために、真または偽に分類される結果です。
- 予想されるエンティティのオーダー-入力ファイルからのエンティティ値です。
- 実際のエンティティのオーダー –
- 予想されるすべてのエンティティのオーダーが指定されている場合、同じオーダーがこの列に含まれます。
- オーダーが用意されていない場合、システムが決定したオーダーが列に含まれます。
- 一部のエンティティに対してオーダーが与えられている場合、ユーザー定義のオーダーとシステム定義のオーダーの組み合わせが含まれます。
- 一致したインテントのスコア -偽陽性と偽陰性の場合、FM、機械学習、ナレッジグラフエンジンからの信頼スコアが、発話からの一致したインテントに対して表示されます。 エンジンがインテントを検出した場合にのみスコアが付与されることに注意してください。つまり、3つのエンジンすべてのスコアが常に表示されるとは限りません。
- 予想されるインテントのスコア-偽陽性の場合、特定の発話に一致すると予想されるインテントの信頼スコアが示されます。 この場合も、インテントを検出するエンジンによってスコアが与えられます。
ヒント: いずれのバッチテストでも、Botが正しいインテントを認識できないことが結果で示された場合は、機械学習モデルに発話を追加または変更することで、パフォーマンスを向上させることができます。
重要な注意事項::
- Bot NLPトレーニングへの最適なアプローチは、最初にBotが特定する必要のあるほとんどのユースケース(ユーザーの発話)のテストスイートを作成し、それをモデルに対して実行して、失敗したものについてトレーニングを開始することです。
- 使用頻度の高い発話のためのバッチテストモジュールを作成・更新します。
- 詳細なテストを行った後でのみ、トレーニング済みモデルを公開します。
- インテントに名前を付けるときは、名前が比較的短く(3~5語)、特殊文字やストップワードリストの単語が含まれていないことを確認してください。 インテント名が、ユーザーが発話で要求する名前に近いことを確認してください。
- バッチテストの実行ではユーザーのコンテキストは検討されません。 したがって、コンテキストを検討した場合、実際のBotでは真陽性であるのに、テスト結果ではいくつかの偽陰性が表示される場合があります。
Once you have built and trained your bot, the most important question that arises is how good is your bot’s learning model? So, evaluating your bot’s performance is important to delineate how well your bot understands the user utterances.
The Batch Testing feature helps you discern the ability of your bot to correctly recognize the expected intents and entities from a given set of utterances. This involves the execution of a series of tests to get a detailed statistical analysis and gauge the performance of your bot’s ML model.
To conduct a batch test, you can use predefined test suites available in the builder or create your own custom test suites. Based on your requirement, the test suites can be run to view the desired results. This option can be accessed under the Build tab from the Testing -> Batch Testing option from the left menu.
Managing Test Suites
Kore.ai provides a few out-of-the-box Test Suites to perform batch testing. ‘Developer defined utterances’ and ‘Successful user utterances’ are the built-in test suites that can be run to perform Batch Testing. You can also create a New Test Suite for testing a custom set of utterances.
Developer defined utterances
This test suite validates the utterances that have been previously added and trained by the developer from the Machine Learning Utterances screen. Using this test suite would mean testing collectively the entire set of utterances that a developer has added for all tasks of the bot.
Successful user utterances
This test suite includes all the end-user utterances that have successfully matched an intent and the corresponding task is fully executed. You can also find these utterances from the ‘Intent found’ section of the Analyze module.
Adding a New Test Suite
The New Test Suite enables you to import an array of test utterances collectively at once in a batch file, also known as a Dataset. The Dataset file needs to be written in CSV or JSON format and can have a maximum of 10000 utterances. You can download the sample CSV or JSON file formats as part of the test suite creation using the New Test Suite option.
JSON Format for Test Suite
The JSON format for creating custom suites allows you to define an array of test cases where each test case should consist of an utterance to be tested, the intent against which the utterance to be tested, and optionally define the list of expected entities to be determined from the utterance. If expected intent is a child intent, then you can also include the parent intent to be considered.
