자연스러운 대화에서, 사용자가 특정 시나리오를 설명하면서 배경/관련 정보를 제공하는 일은 매우 흔합니다. 특성은 사용자가 대화에서 표현하는 특정 엔티티, 속성 또는 세부 정보입니다. 발화는 특정 의도를 직접 전달하지 않을 수 있지만, 발화에 있는 특성은 의도 탐지 및 봇 대화 흐름을 구동하는 데 사용됩니다. 예를 들어 출장 중인데 제 카드의 결제가 거부되었습니다라는 발화는 두 가지 특성 카드 결제 거부와 비상 사태를 나타냅니다. 이 시나리오에서, 발화는 직접적인 의도를 전달하지 않거나 기껏해야 카드 차단 해제 흐름을 트리거하는 데 사용됩니다. 그러나, 긴급 특성은 대화를 인간 상담사에게 직접 할당하는 데 사용됩니다. 봇 플랫폼의 특성 기능은 사용자 발화에 존재하는 이러한 특성을 식별하는 것을 목표로 하며 의도 탐지를 위해 특성 기능을 사용하고 이러한 특성으로 봇 정의를 사용자 정의합니다.
사용 사례
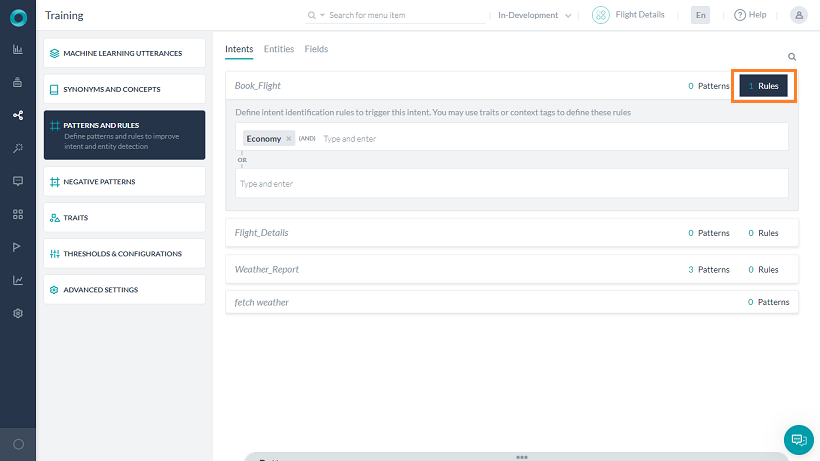
항공편 예약 봇에는 선호 비용에 따라 항공편을 예약하기 위한 추가 요구 사항이 있을 수 있습니다. 사용자 발화: 런던행 저가 옵션을 찾고 있습니다의 경우 유효한 항공편을 주문하고 가장 저렴한 티켓을 선택해야 합니다. 다음을 통해 이를 달성할 수 있습니다.
- 저가라는 발화로 학습시킨 특성 이코노미가 있는 여행 클래스라는 특성 유형을 추가합니다.
- 이코노미 특성이 있는 경우 항공편 예약에 규칙 추가가 트리거됩니다.
- 컨텍스트에 특성 이코노미가 있는 경우 전환 조건을 추가합니다.
구성
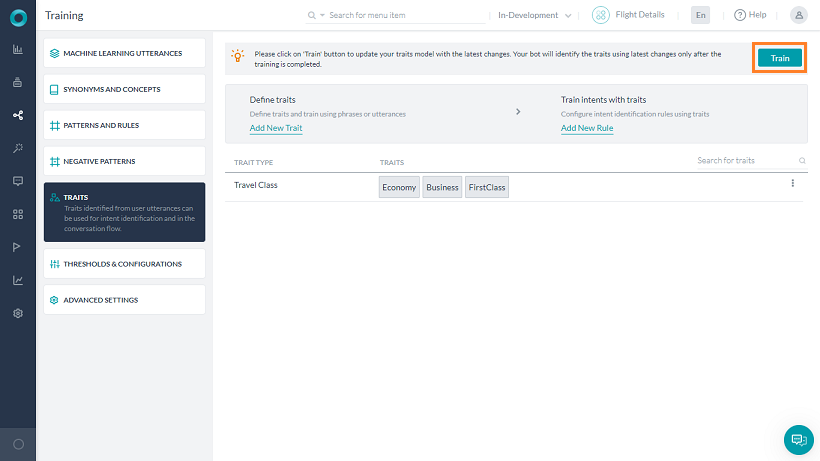
특성 설정에는 다음이 포함됩니다.
- 특성 정의
- 특성 연관 규칙
- 특성 탐지
특성 정의
특성을 정의하려면 빌드 상단 메뉴의 왼쪽 메뉴에서 자연어 –> 학습을 클릭하고 특성 탭을 선택합니다.  다음은 특성을 정의할 때 고려해야 할 주요 기능입니다.
다음은 특성을 정의할 때 고려해야 할 주요 기능입니다.
- 특성 유형은 위의 예의 여행 클래스 같은 관련 특성 모음입니다.
- 특성 유형은 ML 기반 또는 패턴 기반일 수 있습니다. 특성 유형의 각 특성은 유형에 따라 단어, 문구, 발화 또는 패턴을 사용하여 학습시킬 수 있습니다. 특성 유형 관리를 통해 학습 설정을 정의할 수 있습니다. ML 기반 특성 구성은 아래를 참조하세요.

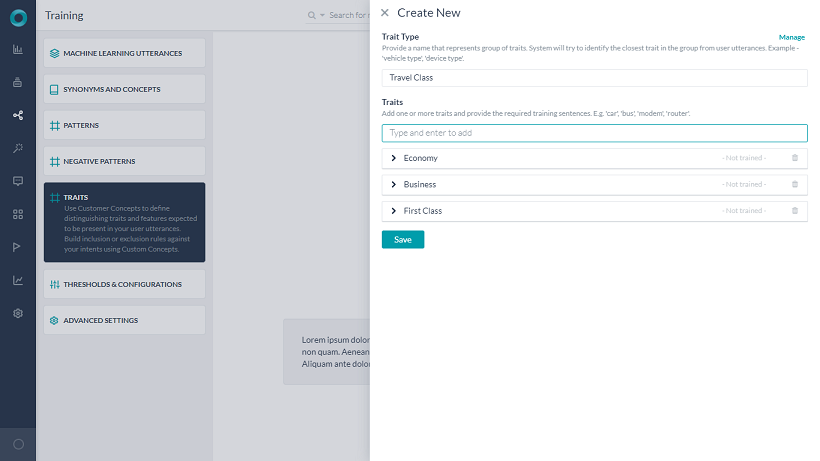
- 특성 유형은 하나 이상의 특성을 가질 수 있습니다.

- 특성 이름은 그룹 내에서 하나뿐인 것이어야 합니다. 그러나 여러 그룹에 같은 이름을 가진 특성이 존재할 수 있습니다.
- ML 기반 특성의 경우, 특성을 식별하는 단어, 문구 또는 발화를 정의할 수 있습니다. ML 기반 특성 유형에 특성 유형당 하나의 특성을 탐지합니다.
- 패턴 기반 특성의 경우, 주어진 특성과 연관된 패턴을 정의할 수 있습니다. 패턴 기반 특성 유형에 여러 특성이 탐지될 가능성이 있습니다. 특성 유형 내의 특성 순서 지정은 특성 유형에서 특성의 중요성을 나타내며 하나의 특성만 감지합니다.
- 추가되고 나면, 사용자 발화에서 특성을 탐지하도록 봇을 학습시킵니다.

참고 사항:
- 다국어 봇의 경우 언어별 특성을 추가할 수 있습니다.
- 특성 이름을 수정하고 나면 해당 특성으로 정의된 모든 규칙이 수정되었는지 확인하세요. 수동으로 작업해야 하며 플랫폼에서 자동 처리하지 않습니다.
- 특성 이름은 그룹 내에서 유일해야 합니다.
- 같은 이름을 가진 특성이 여러 그룹에 존재할 수 있지만, 특성 규칙이나 특성 탐지 결과에서 이들을 구별하기는 어렵습니다.
특성 – ML 모델
ML 모델로 특성을 학습시킬 때는 기본적으로 n-그램 모델이 사용됩니다. n-그램은 모델 학습을 위해 학습 문장에서 사용하는 연속적인 단어 시퀀스입니다. 그러나 이는 말뭉치가 매우 적거나, 학습 문장에 더 적은 수의 단어가 포함되어 있는 경우, 일반적으로는, 효과적이지 않을 수 있습니다. 플랫폼 v8.0부터 n-그램 모델을 건너뛰거나 사용할 수 있는 옵션이 포함되어 있습니다. 또한 n-그램 알고리즘을 매개 변수화하는 옵션이 포함되어 있습니다.
- n-그램 옵션을 선택하면, n-그램의 최대값을 설정하여 n-그램 시퀀스 길이를 구성할 수 있습니다. 기본적으로 1로 설정되며 1에서 5 사이의 정수 값으로 설정할 수 있습니다.