- For Entities that have the Multi-Item enabled, values need to be given as:
entity1||entity2 - Composite Entities require the values in the following format:
component1name:entityValue|component2name:entityValue2
- The order in which the entities are to be extracted can be given as:
"entityOrder":["TransferAmount", "PayeeName"]. If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order.
| Property Name | Type | Description |
|---|---|---|
| Test Cases | Array | Consists of the following:
|
| input | String | End-user Utterance. Note Batch Test upload if any of the utterances in the batch test are beyond 3000 characters |
| intent | String | Determine the objective of an end-user utterance (can be task name or primary question in case of FAQ test case)
This property can also be used to define traits to be identified against this utterance by using the prefix “trait” for example, Trait: Trait Name1|| Trait Name2||Trait Name3 This property can include the expected Small Talk pattern. |
| parentIntent | String [Optional] | Define parent intent to be considered if the intent is a sub-intent. In the case of Small Talk, this field should be populated when the Small Talk is contextual follow-up intent; in the case of multi-level contextual intent the parent intents should be separated by the delimiter || |
| entities | Array [Optional] | Consists of an array of entities to be determined from the input sentence:
|
| entityValue | String | Value of the entity expected to be determined from the utterance. You can define the expected Entity Value as a string or use a Regular Expression. For the purpose of Batch Testing, the platform flattens all entity values into string formats. Refer Entity Format Conversions for more information. |
| entityName | String | Name of the entity expected to be determined from the utterance |
| entityOrder | Array [Optional] | An array of entity names specifying the order in which the entities are to be extracted.
If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order. |
CSV Format for Test Suite
CSV format for creating custom suites allows you to define test cases as records in CSV file where each test case should consist of an utterance to be tested, the intent against which the utterance to be tested, and optionally define entities to be determined from the utterance. If your test case requires more than one entity to detected from a sentence, then you have to include an extra row for each of the additional entities to be detected. If expected intent is a child intent, then you can also include the parent intent to be considered.
- For Entities that have the Multi-Item enabled values need to be given as:
entity1||entity2 - Composite Entities require the values in the following format:
component1name:entityValue|component2name:entityValue2 - The order of extraction of entity value can be mentioned in the following format:
entity3>entity4>entity1. If the order is not provided or partially provided, the platform determines the shortest route covering all the entities as the default order.
| Column Name | Type | Description |
|---|---|---|
| input | String | Utterance given by the end-user. Note that the Batch Test upload will fail if any of the utterances in the batch test are beyond 3000 characters |
| intent | String | Determine the objective of an end-user utterance (can be task name or primary question in case of FAQ test case)
This property can also be used to define traits to be identified against this utterance by using the prefix “trait” for example, Trait: Trait Name1|| Trait Name2||Trait Name3 This property can include the expected Small Talk pattern. |
| parentIntent | String [Optional] | Define parent intent to be considered if the intent is a sub-intent In the case of Small Talk, this field should be populated when the Small Talk is contextual follow-up intent and the intent would be matched assuming that the follow-up intent criteria is met; in the case of multi-level contextual intent the parent intents should be separated by the delimiter || |
| entityValue | String [Optional] | Value of the entity expected to be determined from the utterance. You can define the expected Entity Value as a string or use a Regular Expression. For the purpose of Batch Testing, the platform flattens all entity values into string formats. Refer Entity Format Conversions for more information. |
| entityName | String [Optional] | Name of the entity expected to be determined from the utterance |
| entityOrder | Array [Optional] | An array of entity names separated by > specifying the order in which the entities are to be extracted.