- 스킵-그램을 선택하면 다음을 설정할 수 있습니다.
- 비연속 시퀀스에 포함될 단어 수를 지정하는 시퀀스 길이. 기본적으로 2로 설정되며 2에서 4 사이의 정수 값을 가질 수 있습니다.
- 연속하지 않은 단어 시퀀스를 형성하기 위해 건너뛸 수 있는 단어 수의 최대 스킵 거리입니다. 기본적으로 1로 설정되며 1에서 3 사이의 정수 값을 가질 수 있습니다.
참고: 설정은 모든 언어(다국어 봇의 경우)에 대해 같지만 중국어 및 한국어와 같은 일부 언어의 경우 문자 시퀀스는 그램을 형성하고 기타(라틴 기반) 언어의 경우에는 단어 그램입니다.
특성 연관 규칙
특성 규칙은 대화 실행 및 지식 그래프 의도 탐지를 정의합니다.
대화 실행
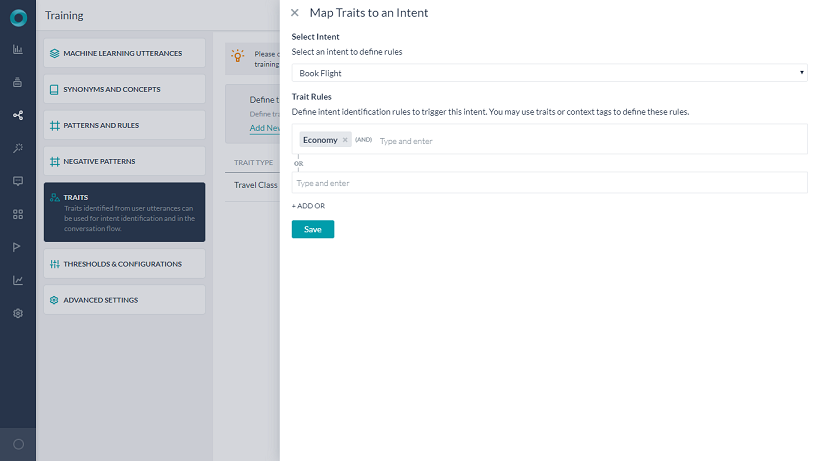
ML 발화 및 패턴과 함께 특성을 사용하여 의도 탐지 또는 대화 실행을 수행합니다. 이를 달성하려면, 규칙을 추가하여 의도가 필수 특성과 연결되어야 합니다. 규칙을 추가하는 방법에는 여러 가지가 있습니다.
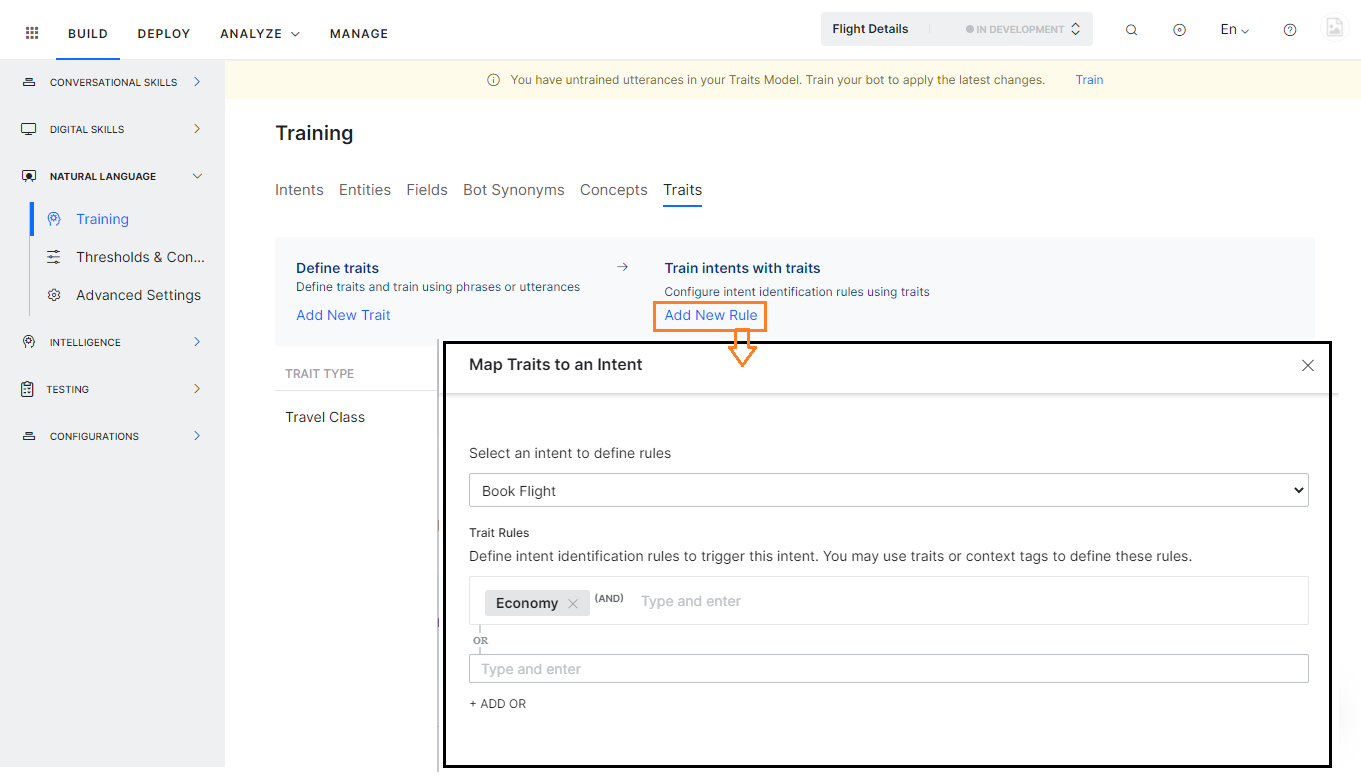
- 새 규칙 추가 링크를 통해 특성 섹션에서.
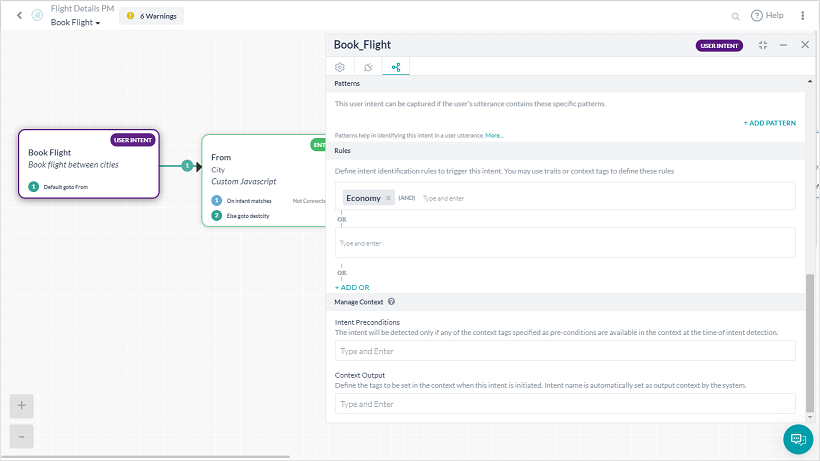
- NLP 속성의 규칙 섹션을 통해 의도 노드에서.
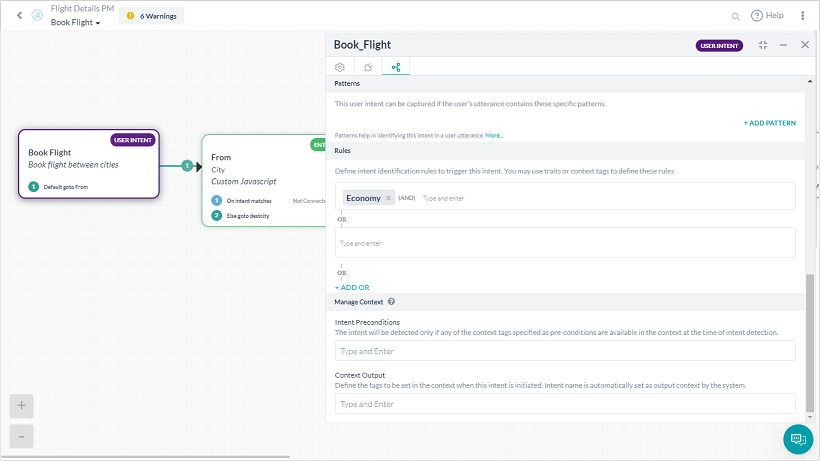
- 주어진 의도의 규칙 탭을 통해.

각 규칙에는 AND를 연산자로 사용하는 하나 이상의 조건이 있을 수 있습니다. 주어진 의도에 여러 특성 규칙을 정의할 수 있으며 규칙 중 하나라도 일치하는 경우 의도를 확실한 일치로 간주합니다.
지식 그래프 의도
지식 그래프 특성을 통한 발견 프로세스의 일부가 될 수도 있습니다. 이를 위해 각 용어 또는 노드는 특성과 연관시킬 수도 있습니다. 주어진 용어를 단일 특성과 연관시킬 수도 있습니다. 