If the order is not provided or partially provided, the platform defines the implicit order to process first the NER and pattern entities and then the remaining entities. |
Entity Format Conversions
| Entity Type | Sample Entity ValueType | Value in Flat Format | Order of Keys |
|---|---|---|---|
| Address | P.O. Box 3700 Eureka, CA 95502 | P.O. Box 3700 Eureka, CA 95502 | |
| Airport | { “IATA”: “IAD”, “AirportName”: “Washington Dulles International Airport”, “City”: “Washington D.C.”, “CityLocal”: “Washington”, “ICAO”: “KIAD”, “Latitude”: “38.94”, “Longitude”: “-77.46” } | Washington Dulles International Airport IAD KIAD 38.94 -77.46 Washington D.C. Washington | AirportName IATA ICAO Latitude Longitude City CityLocal |
| City | Washington | Washington | |
| Country | { “alpha3”: “IND”, “alpha2”: “IN”, “localName”: “India”, “shortName”: “India”, “numericalCode”: 356} | IN IND 356 India India | alpha2 alpha3 numericalCode localName shortName |
| Company or Organization Name | Kore.ai | Kore.ai | |
| Color | Blue | Blue | |
| Currency | [{ “code”: “USD”, “amount”: 10 }] | 10 USD | amount code |
| Date | 2018-10-25 | 2018-10-25 | |
| Date Period | { “fromDate”: “2018-11-01”, “toDate”: “2018-11-30” } | 2018-11-01 2018-11-30 | fromDate toDate |
| Date Time | 2018-10-24T13:03:03+05:30 | 2018-10-24T13:03:03+05:30 | |
| Description | Sample Description | Sample Description | |
| user1@emaildomain.com | user1@emaildomain.com | ||
| List of Items(Enumerated) | Apple | Apple | |
| List of Items(Lookup) | Apple | Apple | |
| Location | { “formatted_address”: “8529 Southpark Cir #100, Orlando, FL 32819, USA”, “lat”: 28.439148,”lng”: -81.423733 } | 8529 Southpark Cir #100, Orlando, FL 32819, USA 28.439148 -81.423733 | formatted_address lat lng |
| Number | 100 | 100 | |
| Person Name | Peter Pan | Peter Pan | |
| Percentage | 0.25 | 0.25 | |
| Phone Number | +914042528888 | +914042528888 | |
| Quantity | { “unit”: “meter”, “amount”: 16093.4, “type”: “length”, “source”: “10 miles” } | 16093.4 meter length 10 miles | amount unit type source |
| String | Sample String | Sample String | |
| Time | T13:15:55+05:30 | T13:15:55+05:30 | |
| Time Zone | -04:00 | -04:00 | |
| URL | https://kore.ai | https://kore.ai | |
| Zip Code | 32819 | 32819 |
Importing a Dataset file
- Click New Test Suite on the batch testing page. A dialog box to import the dataset appears.
- Enter a Name, Description, and choose a Dataset Type in the respective boxes for your dataset file.
- To import the Dataset file, click Choose File to locate and select a JSON or CSV file containing the utterances as per the Dataset Type selected.
- Click Create. The dataset file will appear as an option to run the test suite on the batch testing page:
Running Test Suites
The following steps will guide you on how to run a batch test on your bot and obtain a detailed analytical report on the utterances based on the test results. To get started, click Batch Testing in the Testing section on the builder.
Note: Prior to testing, it is essential to add and train your bot with a considerable number of utterances using Machine Learning.
To run a Test Suite, for example, the Developer Defined utterances, click Developer Defined Utterances followed by Run Test Suite. This will initiate the batch test for Developer defined utterances. You can run the test suite against the in-development or published version of the bot.
The test will display the results as explained below. Each test run will create a test report record and displays a summary of the test result. The batch test result in the screenshot below includes the following information:
- Last Run Date & Time that displays the date and time of the latest test run.
- F1 Score is the weighted average of Precision and Recall i.e. (2*precision*recall)/(precision+recall).
- Precision is the number of correctly classified utterances divided by the total number of utterances that got classified (correctly or incorrectly) to an existing task ie the ratio of true positives to all classified positives (sum of true and false positives) i.e. TP/(TP+FP).
- Recall is the number of correctly classified utterances divided by the total number of utterances that got classified correctly to any existing task or classified incorrectly as an absence of an existing task ie the ratio of correctly classified utterances to actual matching intents/tasks (sum of true positives and false negatives) i.e. TP/(TP+FN).
- Intent Success % that displays the percentage of correct intent recognition that has resulted from the test.
- Entity Success % that displays the percentage of correct entity recognition that has resulted from the test.
- Version Type identifies the version of the bot against which the test suite was run – development or published.