특성 탐지
그룹(특성 유형)에서 하나의 특성만 탐지하고 확실한 일치로 간주합니다. 탐지된 특성은 컨텍스트 개체에 포함됩니다. 식별된 하나뿐인 특성으로 컨텍스트를 채웁니다(특성 유형 참조 없이). 다음에서 이 정보를 사용할 수 있습니다.
- 의도 식별
- 대화 전환
- 엔티티 채우기
- 봇 정의
배치 테스트 보고서에는 의도 API 찾기처럼 탐지된 특성에 대한 정보도 포함됩니다.
의도 감지
순위 및 해결은 3개의 NL 엔진 및 속성에서 입력한 내용을 통해 가능한/확실한 매치를 분석하고 생각해 냅니다.
- 특성 규칙에 있는 모든 특성(지식 그래프의 경우 하나)이 탐지되는 경우에만 의도를 확실한 일치로 간주합니다.
- NL 검색은 탐지된 특성에 대한 정보를 포함하고 NLP 흐름은 탐지된 특성에 대한 정보를 보여줍니다.

대화 전환
특성을 사용하여 대화 흐름을 제어합니다. 대화의 경우, 연결 규칙은 특성 컨텍스트를 사용하여 정의합니다. 대화의 속성 패널에 있는 연결 탭에서 이 작업을 수행합니다. 특성 컨텍스트는 context.traits를 사용하여 액세스합니다. 의도와 일치하는 모든 특성의 배열을 반환하므로 contains 조건이 사용됩니다. ![]()
自然な会話では、ユーザーが特定のシナリオについて説明しながら、背景や関連する情報を提供することがよくあります。特性は、ユーザーが会話の中で表現する特定のエンティティ、属性、または詳細を指します。発話は、特定のインテントを直接伝えるものではないかもしれませんが、発話に存在する特性は、インテント検出やBotの会話フローを動作させるために使用することができます。
例えば、「my card is being rejected and am on a business trip」という発話は、「card decline」と「emergency」という2つの特性を表現しています。このシナリオでは、発話は、直接的な意図を伝えていない、あるいはせいぜい「unblock card」フローを動作させるために使用することができます。一方で、「emergency」の特性は、会話を人間のエージェントに直接割り当てるために使用することができます。
Botプラットフォームの特性の機能は、ユーザーの発話に存在するこれらの特徴を識別し、それらをインテント検出に使用して、特徴を使用してBotの定義をカスタマイズすることを目的としています。
ユースケース
Book a FlightBotは、選択した金額に基づいてフライトを予約するための追加要件が備わっている場合があります。
「I am looking for low-cost option to London」というユーザーの発話は、利用可能なフライトを選択し、最低価格のチケットを選ぶ結果が予想されます。
以下のように設定します。
- 「low cost」という発話でトレーニングされた特性エコノミーを使用して「Travel Class」と呼ばれる特性タイプを追加します。
- エコノミー特性の存在によってトリガーされる「book flight」というルールを追加します。
- コンテキストに特性エコノミーが存在する場合の転送条件を追加します。
設定
特性の設定には以下が含まれます。
- 特性の定義
- 特性の相関ルール
- 特性の検出
特性の定義
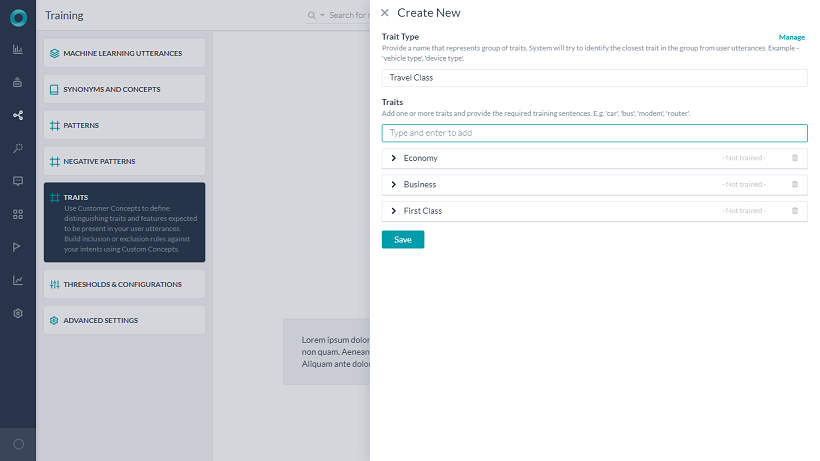
特性は、自然言語 > トレーニングの特性セクションから定義することができます。
![]()
特性を定義する際に考慮すべき主な特徴は以下の通りです。
- 特性タイプは、上記の例のTravel Classのような関連する特性の集まりです。
- 特性タイプは、「MLベース」または「パターンベース」にすることが可能です。特性タイプの各特性は、そのタイプに基づいて、単語、フレーズ、発話、またはパターンを使用してトレーニングすることができます。特性タイプの管理では、トレーニングの設定を定義することができます。MLベースの特性の設定については、以下を参照してください。

- 特性タイプは、1つ以上の特性を持つことができます。
- 特性の名前はグループ内で一意のものでなければなりません。しかし、同一の名前をもつ特性は複数のグループに存在する場合があります。