- There are three possible outcomes from each test run:
- Success – when all records are present in the file are processed
- Success with a warning – when one or more records present in the suite are discarded from detection due to system error
- Failed – when there was a system error and the test could not be resumed post-recovery.
Hovering over the warning/error icon will display a message suggesting the reason.
To get a detailed analysis of the test run, click the Download icon to download the test report in CSV format. You have an option to delete the test results if needed. The top section of the report comprises the summary with the following fields:
- Bot Name
- Report name of the test suite
- Bot Language (post 7.3 release)
- Run Type identifies the version of the bot against which the test suite was run – development or published.
- Threshold Setting (post 7.3 release) detailing the NLP thresholds applied when running this test suite, this would be followed by the settings for each of the three NL engines with the following details:
- Mode – ml, faq, or, cs
- minThreshold
- maxThreshold
- exactMatchThreshold
- isActive
- taskMatchTolerance
- wordCoverage
- suggestionsCount
- pathCoverage
- Last Tested: Date of the latest test run for developer-defined utterances.
- Utterance Count: Total number of utterances included in the test run.
- Success/Failure Ratio: Total number of successfully predicted utterances divided by the total count of utterances multiplied by 100.
- True Positive (TP): Percentage of utterances that have correctly matched expected intent.
In the case of Small Talk, it would be when the list of expected and actual intents are the same.
In the case of Traits, this would include the traits matched over and above the expected matches. - True Negative (TN): Percentage of utterances that were not expected to match any intent and they did not match. Not applicable to Small Talk.
- False Positive (FP): Percentage of utterances that have matched an unexpected intent. In the case of Small Talk, it would be when the list of expected and actual intents are different.
- False Negative (FN): Percentage of utterances that have not matched expected intent. In the case of Small Talk, it would be when the list of expected Small Talk intent is blank and but the actual Small Talk is mapped to an intent.
The report also provides detailed information on each of the test utterances and the corresponding results.
- Utterances – Utterances used in the corresponding test suite.
- Expected Intent – The intent expected to match for a given utterance, will include trait where applicable with trait prefix
- Matched Intent – The intent that is matched for an utterance during the batch test. This will include matched traits with trait prefix (post 7.3 release). This will include matched Small Talk intents (post 8.0 release).
- Parent Intent – The parent intent considered for matching an utterance against an intent.
- Task State – The status of the intent or task against which the intent is identified. Possible values include Configured or Published
- Result Type – Result categorized as True Positive or True Negative or False Positive or False Negative
- Entity Name – The name of the entity detected from the utterance.
- Expected EntityValue – The entity value expected to be determined during the batch test.
- Matched EntityValue – The entity value identified from an utterance.
- Entity Result – Result categorized as True or False to indicate whether the expected entity value is the same as the actual entity value.
- Expected Entity Order – entity values from the input file
- Actual Entity Order –
- if the order for all expected entities is provided, then the same is included in this column
- if no order is provided, the system determined order will be included in the column
- If an order is provided for some entities, then a combination of user-defined order and system-defined order will be included
- Matched Intent’s Score – For False Positives and False Negatives, the confidence scores from FM, ML, and/or KG engines are displayed for the matched intent from the utterance. Note that the scores are given only if the engine detects the intent, which means that you may not see the scores from all three engines at all times.
- Expected Intent’s Score – For False Positives, the confidence scores for the intent expected to match for the given utterance is given. Again the score will be given by the engines detecting the intent.
Tip: For any of the batch tests, if results indicate that your bot is unable to recognize the correct intents, you can work on improving its performance by adding or modifying utterances to the Machine Learning model.
Important Notes:
- An optimal approach to bot NLP training is to first create a test suite of most of the use cases(user utterances) that the bot needs to identify, run it against the model and start training for the ones that failed.
- Create/update batch testing modules for high usage utterances.
- Publish the trained model only after detailed testing.
- When naming the intent, ensure that the name is relatively short (3-5 words) and does not have special characters or words from the Stop Wordlist. Try to ensure the intent name is close to what the users request in their utterance.
- Batch Test executions do not consider the context of the user. Hence you might see some False Negatives in the test results which in fact are True Positives in the actual bot when the context is taken into consideration.