- MLベースの特性については、特性を識別する単語、フレーズ、または発話を定義することができます。MLベースの特性タイプでは、特性タイプごとに1つの特性が検出されます。
- パターンベースの特性では、与えられた特性に関連するパターンを定義することができます。パターンベースの特性タイプでは、複数の特性が検出される可能性があります。特性タイプ内の特性の順序は、特性タイプ内の特性の重要性を示し、1つの特性のみを検出します。
- 追加したら、ユーザーの発話から特性を検出するためにBotをトレーニングします。
注:
- 複数言語のBotの場合、言語固有の特性を追加することができます。
- 特性名が変更された場合は、その特性を使用して定義されたすべてのルールが修正されていることを確認してください。この処理は手動で行う必要があり、プラットフォームでは行われません。
- 特性名はグループ内で一意のものでなければなりません。
- 同一の名前をもつ特性は、複数のグループに存在する可能性がありますが、特性ルールまたは特性検出結果でそれらを区別することは困難です。
特性 – MLモデル
MLモデルを用いて特性をトレーニングすることを選択する場合、デフォルトではn-gramモデルが用いられます。n-gramとは、トレーニング文の中からモデルをトレーニングするために用いる単語の連続した配列のことです。ただし、コーパスが非常に少ない場合や、一般にトレーニング文に含まれる単語が少ない場合、これは効果的ではない可能性があります。
プラットフォームのバージョン8.0から、n-gramモデルをスキップまたは使用するオプションが含まれています。さらに、「n-gram」アルゴリズムをパラメータ化するオプションが含まれています。
- n-gramオプションを選択した場合、n-gramの最大値を設定することで、n-gramのシーケンス長を設定することができます。デフォルトでは1に設定されており、1~5の任意の整数値を設定することができます。
- When skip-gram is selected, you can configure
- 連続しないシーケンスに含まれる単語の数を指定シーケンス長です。デフォルトでは2に設定されており、2~4の任意の整数値を設定することができます。
- 連続しない単語のシーケンスを形成するためにスキップできる単語数の最大スキップ距離です。この値はデフォルトでは1に設定されており、1~3の任意の整数値を設定することができます。
注:設定はすべての言語で共通しています(多言語Botの場合)が、中国語や韓国語のように、いくつかの言語では文字列がgramを作り、その他の(ラテン語ベースの)言語では単語のgramになります。
特性の相関ルール
特性ルールは、ダイアログの実行およびナレッジグラフのインテント検出を定義します。
ダイアログの実行
インテントの検出やダイアログの実行は、MLの発話やパターンと一緒に特性を利用して行うことができます。これらを行うには、ルールを追加して、インテントと必要な特性との関連付けを行う必要があります。
ルールの追加には複数の方法があります。
- 特性セクションから新しいルールの追加リンクを使用する
- インテントノードからNLPプロパティのルールセクションを使用する
- パターンとルールセクションから与えられたインテントのルールタブを使用する
それぞれのルールは、演算子としてANDを使用して1つ以上の条件を設定することができます。与えられたインテントに対して複数の特性ルールを定義することができ、いずれかのルールが一致した場合、そのインテントは完全一致とみなされます。
ナレッジグラフインテント
ナレッジグラフは、特性を使用して検出プロセスの一部を担うことができます。そのために、それぞれの用語またはノードを一つの特性に関連付けることができます。与えられた用語は、単一の特性に関連付けることができます。
注:特性は、リリース6.4以前のクラスに置き換わります。
特性の検出
グループ(特性タイプ)から1つの特性のみが検出され、「完全一致」とみなされます。
検出された特性はコンテキストオブジェクトに含まれます。コンテキストには、(特性タイプを参照することなく)識別された固有の特性が入力されます。この情報は以下のために使用されます。
- インテントの識別
- ダイアログの遷移
- エンティティの追加
- Botの定義
バッチテストレポートには、インテントAPIの検出と同様に、検出された特性に関する情報も含まれています。.
インテントの検出
ランキングおよび解決は、3つのNLエンジンと特性からの入力を取得し、分析し、可能性のある一致/完全一致を検出します。
- インテントは、特性ルールに存在するすべての特性(ナレッジグラフの場合は1つ)が検出された場合にのみ、「完全一致」とみなされます。
- NL分析では、検出された特性に関する情報が含まれ、NLPフローでは、検出された特性に関する情報が表示されます。
ダイアログの遷移
会話フローは特性を使用して制御することができます。ダイアログの場合、接続ルール は特性コンテキストを使用して定義することができます。これは、ダイアログのプロパティパネルの下にある接続タブから行うことができます。
特性コンテキストにはcontext.tritsを使用してアクセスすることができます。これは、インテントと一致するすべての特性の配列を返すため、使用する条件は contains となります。
![]()
ドキュメントのバージョン履歴
| 更新 日 |
プラットフォームの バージョン |
変更 |
|---|---|---|
| 2020年10月31日 | バージョン8.0 | 特性のトレーニングのためにn-gramのMLモデルを使用するかスキップするかのオプション |
| 2019年6月15日 | バージョン7.0 | プラットフォームに特性を導入 |
In natural conversations, it is very common that a user provides background/relevant information while describing a specific scenario. Traits are specific entities, attributes, or details that the users express in their conversations. The utterance may not directly convey any specific intent, but the traits present in the utterance are used in driving the intent detection and bot conversation flows.
For example, the utterance my card is being rejected and am on a business trip expresses two traits card decline and emergency. In this scenario, the utterance does not convey any direct intent, or at best it is used to trigger the unblock card flow. However, the presence of emergency trait is used to directly assign the conversation to a human agent.
Traits feature of the Bots platform is aimed at identifying such characteristics present in user utterances and use them for intent detection and in customizing the bot definition using these characteristics.
Use Case
Book a Flight bot might have an added requirement to book a flight based on the cost preference.
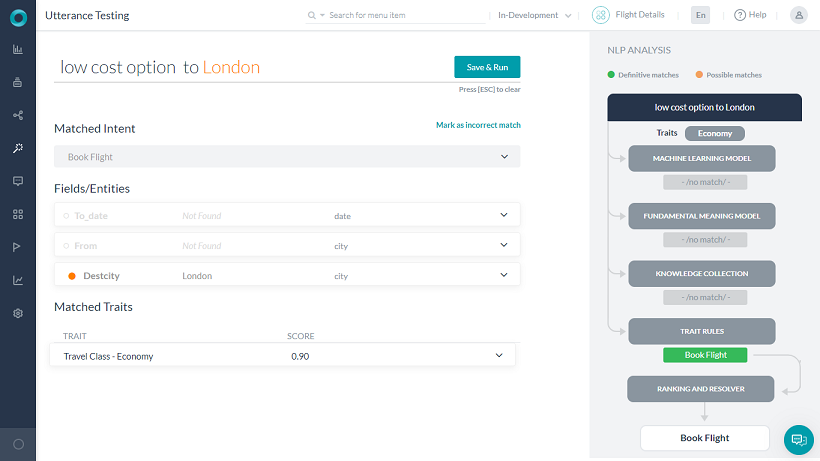
User utterance: I am looking for a low-cost option to London must result in ordering the available flights and picking the lowest-priced ticket.
This can be achieved by:
- Adding a Trait Type called Travel Class with Trait Economy trained with the utterance low cost.
- Adding a Rule for book flight to be triggered in the presence of Economy Trait.
- Add transition condition in case Trait Economy is present in the context.
Configuration
Configuring Traits involves:
- Trait Definition
- Trait Association Rules
- Trait Detection
Trait Definition
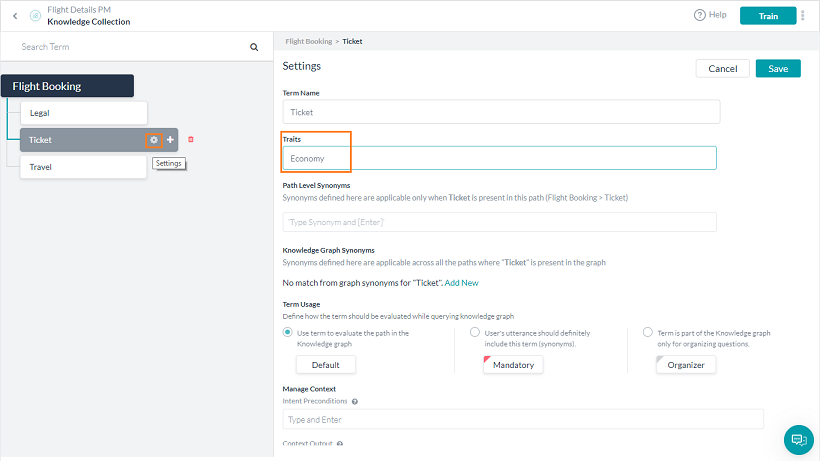
To define Traits, under the Build top menu option, from the left menu, click Natural Language –> Training and select the Traits tab.
Following are the key features to be considered while defining Traits:
- Trait Type is a collection of related traits like Travel Class in the above example.
- Trait Type can be ML Based or Pattern Based. Each trait of a trait type can be trained using words, phrases, utterances, or patterns based on the type. Manage Trait Type allows you to define the training configuration. See below for ML-based trait configuration.
- A Trait Type can have one or more Traits.
- Traits names should be unique in a group. But traits with the same name can be present in multiple groups.
- For ML-based Traits, you can define the words, phrases, or utterances that identify the trait. One trait per trait type is detected for ML-based trait types.
- For Pattern-based Traits, you can define the patterns associated with the given trait. There is a possibility of multiple traits getting detected for pattern-based trait types. Ordering of Traits within the Trait Type signifies the importance of a trait in a trait type and detects only one trait.
- Once added, Train the bot for the Traits to be detected from user utterances.
Notes:
- You can add language-specific traits in the case of multi-lingual bots.
- When a trait name is modified, ensure that all the rules defined using that trait are corrected. This has to be done manually, the platform will not take care of it.
- The trait name must be unique in a group.
- Traits with the same name can be present in multiple groups, but distinguishing them in trait rules or trait detection results is difficult.
Traits – ML Model
When choosing to train traits using the ML model, by default, the n-gram model is used. An n-gram is the contiguous sequence of words used from training sentences to train the model. But this might not be effective when the corpus is very less or when the training sentences, in general, contain fewer words.
From v8.0 of the platform, an option is included to skip or use the n-gram model. Further, the option to parameterize the n-gram algorithm is included.
- When the n-gram option is selected, you can configure the n-gram Sequence Length by setting the maximum value of the n-gram. It is set to 1 by default and can be configured to any integer value between 1 and 5.
- When skip-gram is selected, you can configure
- Sequence Length specifying the number of words to be included in a non-consecutive sequence. It is set to 2 by default and it can take any integer value between 2 and 4.
- Maximum Skip Distance for the number of words that can be skipped to form a non-consecutive sequence of words. This value is set to 1 by default and can take any integer value from 1 to 3.
NOTE: While the settings are same for all languages (in case of multilingual bot), for some languages like Chinese and Korean sequence of characters form grams and for other (Latin-based) languages are word grams.
Trait Association Rules
Trait Rules define Dialog Execution and Knowledge Graph Intent detection.
Dialog Execution
Intent detection or Dialog execution is achieved using traits, along with the ML utterances and patterns. To achieve this, intent must be associated with the required traits by adding Rules.
There are multiple ways to add rules:
- From the Traits section using the Add New Rule link.
- From the Intent Node using the Rules section under the NLP Properties.
- From the Rules tab for a given Intent.
Each rule can have one or more conditions with AND as the operator. Multiple trait rules can be defined for a given intent and the intent is considered as a definite match if any one of the rules matches.
Knowledge Graph Intents
Knowledge Graph can also be part of the discovery process using Traits. For this, each term or node can be associated with a trait. A given term can be associated with a single Trait.
Trait Detection
Only one trait from a group (trait type) will be detected and is considered as a definite match.
Traits detected are included in the context object. The context is populated with unique traits identified (without reference to trait type). This information can be used in:
- Intent identification
- Dialog transition
- Entity population
- bot definitions
Batch Testing reports also include information about traits detected as do the Find Intent API.
Intent Detection
The Ranking and Resolver gets input from the three NL engines and Traits to analyze and come up with the possible/definitive matches.
- The intent is considered as a definite match only if all the traits (one in the case of Knowledge Graph) present in a trait rule are detected.
- NL Analysis includes information on traits detected and the NLP Flow shows the information about traits detected.
Dialog Transition
Conversation Flow is controlled using Traits. For a Dialog, Connection Rules are defined using the Trait Context. This is done from the Connection tab under the Properties Panel for the Dialog.
The Traits Context is accessed using context.traits. It returns an array of all traits matching the intent, hence the condition to be used is contains.
![]()